過去曾經想到用尋找取代的方式將 SRT 字幕檔轉換為 TXT 時間軸標記(請參照舊圖文),但後來想到可以用 Python 處理這樣的人工程序,直接全自動化,還能一次處理多個檔案,這對於 YTuber 來說絕對會是很實用的小工具。
舉例來說,我有以下的 SRT 字幕檔內容(來自這部影片):
1
00:00:06,272 --> 00:00:09,776
萬大林道起點,左為親愛國小
2
00:00:28,461 --> 00:00:31,965
大窟窿!建議慢速通過
3
00:08:37,684 --> 00:08:41,187
路窄極難會車
4
00:12:14,367 --> 00:12:17,504
右土石路往富嶺山
5
00:15:31,398 --> 00:15:34,901
汽車通車終點
6
00:15:45,45 --> 00:15:50,50
感謝觀賞!Thanks for watching!經過這個小程式的轉換會輸出以下 TXT 時間軸標記:
00:00:00 片頭
00:00:06 萬大林道起點,左為親愛國小
00:00:28 大窟窿!建議慢速通過
00:08:37 路窄極難會車
00:12:14 右土石路往富嶺山
00:15:31 汽車通車終點
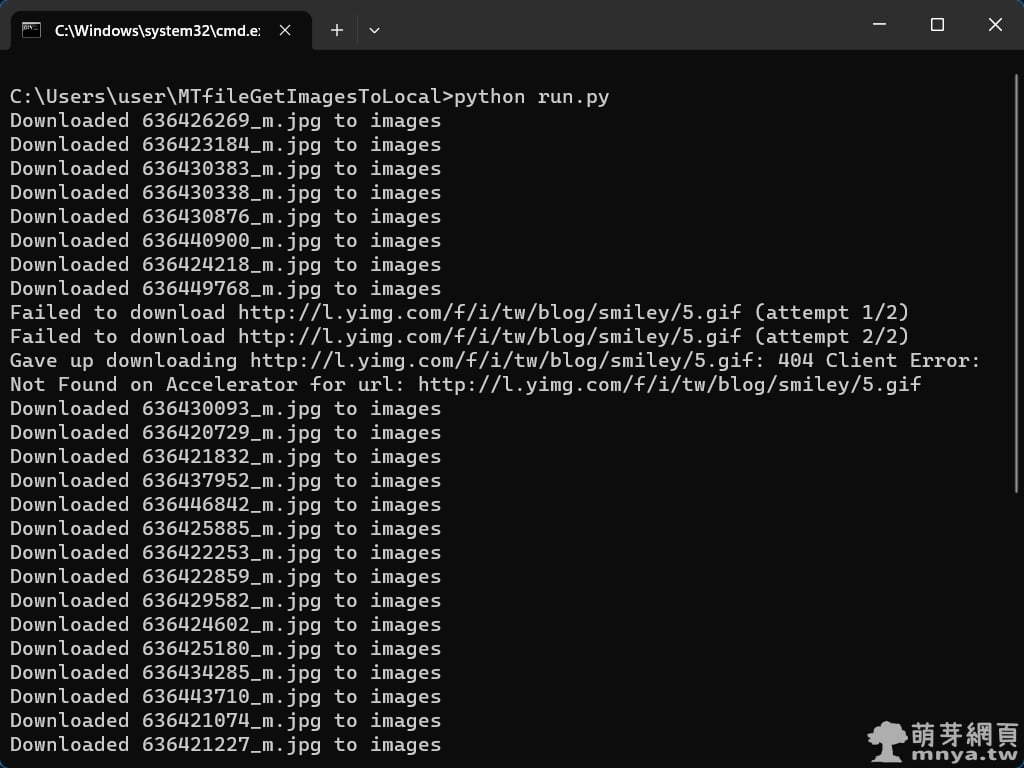
00:15:45 感謝觀賞!Thanks for watching!✅ 最終程式執行狀況如下:我先在 src 子目錄內放好要處理的 .srt 字幕檔,接著我來到專案根目錄點兩下執行 run.bat,裡面會執行 run.py(電腦要先安裝 Python),最終 build 目錄得到處理完畢的 .txt 時間軸標記,同時終端機也會輸出結果。
📄 run.bat
python run.py
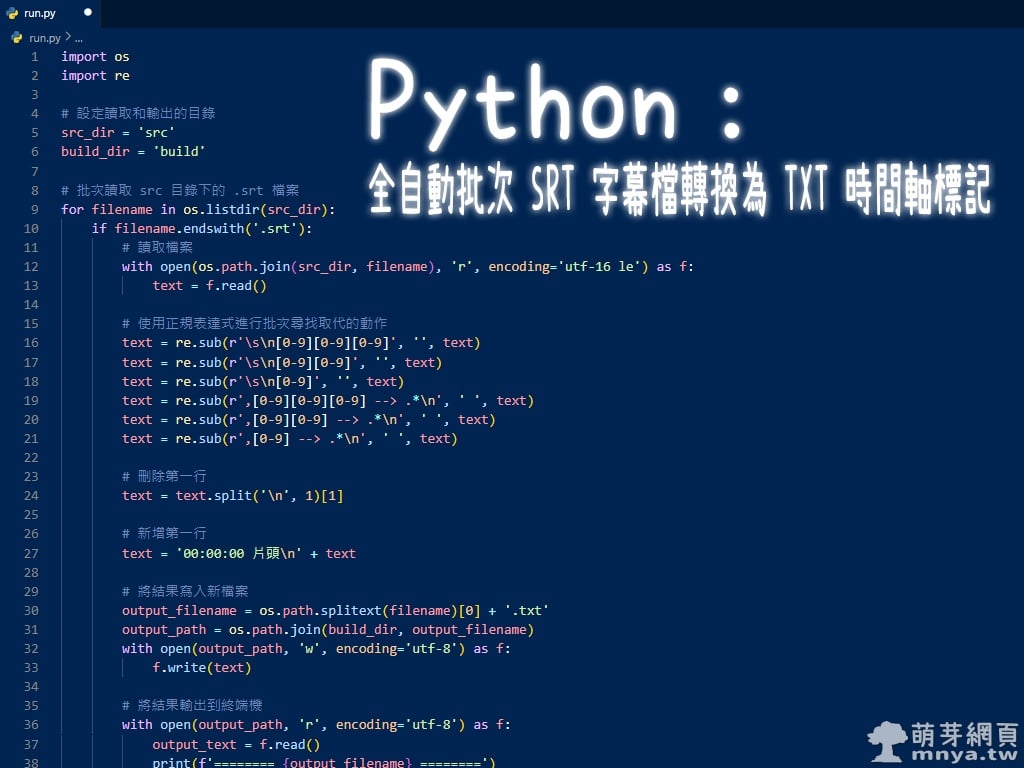
pause📄 run.py
import os
import re
# 設定讀取和輸出的目錄
src_dir = 'src'
build_dir = 'build'
# 批次讀取 src 目錄下的 .srt 檔案
for filename in os.listdir(src_dir):
if filename.endswith('.srt'):
# 讀取檔案
with open(os.path.join(src_dir, filename), 'r', encoding='utf-16 le') as f:
text = f.read()
# 使用正規表達式進行批次尋找取代的動作
text = re.sub(r'\s\n[0-9][0-9][0-9]', '', text)
text = re.sub(r'\s\n[0-9][0-9]', '', text)
text = re.sub(r'\s\n[0-9]', '', text)
text = re.sub(r',[0-9][0-9][0-9] --> .*\n', ' ', text)
text = re.sub(r',[0-9][0-9] --> .*\n', ' ', text)
text = re.sub(r',[0-9] --> .*\n', ' ', text)
# 刪除第一行
text = text.split('\n', 1)[1]
# 新增第一行
text = '00:00:00 片頭\n' + text
# 將結果寫入新檔案
output_filename = os.path.splitext(filename)[0] + '.txt'
output_path = os.path.join(build_dir, output_filename)
with open(output_path, 'w', encoding='utf-8') as f:
f.write(text)
# 將結果輸出到終端機
with open(output_path, 'r', encoding='utf-8') as f:
output_text = f.read()
print(f'======== {output_filename} ========')
print(output_text)解釋:
1. 匯入需要的模組:os 和 re。
2. 設定要讀取和輸出的目錄。
3. 使用 os 模組的 listdir 方法批次讀取 src 目錄下的所有檔案,並使用 endswith 方法篩選出 .srt 檔案。
4. 使用 with open 語句以讀取模式打開每個 .srt 檔案。
5. 將檔案的內容讀取到 text 變數中。
6. 使用 re 模組的 sub 方法進行批次尋找和替換的動作,將字幕檔案中的時間戳記和序號刪除,將字幕文本連接成一個段落。
7. 使用 split 方法以第一個換行符為分隔符將段落分割成兩個部分,刪除第一行。
8. 在 text 變數的開頭添加一行「00:00:00 片頭」。
9. 使用 os.path 模組的 splitext 方法獲取不帶副檔名的檔名。
10. 使用 os.path 模組的 join 方法將輸出目錄和不帶副檔名的檔名結合成輸出路徑。
11. 使用 with open 語句以寫入模式打開輸出檔案,將處理過的字幕文本寫入檔案中。
12. 使用 with open 語句以讀取模式打開輸出檔案,讀取檔案的內容到 output_text 變數中。
13. 使用 print 函數將 output_text 變數中的字幕文本輸出到終端機,以便檢查處理結果。
GitHub:https://github.com/qwe987299/batch_sub2txt
▲ 示意圖。


 《上一篇》Windows:在終端機找尋占用指定 Port 的程式並強制停止它
《上一篇》Windows:在終端機找尋占用指定 Port 的程式並強制停止它 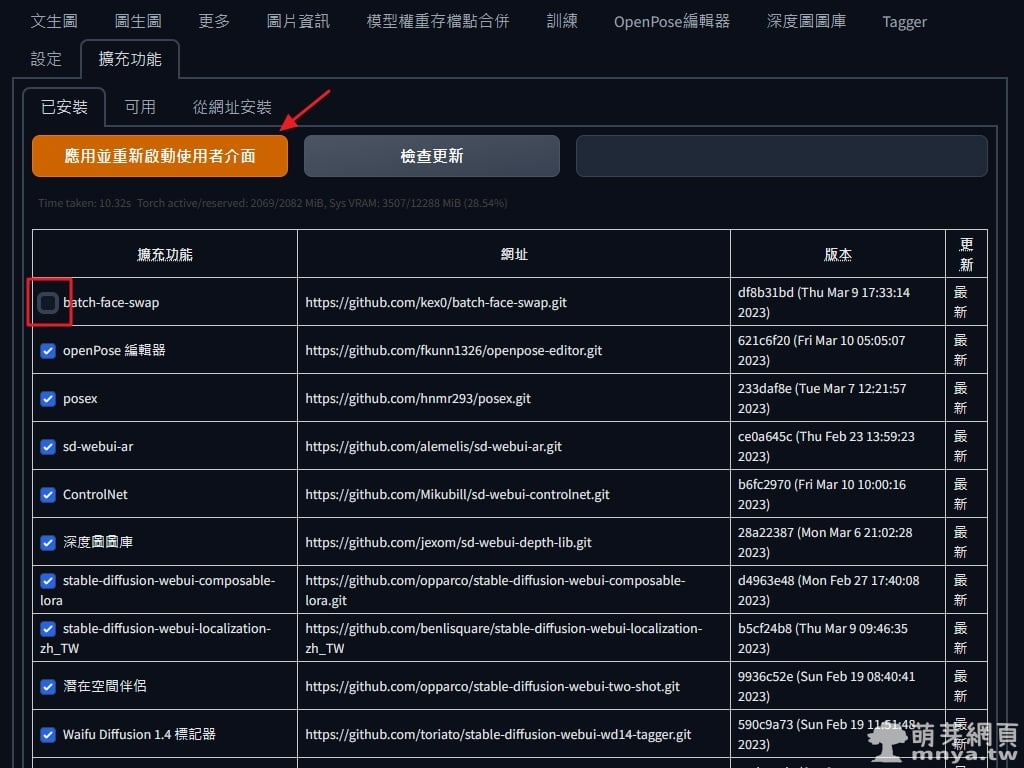 《下一篇》Stable Diffusion web UI:如何移除擴充功能(Extensions)?
《下一篇》Stable Diffusion web UI:如何移除擴充功能(Extensions)? 








留言區 / Comments
萌芽論壇