IndexTTS-2 是由 Bilibili IndexSpeech 團隊推出的新一代自回歸式(Auto-Regressive)零樣本文字轉語音(TTS)模型,主打「高情緒表現力」與「可控語音時長」兩大核心突破。相較於過去多數 TTS 模型只能自然生成語音卻難以精準控制長度,IndexTTS-2 提出一套全新的時長適配機制,同時支援「明確指定生成 token 數量以精準控制語音長度」,以及「自由生成、保留輸入提示韻律特徵」兩種模式,特別適合影片配音、對嘴同步與需要嚴格音畫對齊的應用場景。除此之外,IndexTTS-2 在模型設計上成功解耦「說話者音色」與「情緒表達」,能在零樣本情境下,僅透過參考聲音重建目標音色,並獨立套用指定的情緒風格,達到高度擬真且情感一致的語音生成效果,在語者相似度、情緒忠實度與辨識錯誤率等指標上,皆優於目前主流的零樣本 TTS 模型。
在實際使用層面,IndexTTS-2 不僅是一個研究模型,更是一套可完整本地部署的專業語音合成工具。使用者可以在本機透過 NVIDIA GPU 進行推論,無需依賴雲端服務,兼顧隱私性與效能穩定度。模型同時支援多種情緒控制方式,包含使用情緒參考音檔、直接指定情緒向量,甚至透過自然語言描述情緒來引導生成,大幅降低非專業使用者的操作門檻。官方亦提供 WebUI 介面,讓使用者能以瀏覽器方式進行文字轉語音、聲音模仿與參數調整,非常適合初學者、內容創作者與開發者快速上手。本教學即是以「先穩定跑起來」為核心,示範如何在 Windows 環境中完成 IndexTTS-2 的本地部署與 WebUI 啟動,協助你將這套先進的語音生成技術真正落地使用。

IndexTTS-2 WebUI 完整安裝流程
這邊預設您已經擁有一台裝有 NVIDIA GPU 的電腦,並運行 Windows 作業系統,另外請確保已安裝最新版 NVIDIA 顯示卡驅動。
一、系統前置準備
接著請安裝 Python,建議版本為 3.10 或 3.11。安裝時請務必勾選「Add Python to PATH」,以免後續指令無法使用。安裝完成後,在終端機(CMD)輸入 python --version,確認版本能正常顯示即可。最後需要安裝 Git,用於下載專案。安裝完成後,請在終端機驗證 git --version。
二、下載 IndexTTS 專案
在你想存放專案的資料夾中,使用終端機執行專案下載指令,接著進入專案目錄並拉取 Git LFS 檔案。
git clone https://github.com/index-tts/index-tts.git
cd index-tts
git lfs pull完成後,專案目錄中應可看到 checkpoints、indextts 資料夾,以及 webui.py 與 pyproject.toml 等檔案。
三、安裝 uv(IndexTTS 官方唯一支援工具)
IndexTTS 專案不使用傳統 venv 或 conda,而是統一透過 uv 管理環境。請使用 Python 直接安裝 uv。
python -m pip install -U uv安裝完成後,可輸入 uv --version 確認工具可正常使用。
四、建立專案虛擬環境
在 index-tts 專案目錄中,執行 uv 的同步指令來建立虛擬環境與安裝必要套件。
uv sync --extra webui此步驟完成後,專案資料夾中會自動產生 .venv 目錄,代表環境已成功建立。
此配置刻意避開所有高風險加速套件,目的僅是確保在 Windows 上能穩定執行。
五、下載 IndexTTS-2 官方模型
模型檔案需透過 HuggingFace 官方工具下載。請先使用 uv 安裝 HuggingFace CLI。
uv tool install "huggingface-hub[cli,hf_xet]"若安裝完成後 uv 提示需要重新啟動終端機,請照做。
接著將 IndexTTS-2 模型下載至專案的 checkpoints 資料夾。
hf download IndexTeam/IndexTTS-2 --local-dir checkpoints下載完成後,checkpoints 目錄中應可看到 config.yaml 與多個模型檔案。
▲ index-tts 專案根目錄截圖,總大小約 13.5 GB。
六、啟動 IndexTTS WebUI
所有準備完成後,即可直接啟動 WebUI。
uv run webui.py程式啟動後,打開瀏覽器並前往 http://127.0.0.1:7860,即可看到 IndexTTS 的操作介面。
IndexTTS-2 WebUI 操作說明
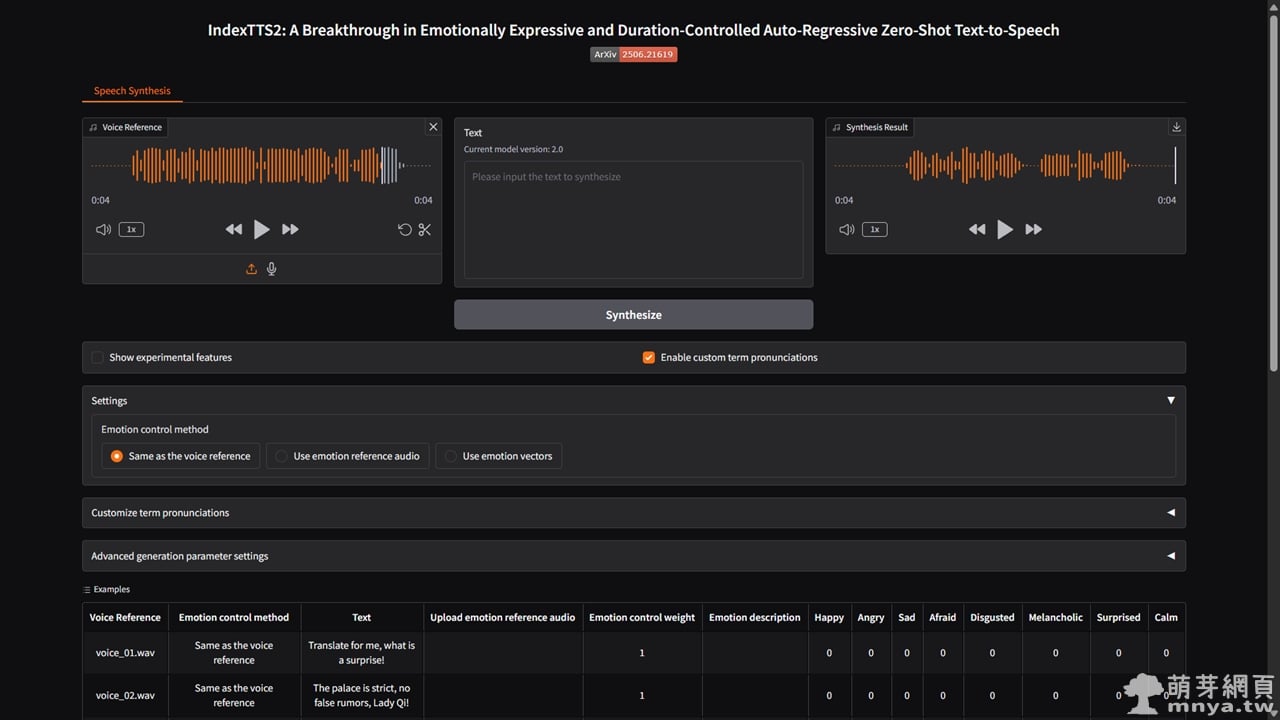
介面概覽與基本操作流程
啟動 WebUI 後,瀏覽器會開啟 IndexTTS-2 的主頁面,整體介面是以 Gradio 為基礎設計,所有操作皆集中在「Speech Synthesis」頁籤中完成。最基本的使用流程,是先在左側上傳一段「Voice Reference」作為聲音參考來源,這段音檔將決定生成語音的音色與說話者特徵。IndexTTS-2 採用零樣本語音複製設計,因此不需要事先訓練,只要一段清楚、語者單一的音檔,即可有效還原目標聲線。建議長度約為 8 秒至 15 秒,實測效果最佳。
完成聲音參考設定後,使用者只需在中間的文字輸入區輸入欲轉換的文字內容,即可進行文字轉語音,這邊如果要輸入中文,請避免使用繁體中文,請事先將文字都轉成簡體中文,避免發音出錯。點擊「Synthesize」按鈕後,模型會開始推論並在「Synthesis Result」輸出合成結果音檔,生成完成的語音可直接於頁面中播放或另行下載。若輸入文字較長,工具會自動依照內建的文字切分機制分段處理,並在「Preview of the audio generation segments」區域顯示每段文字與對應的 token 數量,方便使用者確認語音結構與生成狀態。
情緒控制、進階設定與發音自訂功能說明
在基本語音生成之外,IndexTTS-2 WebUI 提供完整的情緒控制機制。使用者可透過「Emotion control method」選擇情緒來源,包含直接沿用聲音參考的情緒、上傳額外的情緒參考音檔,或使用情緒向量進行精細控制。當選擇情緒向量模式時,下方會顯示多個情緒滑桿,如快樂、憤怒、悲傷、驚訝與冷靜等,透過調整數值即可混合出不同強度與風格的情緒表現。此外,WebUI 亦支援以自然語言描述情緒,只需在情緒描述欄位輸入如「壓抑的悲傷」或「緊張、即將發生危險的語氣」,模型便會自動解析並轉換為對應的情緒向量。
對於進階使用者,WebUI 也提供完整的生成參數調整功能,包含 GPT 取樣策略、temperature、top-p、top-k、重複懲罰與最大生成 token 數量等設定,這些參數會同時影響語音的自然度、穩定性與生成速度。若有專有名詞或特殊唸法需求,使用者可在「Customize term pronunciations」區塊中自訂詞彙對應的中英文發音,確保模型在朗讀時能維持正確與一致的讀音。


 《上一篇》【hoda 好貼】ASUS Zenfone 11 Ultra 高透光玻璃保護貼
《上一篇》【hoda 好貼】ASUS Zenfone 11 Ultra 高透光玻璃保護貼  《下一篇》ComfyUI x Crystools:在 UI 中即時顯示 CPU、RAM、GPU、VRAM 使用率與溫度
《下一篇》ComfyUI x Crystools:在 UI 中即時顯示 CPU、RAM、GPU、VRAM 使用率與溫度 








留言區 / Comments
萌芽論壇