在當前生成式 AI 快速發展的浪潮中,視聽內容的自動合成技術逐漸進入主流視野。尤其是在影音創作、互動媒體以及虛擬實境等應用領域,從影片或文字中生成自然同步的音訊,已成為一項令人矚目的突破。「MMAudio Web UI」正是為此而誕生的輕量化操作介面,讓使用者能夠便捷地體驗 MMAudio 所帶來的創作新可能,無需深入程式碼層面,也能快速上手進行影片轉音訊或文字轉音訊的創作流程。
MMAudio 本身是一個由伊利諾大學香檳分校與 Sony AI 共同研發的多模態音訊生成模型,在 CVPR 2025 上發表。它能根據影片畫面或文字輸入,產生高度同步且自然的音效,背後的關鍵技術在於多模態聯合訓練與時序對齊模組,使模型得以從各種音訊-視覺或音訊-文字資料集中學習並準確生成對應的聲音。而「MMAudio Web UI」則進一步將這套技術包裝成圖形介面,透過簡易的設定與操作,讓創作者不再受限於深奧的模型訓練流程,而是專注於創意表達本身。

接下來我將會逐步引導你完成 MMAudio Web UI 的安裝與使用,從啟動介面、載入影片或輸入文字、到最終匯出生成音訊,搭配操作截圖,一步步拆解其核心功能與細節。這不僅是技術教學,更是一次探索 AI 聲音創作潛力的旅程。
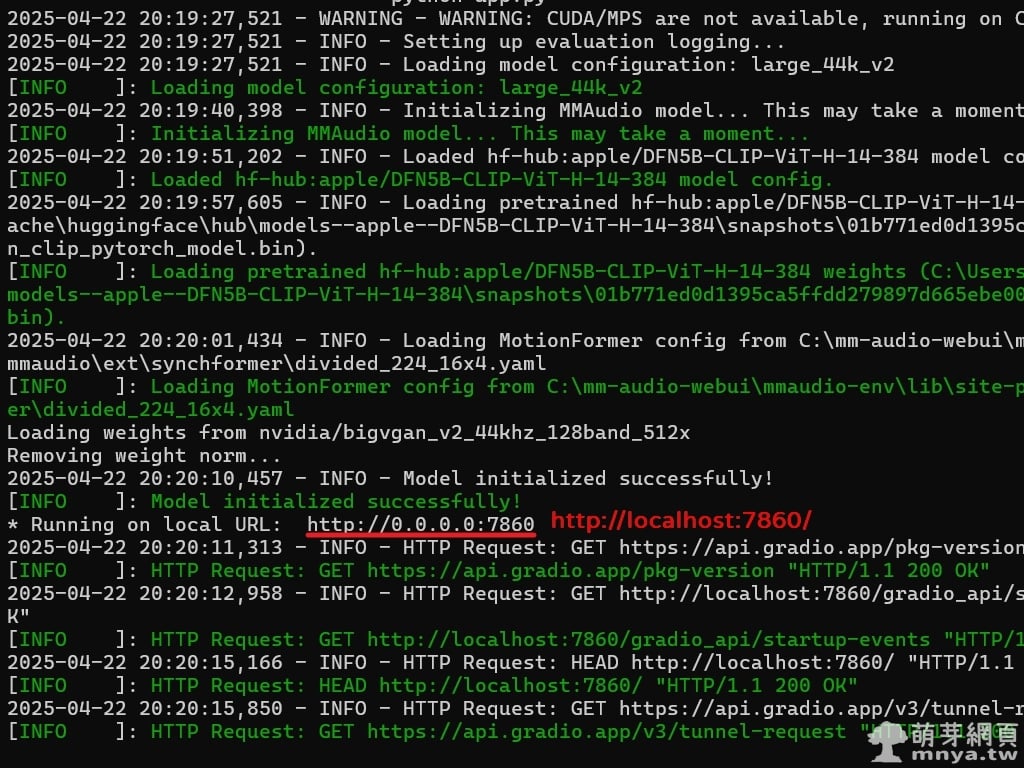
▲ 首先,在 Windows 環境下請先透過 Git 將專案複製至本機,可在終端機使用指令 git clone https://github.com/vpakarinen/mm-audio-webui.git 進行下載。完成後,請進入專案資料夾 cd mm-audio-webui。接著,使用 Python 建立虛擬環境以隔離安裝套件,輸入指令 python -m venv mmaudio-env 建立名為 mmaudio-env 的虛擬環境。完成後,請啟用該環境,在 Windows 平台上請執行 .\mmaudio-env\Scripts\activate。虛擬環境啟用後,請安裝專案所需的相依套件,透過 pip install -r requirements.txt 指令依據 requirements.txt 檔案進行安裝。當所有套件安裝完畢,即可透過 python app.py 執行應用程式,啟動 mm-audio-webui,首次啟動會自動安裝需要的模型檔案等,啟動成功即可透過瀏覽器輸入 http://localhost:7860/ 進入介面。
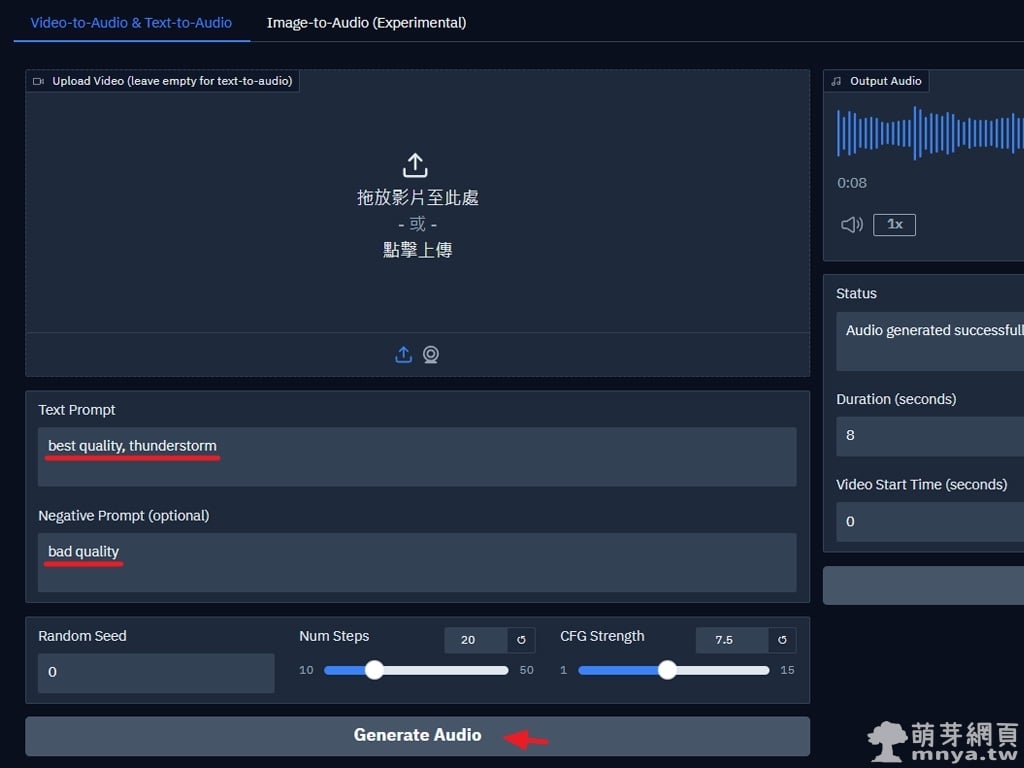
▲ 在輸入框中填入提示詞與負面提示詞,調整步數與 CFG 強度後,點擊「Generate Audio」開始產生音效。Video-to-Audio 模式可上傳影片並搭配提示詞,Text-to-Audio 模式則留空影片欄位僅填提示詞,Image-to-Audio(實驗性)可上傳圖片並搭配文字生成音效。注意:解析度高於 384px(短邊)會明顯拖慢處理速度,且無助於結果品質;建議影片長度為 5~12 秒,過長或過短都會影響效果。實際使用下來,Text-to-Audio 模式比較快速且實用。
💡範例正面提示詞:best quality, thunderstorm
💡範例負面提示詞:bad quality
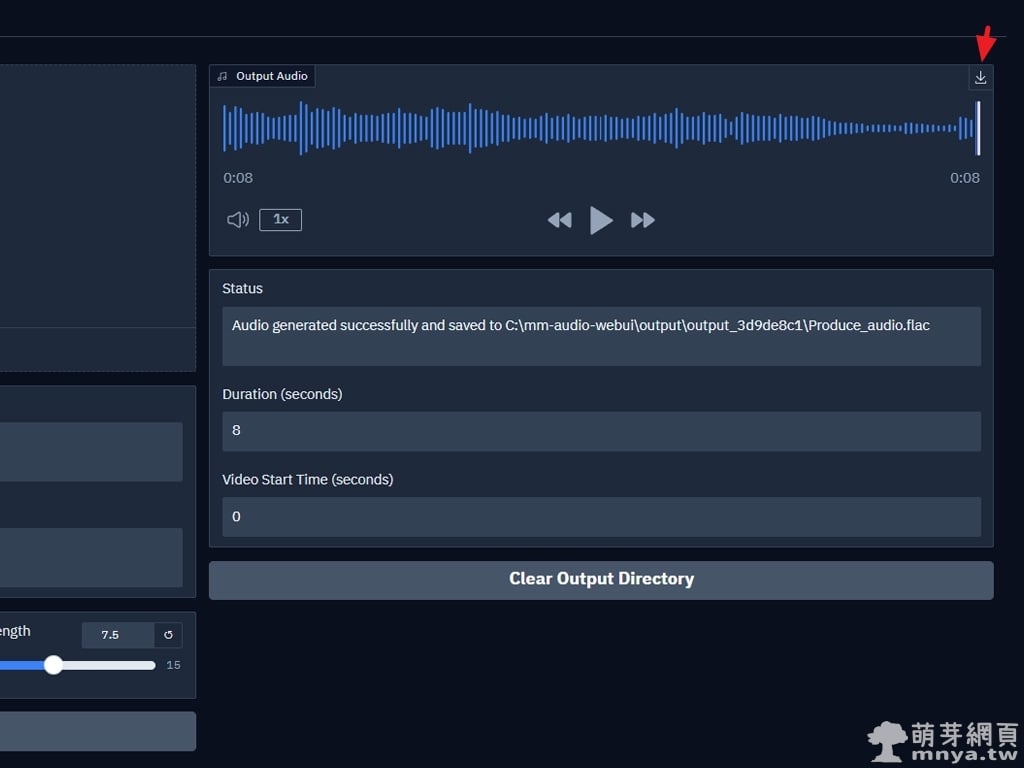
▲ 音效生成完成後,可在右側預覽音訊波形,並點擊右上角的下載按鈕儲存 FLAC 檔。
示範影片
▲ 影片欣賞《【MMAudio】音效產生示範影片:暴風雨下被洪水沖走的少女 (1)》
▲ 影片欣賞《【MMAudio】音效產生示範影片:暴風雨下被洪水沖走的少女 (2)》
▲ 影片欣賞《【MMAudio】音效產生示範影片:暴風雨下被洪水沖走的少女 (3)》
▲ 影片欣賞《【MMAudio】音效產生示範影片:暴風雨下被洪水沖走的少女 (4)》
※ 備註:以上影片皆使用同一次生成的音效。
MMAudio Web UI 提供了一個極為直覺的操作介面,讓使用者可以輕鬆從影片或文字生成對應的音效。無需撰寫任何程式碼,只需透過簡單的提示詞設定、調整參數,並點擊「Generate Audio」按鈕,即可完成整個音訊生成流程。不論是針對特定場景如「雷雨聲」的擬音,或是創作情境下的音效輔助,都能透過這套工具快速實現。生成完成後亦可直接預覽並下載高品質音訊檔,整體流程順暢且高效率,非常適合影音創作者、遊戲開發者或教育展示用途使用。透過 MMAudio Web UI,即便沒有深厚的 AI 技術背景,也能立刻進入 AI 音效創作的世界。


 《上一篇》【貼圖】網路與伺服器(Network and Server)
《上一篇》【貼圖】網路與伺服器(Network and Server)  《下一篇》FramePack:開源圖生影 AI 工具,低門檻打造高品質影片的革命性實測
《下一篇》FramePack:開源圖生影 AI 工具,低門檻打造高品質影片的革命性實測 








留言區 / Comments
萌芽論壇