Stable Diffusion web UI 在一次的更新中移除預設的語言包,原因是似乎缺乏後續維護,這當中也包含了正體中文(繁體中文)語言包 zh_TW.json,因此使用者需要從網路上另尋資源並下載,放入軟體根目錄下的 localizations 目錄中。本文提供簡易教學及站長在最後一次 pull 軟體時拿到的語言包全文供大家運用。
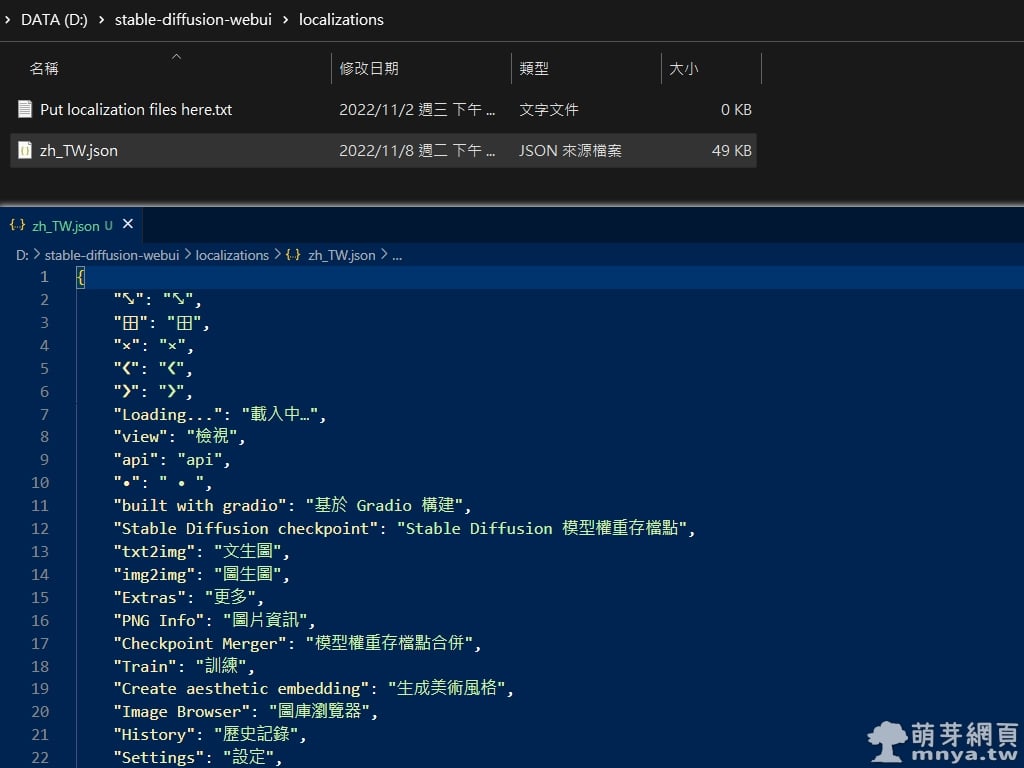
▲ 將本文文末提供的語言包文字存成 zh_TW.json 並放入軟體根目錄下的 localizations 目錄中。
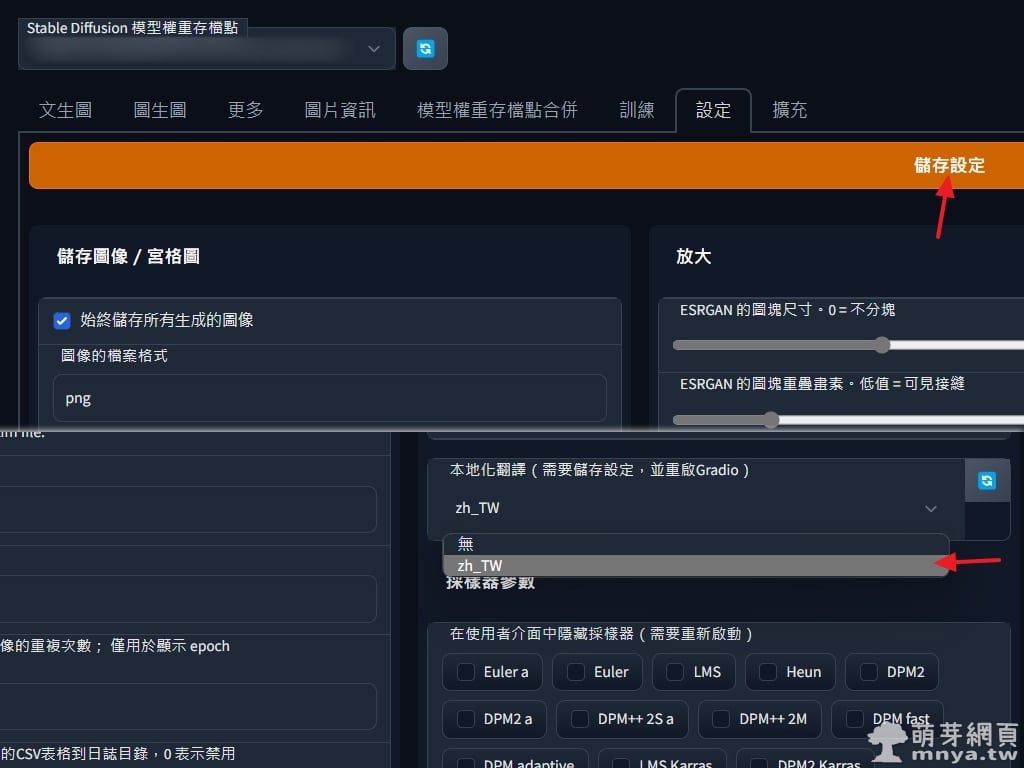
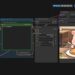
▲ 在「設定」中可以找到「本地化翻譯」,在這邊選取「zh_TW」並重新啟動軟體,中文化即可生效!
zh_TW.json 語言包全文提供
※ 來自最後一次的 pull 更新。
{
"⤡": "⤡",
"⊞": "⊞",
"×": "×",
"❮": "❮",
"❯": "❯",
"Loading...": "載入中…",
"view": "檢視",
"api": "api",
"•": " • ",
"built with gradio": "基於 Gradio 構建",
"Stable Diffusion checkpoint": "Stable Diffusion 模型權重存檔點",
"txt2img": "文生圖",
"img2img": "圖生圖",
"Extras": "更多",
"PNG Info": "圖片資訊",
"Checkpoint Merger": "模型權重存檔點合併",
"Train": "訓練",
"Create aesthetic embedding": "生成美術風格",
"Image Browser": "圖庫瀏覽器",
"History": "歷史記錄",
"Settings": "設定",
"Extensions": "擴充",
"Prompt": "提示詞",
"Negative prompt": "反向提示詞",
"Run": "執行",
"Skip": "跳過",
"Interrupt": "中止",
"Generate": "生成",
"Style 1": "模版風格 1",
"Style 2": "模版風格 2",
"Label": "標記",
"File": "檔案",
"Drop File Here": "拖曳檔案到此",
"-": "-",
"or": "或",
"Click to Upload": "點擊上傳",
"Image": "圖像",
"Check progress": "檢視進度",
"Check progress (first)": "(首次)檢視進度",
"Sampling Steps": "採樣疊代步數",
"Sampling method": "採樣方法",
"Euler a": "Euler a",
"Euler": "Euler",
"LMS": "LMS",
"Heun": "Heun",
"DPM2": "DPM2",
"DPM2 a": "DPM2 a",
"DPM fast": "DPM fast",
"DPM adaptive": "DPM adaptive",
"LMS Karras": "LMS Karras",
"DPM2 Karras": "DPM2 Karras",
"DPM2 a Karras": "DPM2 a Karras",
"DDIM": "DDIM",
"PLMS": "PLMS",
"Width": "寬度",
"Height": "高度",
"Restore faces": "面部修復",
"Tiling": "可平鋪",
"Highres. fix": "高解析度修復",
"Firstpass width": "第一遍的寬度",
"Firstpass height": "第一遍的高度",
"Denoising strength": "重繪幅度",
"Batch count": "生成批次",
"Batch size": "每批數量",
"CFG Scale": "提示詞相關性(CFG)",
"Seed": "隨機種子",
"Extra": "▼",
"Variation seed": "差異隨機種子",
"Variation strength": "差異強度",
"Resize seed from width": "自寬度縮放隨機種子",
"Resize seed from height": "自高度縮放隨機種子",
"Open for Clip Aesthetic!": "打開以調整 Clip 的美術風格!",
"▼": "▼",
"Aesthetic weight": "美術風格權重",
"Aesthetic steps": "美術風格疊代步數",
"Aesthetic learning rate": "美術風格學習率",
"Slerp interpolation": "球面線性插值角度",
"Aesthetic imgs embedding": "美術風格圖集 embedding",
"None": "無",
"Aesthetic text for imgs": "該圖集的美術風格描述",
"Slerp angle": "Slerp 角度",
"Is negative text": "是反向提示詞",
"Script": "指令碼",
"Embedding to Shareable PNG": "將 Embedding 轉換為可分享的 PNG 圖片檔案",
"Prompt matrix": "提示詞矩陣",
"Prompts from file or textbox": "從文字方塊或檔案載入提示詞",
"X/Y plot": "X/Y 圖表",
"Source embedding to convert": "用於轉換的源 Embedding",
"Embedding token": "Embedding 的關鍵詞",
"Put variable parts at start of prompt": "把變量部分放在提示詞文本的開頭",
"Show Textbox": "顯示文字方塊",
"File with inputs": "含輸入內容的檔案",
"Prompts": "提示詞",
"Iterate seed every line": "每行輸入都換一個種子",
"Use same random seed for all lines": "每行輸入都使用同一個隨機種子",
"List of prompt inputs": "提示詞輸入列表",
"Upload prompt inputs": "上傳提示詞輸入檔案",
"X type": "X軸類型",
"Nothing": "無",
"Var. seed": "差異隨機種子",
"Var. strength": "差異強度",
"Steps": "疊代步數",
"Prompt S/R": "提示詞替換",
"Prompt order": "提示詞順序",
"Sampler": "採樣器",
"Checkpoint name": "模型權重存檔點的名稱",
"Hypernetwork": "超網路(Hypernetwork)",
"Hypernet str.": "超網路(Hypernetwork)強度",
"Sigma Churn": "Sigma Churn",
"Sigma min": "最小 Sigma",
"Sigma max": "最大 Sigma",
"Sigma noise": "Sigma noise",
"Eta": "Eta",
"Clip skip": "Clip 跳過",
"Denoising": "重繪幅度",
"Cond. Image Mask Weight": "圖像調節屏蔽度",
"X values": "X軸數值",
"Y type": "Y軸類型",
"Y values": "Y軸數值",
"Draw legend": "在圖表中包括軸標題",
"Include Separate Images": "包括獨立的圖像",
"Keep -1 for seeds": "保持隨機種子為-1",
"Drop Image Here": "拖曳圖像到此",
"Save": "儲存",
"Send to img2img": ">> 圖生圖",
"Send to inpaint": ">> 局部重繪",
"Send to extras": ">> 更多",
"Make Zip when Save?": "儲存時生成ZIP壓縮檔案?",
"Textbox": "文字方塊",
"Interrogate\nCLIP": "CLIP\n反推提示詞",
"Interrogate\nDeepBooru": "DeepBooru\n反推提示詞",
"Inpaint": "局部重繪",
"Batch img2img": "批量圖生圖",
"Image for img2img": "圖生圖的圖像",
"Image for inpainting with mask": "用於局部重繪並手動畫蒙版的圖像",
"Mask": "蒙版",
"Mask blur": "蒙版模糊",
"Mask mode": "蒙版模式",
"Draw mask": "繪製蒙版",
"Upload mask": "上傳蒙版",
"Masking mode": "蒙版模式",
"Inpaint masked": "重繪蒙版內容",
"Inpaint not masked": "重繪非蒙版內容",
"Masked content": "蒙版蒙住的內容",
"fill": "填充",
"original": "原圖",
"latent noise": "潛空間噪聲",
"latent nothing": "潛空間數值零",
"Inpaint at full resolution": "全解析度局部重繪",
"Inpaint at full resolution padding, pixels": "預留畫素",
"Process images in a directory on the same machine where the server is running.": "使用伺服器主機上的一個目錄,作為輸入目錄處理圖像",
"Use an empty output directory to save pictures normally instead of writing to the output directory.": "使用一個空的資料夾作為輸出目錄,而不是使用預設的 output 資料夾作為輸出目錄",
"Disabled when launched with --hide-ui-dir-config.": "啟動 --hide-ui-dir-config 時禁用",
"Input directory": "輸入目錄",
"Output directory": "輸出目錄",
"Resize mode": "縮放模式",
"Just resize": "拉伸",
"Crop and resize": "裁剪",
"Resize and fill": "填充",
"img2img alternative test": "圖生圖的另一種測試",
"Loopback": "回送",
"Outpainting mk2": "向外繪製第二版",
"Poor man's outpainting": "效果稍差的向外繪製",
"SD upscale": "使用 SD 放大",
"should be 2 or lower.": "必須小於等於2",
"Override `Sampling method` to Euler?(this method is built for it)": "覆寫「採樣方法」為 Euler?(這個方法就是為這樣做設計的)",
"Override `prompt` to the same value as `original prompt`?(and `negative prompt`)": "覆寫「提示詞」為「初始提示詞」?(包括「反向提示詞」)",
"Original prompt": "初始提示詞",
"Original negative prompt": "初始反向提示詞",
"Override `Sampling Steps` to the same value as `Decode steps`?": "覆寫「採樣疊代步數」為「解碼疊代步數」?",
"Decode steps": "解碼疊代步數",
"Override `Denoising strength` to 1?": "覆寫「重繪幅度」為1?",
"Decode CFG scale": "解碼提示詞相關性(CFG)",
"Randomness": "隨機度",
"Sigma adjustment for finding noise for image": "為尋找圖中噪點的 Sigma 調整",
"Loops": "疊代次數",
"Denoising strength change factor": "重繪幅度的調整係數",
"Recommended settings: Sampling Steps: 80-100, Sampler: Euler a, Denoising strength: 0.8": "推薦設定:採樣疊代步數:80-100,採樣器:Euler a,重繪幅度:0.8",
"Pixels to expand": "拓展的畫素數",
"Outpainting direction": "向外繪製的方向",
"left": "左",
"right": "右",
"up": "上",
"down": "下",
"Fall-off exponent (lower=higher detail)": "衰減指數(越低細節越好)",
"Color variation": "色彩變化",
"Will upscale the image to twice the dimensions; use width and height sliders to set tile size": "將圖像放大到兩倍尺寸; 使用寬度和高度滑塊設定圖塊尺寸",
"Tile overlap": "圖塊重疊的畫素",
"Upscaler": "放大演算法",
"Lanczos": "Lanczos",
"Nearest": "最鄰近(整數縮放)",
"LDSR": "LDSR",
"BSRGAN 4x": "BSRGAN 4x",
"ESRGAN_4x": "ESRGAN_4x",
"R-ESRGAN 4x+ Anime6B": "R-ESRGAN 4x+ Anime6B",
"ScuNET GAN": "ScuNET GAN",
"ScuNET PSNR": "ScuNET PSNR",
"SwinIR_4x": "SwinIR 4x",
"Single Image": "單個圖像",
"Batch Process": "批量處理",
"Batch from Directory": "從目錄進行批量處理",
"Source": "來源",
"Show result images": "顯示輸出圖像",
"Scale by": "等比縮放",
"Scale to": "指定尺寸縮放",
"Resize": "縮放",
"Crop to fit": "裁剪以適應",
"Upscaler 2": "放大演算法 2",
"Upscaler 2 visibility": "放大演算法 2 可見度",
"GFPGAN visibility": "GFPGAN 可見度",
"CodeFormer visibility": "CodeFormer 可見度",
"CodeFormer weight (0 = maximum effect, 1 = minimum effect)": "CodeFormer 權重 (0 = 最大效果, 1 = 最小效果)",
"Open output directory": "打開輸出目錄",
"Upscale Before Restoring Faces": "放大後再進行面部修復",
"Send to txt2img": ">> 文生圖",
"A merger of the two checkpoints will be generated in your": "合併後的模型權重存檔點會生成在你的",
"checkpoint": "模型權重存檔點",
"directory.": "目錄",
"Primary model (A)": "主要模型 (A)",
"Secondary model (B)": "第二模型 (B)",
"Tertiary model (C)": "第三模型 (C)",
"Custom Name (Optional)": "自訂名稱 (可選)",
"Multiplier (M) - set to 0 to get model A": "倍率 (M) - 設為 0 等價於模型 A",
"Interpolation Method": "插值方法",
"Weighted sum": "加權和",
"Add difference": "加入差分",
"Save as float16": "以 float16 儲存",
"See": "檢視",
"wiki": "wiki文件",
"for detailed explanation.": "以了解詳細說明",
"Create embedding": "生成 embedding",
"Create aesthetic images embedding": "生成美術風格圖集 embedding",
"Create hypernetwork": "生成超網路(Hypernetwork)",
"Preprocess images": "圖像預處理",
"Name": "名稱",
"Initialization text": "初始化文字",
"Number of vectors per token": "每個 token 的向量數",
"Overwrite Old Embedding": "覆寫舊的 Embedding",
"Modules": "模組",
"Enter hypernetwork layer structure": "輸入超網路(Hypernetwork)層結構",
"Select activation function of hypernetwork": "選擇超網路(Hypernetwork)的激活函數",
"linear": "linear",
"relu": "relu",
"leakyrelu": "leakyrelu",
"elu": "elu",
"swish": "swish",
"tanh": "tanh",
"sigmoid": "sigmoid",
"celu": "celu",
"gelu": "gelu",
"glu": "glu",
"hardshrink": "hardshrink",
"hardsigmoid": "hardsigmoid",
"hardtanh": "hardtanh",
"logsigmoid": "logsigmoid",
"logsoftmax": "logsoftmax",
"mish": "mish",
"prelu": "prelu",
"rrelu": "rrelu",
"relu6": "relu6",
"selu": "selu",
"silu": "silu",
"softmax": "softmax",
"softmax2d": "softmax2d",
"softmin": "softmin",
"softplus": "softplus",
"softshrink": "softshrink",
"softsign": "softsign",
"tanhshrink": "tanhshrink",
"threshold": "閾值",
"Select Layer weights initialization. relu-like - Kaiming, sigmoid-like - Xavier is recommended": "挑選初始化層權重的方案. 類relu - Kaiming, 類sigmoid - Xavier 都是比較推薦的選項",
"Normal": "正態",
"KaimingUniform": "Kaiming 均勻",
"KaimingNormal": "Kaiming 正態",
"XavierUniform": "Xavier 均勻",
"XavierNormal": "Xavier 正態",
"Add layer normalization": "加入層標準化",
"Use dropout": "採用 dropout 防止過擬合",
"Overwrite Old Hypernetwork": "覆寫舊的超網路(Hypernetwork)",
"Source directory": "來源目錄",
"Destination directory": "目標目錄",
"Existing Caption txt Action": "對已有的TXT說明文字的行為",
"ignore": "無視",
"copy": "複製",
"prepend": "放前面",
"append": "放後面",
"Create flipped copies": "生成鏡像副本",
"Split oversized images into two": "將過大的圖像分為兩份",
"Split oversized images": "分割過大的圖像",
"Auto focal point crop": "自動焦點裁切",
"Use BLIP for caption": "使用 BLIP 生成說明文字(自然語言描述)",
"Use deepbooru for caption": "使用 deepbooru 生成說明文字(標記)",
"Split image threshold": "圖像分割閾值",
"Split image overlap ratio": "分割圖像重疊的比率",
"Focal point face weight": "焦點面部權重",
"Focal point entropy weight": "焦點熵權重",
"Focal point edges weight": "焦點線條權重",
"Create debug image": "生成除錯圖片",
"Preprocess": "預處理",
"Train an embedding; must specify a directory with a set of 1:1 ratio images": "訓練 embedding; 必須指定一組具有 1:1 比例圖像的目錄",
"Train an embedding or Hypernetwork; you must specify a directory with a set of 1:1 ratio images": "訓練 embedding 或者超網路(Hypernetwork); 必須指定一組具有 1:1 比例圖像的目錄",
"[wiki]": "[wiki文件]",
"Embedding": "Embedding",
"Embedding Learning rate": "Embedding 學習率",
"Hypernetwork Learning rate": "超網路(Hypernetwork)學習率",
"Learning rate": "學習率",
"Dataset directory": "資料集目錄",
"Log directory": "日誌目錄",
"Prompt template file": "提示詞模版檔案",
"Max steps": "最大疊代步數",
"Save an image to log directory every N steps, 0 to disable": "每 N 步儲存一個圖像到日誌目錄,0 表示禁用",
"Save a copy of embedding to log directory every N steps, 0 to disable": "每 N 步將 embedding 的副本儲存到日誌目錄,0 表示禁用",
"Save images with embedding in PNG chunks": "儲存圖像,並在 PNG 圖片檔案中嵌入 embedding 檔案",
"Read parameters (prompt, etc...) from txt2img tab when making previews": "進行預覽時,從文生圖頁籤中讀取參數(提示詞等)",
"Train Hypernetwork": "訓練超網路(Hypernetwork)",
"Train Embedding": "訓練 Embedding",
"Create an aesthetic embedding out of any number of images": "從任意數量的圖像中建立美術風格 embedding",
"Create images embedding": "生成圖集 embedding",
"txt2img history": "文生圖歷史記錄",
"img2img history": "圖生圖歷史記錄",
"extras history": "後處理歷史記錄",
"extras": "後處理",
"favorites": "收藏夾",
"Favorites": "收藏夾",
"Others": "其他",
"custom fold": "自訂資料夾",
"Load": "載入",
"Images directory": "圖像目錄",
"Prev batch": "上一批",
"Next batch": "下一批",
"Dropdown": "下拉式清單",
"First Page": "首頁",
"Prev Page": "上一頁",
"Page Index": "頁數",
"Next Page": "下一頁",
"End Page": "尾頁",
"number of images to delete consecutively next": "接下來要連續刪除的圖像數",
"delete next": "刪除下一張",
"Delete": "刪除",
"sort by": "排序方式",
"path name": "路徑名",
"date": "日期",
"keyword": "搜尋",
"Generate Info": "生成資訊",
"File Name": "檔案名",
"Collect": "收藏",
"Refresh page": "刷新頁面",
"Date to": "日期至",
"Move to favorites": "移動到收藏夾",
"Renew Page": "刷新頁面",
"Number": "數量",
"set_index": "設定索引",
"load_switch": "載入開關",
"turn_page_switch": "翻頁開關",
"Checkbox": "核取方塊",
"Apply settings": "儲存設定",
"Saving images/grids": "儲存圖像/宮格圖",
"Always save all generated images": "始終儲存所有生成的圖像",
"File format for images": "圖像的檔案格式",
"Images filename pattern": "圖像檔案名格式",
"Add number to filename when saving": "儲存的時候在檔案名里加入數字",
"Always save all generated image grids": "始終儲存所有生成的宮格圖",
"File format for grids": "宮格圖的檔案格式",
"Add extended info (seed, prompt) to filename when saving grid": "儲存宮格圖時,將擴展資訊(隨機種子,提示詞)加入到檔案名",
"Do not save grids consisting of one picture": "只有一張圖片時不要儲存宮格圖",
"Prevent empty spots in grid (when set to autodetect)": "(啟用自動偵測時)防止宮格圖中出現空位",
"Grid row count; use -1 for autodetect and 0 for it to be same as batch size": "宮格圖行數; 使用 -1 進行自動檢測,使用 0 使其與每批數量相同",
"Save text information about generation parameters as chunks to png files": "將有關生成參數的文本資訊,作為塊儲存到PNG圖片檔案中",
"Create a text file next to every image with generation parameters.": "儲存圖像時,在每個圖像旁邊建立一個文本檔案儲存生成參數",
"Save a copy of image before doing face restoration.": "在進行面部修復之前儲存圖像副本",
"Save a copy of image before applying highres fix.": "在做高解析度修復之前儲存初始圖像副本",
"Save a copy of image before applying color correction to img2img results": "在對圖生圖結果套用顏色校正之前儲存圖像副本",
"Quality for saved jpeg images": "儲存的JPEG圖像的品質",
"If PNG image is larger than 4MB or any dimension is larger than 4000, downscale and save copy as JPG": "如果 PNG 圖像大於 4MB 或寬高大於 4000,則縮小並儲存副本為 JPG 圖片",
"Use original name for output filename during batch process in extras tab": "在更多頁籤中的批量處理過程中,使用原始名稱作為輸出檔案名",
"When using 'Save' button, only save a single selected image": "使用「儲存」按鈕時,只儲存一個選定的圖像",
"Do not add watermark to images": "不要給圖像加浮水印",
"Paths for saving": "儲存路徑",
"Output directory for images; if empty, defaults to three directories below": "圖像的輸出目錄; 如果為空,則預設為以下三個目錄",
"Output directory for txt2img images": "文生圖的輸出目錄",
"Output directory for img2img images": "圖生圖的輸出目錄",
"Output directory for images from extras tab": "更多頁籤的輸出目錄",
"Output directory for grids; if empty, defaults to two directories below": "宮格圖的輸出目錄; 如果為空,則預設為以下兩個目錄",
"Output directory for txt2img grids": "文生圖宮格的輸出目錄",
"Output directory for img2img grids": "圖生圖宮格的輸出目錄",
"Directory for saving images using the Save button": "使用「儲存」按鈕儲存圖像的目錄",
"Saving to a directory": "儲存到目錄",
"Save images to a subdirectory": "將圖像儲存到子目錄",
"Save grids to a subdirectory": "將宮格圖儲存到子目錄",
"When using \"Save\" button, save images to a subdirectory": "使用「儲存」按鈕時,將圖像儲存到子目錄",
"Directory name pattern": "目錄名稱格式",
"Max prompt words for [prompt_words] pattern": "[prompt_words] 格式的最大提示詞數量",
"Upscaling": "放大",
"Tile size for ESRGAN upscalers. 0 = no tiling.": "ESRGAN 的圖塊尺寸。0 = 不分塊",
"Tile overlap, in pixels for ESRGAN upscalers. Low values = visible seam.": "ESRGAN 的圖塊重疊畫素。低值 = 可見接縫",
"Tile size for all SwinIR.": "適用所有 SwinIR 系演算法的圖塊尺寸",
"Tile overlap, in pixels for SwinIR. Low values = visible seam.": "SwinIR 的圖塊重疊畫素。低值 = 可見接縫",
"LDSR processing steps. Lower = faster": "LDSR 處理疊代步數。更低 = 更快",
"Upscaler for img2img": "圖生圖的放大演算法",
"Upscale latent space image when doing hires. fix": "做高解析度修復時,也放大潛空間圖像",
"Face restoration": "面部修復",
"CodeFormer weight parameter; 0 = maximum effect; 1 = minimum effect": "CodeFormer 權重參數; 0 = 最大效果; 1 = 最小效果",
"Move face restoration model from VRAM into RAM after processing": "面部修復處理完成後,將面部修復模型從顯存(VRAM)移至內存(RAM)",
"System": "系統",
"VRAM usage polls per second during generation. Set to 0 to disable.": "生成圖像時每秒輪詢顯存(VRAM)使用情況的次數。設定為 0 以禁用",
"Always print all generation info to standard output": "始終將所有生成資訊輸出到 standard output (一般為控制台)",
"Add a second progress bar to the console that shows progress for an entire job.": "向控制台加入第二個進度列,顯示整個作業的進度",
"Training": "訓練",
"Unload VAE and CLIP from VRAM when training": "訓練時從顯存(VRAM)中取消 VAE 和 CLIP 的載入",
"Move VAE and CLIP to RAM when training hypernetwork. Saves VRAM.": "訓練時將 VAE 和 CLIP 從顯存(VRAM)移放到內存(RAM),節省顯存(VRAM)",
"Move VAE and CLIP to RAM when training if possible. Saves VRAM.": "訓練時將 VAE 和 CLIP 從顯存(VRAM)移放到內存(RAM)如果可行的話,節省顯存(VRAM)",
"Filename word regex": "檔案名用詞的正則表達式",
"Filename join string": "檔案名連接用字串",
"Number of repeats for a single input image per epoch; used only for displaying epoch number": "每個 epoch 中單個輸入圖像的重複次數; 僅用於顯示 epoch 數",
"Save an csv containing the loss to log directory every N steps, 0 to disable": "每 N 步儲存一個包含 loss 的CSV表格到日誌目錄,0 表示禁用",
"Use cross attention optimizations while training": "訓練時開啟 cross attention 最佳化",
"Stable Diffusion": "Stable Diffusion",
"Checkpoints to cache in RAM": "快取在內存(RAM)中的模型權重存檔點",
"SD VAE": "模型的VAE",
"auto": "自動",
"Hypernetwork strength": "超網路(Hypernetwork)強度",
"Inpainting conditioning mask strength": "局部重繪時圖像調節的蒙版屏蔽強度",
"Apply color correction to img2img results to match original colors.": "對圖生圖結果套用顏色校正以匹配原始顏色",
"With img2img, do exactly the amount of steps the slider specifies (normally you'd do less with less denoising).": "在進行圖生圖的時候,確切地執行滑塊指定的疊代步數(正常情況下更弱的重繪幅度需要更少的疊代步數)",
"Enable quantization in K samplers for sharper and cleaner results. This may change existing seeds. Requires restart to apply.": "在 K 採樣器中啟用量化以獲得更清晰,更清晰的結果。這可能會改變現有的隨機種子。需要重新啟動才能套用",
"Emphasis: use (text) to make model pay more attention to text and [text] to make it pay less attention": "強調符:使用 (文字) 使模型更關注該文本,使用 [文字] 使其減少關注",
"Use old emphasis implementation. Can be useful to reproduce old seeds.": "使用舊的強調符實作。可用於復現舊隨機種子",
"Make K-diffusion samplers produce same images in a batch as when making a single image": "使 K-diffusion 採樣器批量生成與生成單個圖像時,產出相同的圖像",
"Increase coherency by padding from the last comma within n tokens when using more than 75 tokens": "當使用超過 75 個 token 時,通過從 n 個 token 中的最後一個逗號填補來提高一致性",
"Filter NSFW content": "過濾成人內容",
"Stop At last layers of CLIP model": "在 CLIP 模型的最後哪一層停下",
"Interrogate Options": "反推提示詞選項",
"Interrogate: keep models in VRAM": "反推: 將模型儲存在顯存(VRAM)中",
"Interrogate: use artists from artists.csv": "反推: 使用 artists.csv 中的藝術家",
"Interrogate: include ranks of model tags matches in results (Has no effect on caption-based interrogators).": "反推: 在生成結果中包含與模型標記相匹配的等級(對基於生成自然語言描述的反推沒有影響)",
"Interrogate: num_beams for BLIP": "反推: BLIP 的 num_beams",
"Interrogate: minimum description length (excluding artists, etc..)": "反推: 最小描述長度(不包括藝術家,等…)",
"Interrogate: maximum description length": "反推: 最大描述長度",
"CLIP: maximum number of lines in text file (0 = No limit)": "CLIP: 文本檔案中的最大行數(0 = 無限制)",
"Interrogate: deepbooru score threshold": "反推: deepbooru 分數閾值",
"Interrogate: deepbooru sort alphabetically": "反推: deepbooru 按字母順序排序",
"use spaces for tags in deepbooru": "在 deepbooru 中為標記使用空格",
"escape (\\) brackets in deepbooru (so they are used as literal brackets and not for emphasis)": "在 deepbooru 中使用轉義 (\\) 括號(因此它們用作文字括號而不是強調符號)",
"User interface": "使用者介面",
"Show progressbar": "顯示進度列",
"Show image creation progress every N sampling steps. Set 0 to disable.": "每 N 個採樣疊代步數顯示圖像生成進度。設定 0 禁用",
"Show previews of all images generated in a batch as a grid": "以網格的形式,預覽批量生成的所有圖像",
"Show grid in results for web": "在網頁的結果中顯示宮格圖",
"Do not show any images in results for web": "不在網頁的結果中顯示任何圖像",
"Add model hash to generation information": "將模型的雜湊值加入到生成資訊",
"Add model name to generation information": "將模型名稱加入到生成資訊",
"When reading generation parameters from text into UI (from PNG info or pasted text), do not change the selected model/checkpoint.": "從文本讀取生成參數到使用者介面(從 PNG 圖片資訊或粘貼文本)時,不要更改選定的模型權重存檔點",
"Send seed when sending prompt or image to other interface": "將提示詞或者圖片發送到 >> 其他界面時,把隨機種子也傳送過去",
"Font for image grids that have text": "有文字的宮格圖使用的字體",
"Enable full page image viewer": "啟用整頁圖像檢視器",
"Show images zoomed in by default in full page image viewer": "在整頁圖像檢視器中,預設放大顯示圖像",
"Show generation progress in window title.": "在視窗標題中顯示生成進度",
"Quicksettings list": "快速設定列表",
"Localization (requires restart)": "本地化翻譯(需要儲存設定,並重啟Gradio)",
"Sampler parameters": "採樣器參數",
"Hide samplers in user interface (requires restart)": "在使用者介面中隱藏採樣器(需要重新啟動)",
"eta (noise multiplier) for DDIM": "DDIM 的 eta (噪聲乘數)",
"eta (noise multiplier) for ancestral samplers": "ancestral 採樣器的 eta (噪聲乘數)",
"img2img DDIM discretize": "圖生圖 DDIM 離散化",
"uniform": "均勻",
"quad": "二階",
"sigma churn": "sigma churn",
"sigma tmin": "最小(tmin) sigma",
"sigma noise": "sigma 噪聲",
"Eta noise seed delta": "Eta 噪聲種子偏移(ENSD)",
"Images Browser": "圖庫瀏覽器",
"Preload images at startup": "在啟動時預加載圖像",
"Number of columns on the page": "每頁列數",
"Number of rows on the page": "每頁行數",
"Number of pictures displayed on each page": "每頁顯示的圖像數量",
"Minimum number of pages per load": "每次載入的最小頁數",
"Number of grids in each row": "每行顯示多少格",
"Wildcards": "萬用字元",
"Use same seed for all images": "為所有圖像使用同一個隨機種子",
"Request browser notifications": "請求瀏覽器通知",
"Download localization template": "下載本地化模板",
"Reload custom script bodies (No ui updates, No restart)": "重新載入自訂指令碼主體(無使用者介面更新,無重啟)",
"Restart Gradio and Refresh components (Custom Scripts, ui.py, js and css only)": "重啟 Gradio 及刷新組件(僅限自訂指令碼,ui.py,JS 和 CSS)",
"Available": "可用",
"Install from URL": "從網址安裝",
"Apply and restart UI": "應用並重啟使用者介面",
"Check for updates": "檢查更新",
"Extension": "擴充",
"URL": "網址",
"Update": "更新",
"a1111-sd-webui-tagcomplete": "標記自動補全",
"unknown": "未知",
"deforum-for-automatic1111-webui": "Deforum",
"sd-dynamic-prompting": "動態提示詞",
"stable-diffusion-webui-aesthetic-gradients": "美術風格梯度",
"stable-diffusion-webui-aesthetic-image-scorer": "美術風格評等",
"stable-diffusion-webui-artists-to-study": "藝術家圖庫",
"stable-diffusion-webui-dataset-tag-editor": "資料集標記編輯器",
"stable-diffusion-webui-images-browser": "圖庫瀏覽器",
"stable-diffusion-webui-inspiration": "靈感",
"stable-diffusion-webui-wildcards": "萬用字元",
"Load from:": "載入自",
"Extension index URL": "擴充清單連結",
"URL for extension's git repository": "擴充的 git 倉庫連結",
"Local directory name": "本地路徑名",
"Prompt (press Ctrl+Enter or Alt+Enter to generate)": "提示詞(按 Ctrl+Enter 或 Alt+Enter 生成)",
"Negative prompt (press Ctrl+Enter or Alt+Enter to generate)": "反向提示詞(按 Ctrl+Enter 或 Alt+Enter 生成)",
"Add a random artist to the prompt.": "隨機加入一個藝術家到提示詞中",
"Read generation parameters from prompt or last generation if prompt is empty into user interface.": "從提示詞中讀取生成參數,如果提示詞為空,則讀取上一次的生成參數到使用者介面",
"Save style": "存儲為模板風格",
"Apply selected styles to current prompt": "將所選樣式套用於當前提示",
"Stop processing current image and continue processing.": "停止處理當前圖像,並繼續處理下一個",
"Stop processing images and return any results accumulated so far.": "停止處理圖像,並返回迄今為止累積的任何結果",
"Style to apply; styles have components for both positive and negative prompts and apply to both": "要套用的模版風格; 模版風格包含正向和反向提示詞,並套用於兩者",
"Do not do anything special": "什麼都不做",
"Which algorithm to use to produce the image": "使用哪種演算法生成圖像",
"Euler Ancestral - very creative, each can get a completely different picture depending on step count, setting steps to higher than 30-40 does not help": "Euler Ancestral - 非常有創意,可以根據疊代步數獲得完全不同的圖像,將疊代步數設定為高於 30-40 不會有正面作用",
"Denoising Diffusion Implicit Models - best at inpainting": "Denoising Diffusion Implicit models - 最擅長局部重繪",
"Produce an image that can be tiled.": "生成可用於平舖的圖像",
"Use a two step process to partially create an image at smaller resolution, upscale, and then improve details in it without changing composition": "使用兩步處理的時候,以較小的解析度生成初步圖像,接著放大圖像,然後在不更改構圖的情況下改進其中的細節",
"Determines how little respect the algorithm should have for image's content. At 0, nothing will change, and at 1 you'll get an unrelated image. With values below 1.0, processing will take less steps than the Sampling Steps slider specifies.": "決定演算法對圖像內容的影響程度。設定 0 時,什麼都不會改變,而在 1 時,你將獲得不相關的圖像。\n值低於 1.0 時,處理的疊代步數將少於「採樣疊代步數」滑塊指定的步數",
"How many batches of images to create": "建立多少批次的圖像",
"How many image to create in a single batch": "每批建立多少圖像",
"Classifier Free Guidance Scale - how strongly the image should conform to prompt - lower values produce more creative results": "Classifier Free Guidance Scale - 圖像應在多大程度上服從提示詞 - 較低的值會產生更有創意的結果",
"A value that determines the output of random number generator - if you create an image with same parameters and seed as another image, you'll get the same result": "一個固定隨機數生成器輸出的值 — 以相同參數和隨機種子生成的圖像會得到相同的結果",
"Set seed to -1, which will cause a new random number to be used every time": "將隨機種子設定為-1,則每次都會使用一個新的隨機數",
"Reuse seed from last generation, mostly useful if it was randomed": "重用上一次使用的隨機種子,如果想要固定結果就會很有用",
"Seed of a different picture to be mixed into the generation.": "將要參與生成的另一張圖的隨機種子",
"How strong of a variation to produce. At 0, there will be no effect. At 1, you will get the complete picture with variation seed (except for ancestral samplers, where you will just get something).": "想要產生多強烈的變化。設為 0 時,將沒有效果。設為 1 時,你將獲得完全產自差異隨機種子的圖像(ancestral 採樣器除外,你只是單純地生成了一些東西)",
"Make an attempt to produce a picture similar to what would have been produced with same seed at specified resolution": "嘗試生成與在指定解析度下使用相同隨機種子生成的圖像相似的圖片",
"This text is used to rotate the feature space of the imgs embs": "此文本用於旋轉圖集 embeddings 的特徵空間",
"Separate values for X axis using commas.": "使用逗號分隔 X 軸的值",
"Separate values for Y axis using commas.": "使用逗號分隔 Y 軸的值",
"Write image to a directory (default - log/images) and generation parameters into csv file.": "將圖像寫入目錄(預設 — log/images)並將生成參數寫入CSV表格檔案",
"Open images output directory": "打開圖像輸出目錄",
"How much to blur the mask before processing, in pixels.": "處理前要對蒙版進行多強的模糊,以畫素為單位",
"What to put inside the masked area before processing it with Stable Diffusion.": "在使用 Stable Diffusion 處理蒙版區域之前要在蒙版區域內放置什麼",
"fill it with colors of the image": "用圖像的顏色(高強度模糊)填充它",
"keep whatever was there originally": "保留原來的圖像,不進行預處理",
"fill it with latent space noise": "於潛空間填充噪聲",
"fill it with latent space zeroes": "於潛空間填零",
"Upscale masked region to target resolution, do inpainting, downscale back and paste into original image": "將蒙版區域(包括預留畫素長度的緩衝區域)放大到目標解析度,進行局部重繪。\n然後縮小並粘貼回原始圖像中",
"Resize image to target resolution. Unless height and width match, you will get incorrect aspect ratio.": "將圖像大小調整為目標解析度。除非高度和寬度匹配,否則你將獲得不正確的縱橫比",
"Resize the image so that entirety of target resolution is filled with the image. Crop parts that stick out.": "調整圖像大小,使整個目標解析度都被圖像填充。裁剪多出來的部分",
"Resize the image so that entirety of image is inside target resolution. Fill empty space with image's colors.": "調整圖像大小,使整個圖像在目標解析度內。用圖像的顏色填充空白區域",
"How many times to repeat processing an image and using it as input for the next iteration": "重複處理圖像並用作下次疊代輸入的次數",
"In loopback mode, on each loop the denoising strength is multiplied by this value. <1 means decreasing variety so your sequence will converge on a fixed picture. >1 means increasing variety so your sequence will become more and more chaotic.": "在回送模式下,在每個循環中,重繪幅度都會乘以該值。<1 表示減少多樣性,因此你的這一組圖將集中在固定的圖像上。>1 意味著增加多樣性,因此你的這一組圖將變得越來越混亂",
"For SD upscale, how much overlap in pixels should there be between tiles. Tiles overlap so that when they are merged back into one picture, there is no clearly visible seam.": "使用 SD 放大時,圖塊之間應該有多少畫素重疊。圖塊之間需要重疊才可以讓它們在合併回一張圖像時,沒有清晰可見的接縫",
"A directory on the same machine where the server is running.": "與伺服器主機上的目錄",
"Leave blank to save images to the default path.": "留空以將圖像儲存到預設路徑",
"Result = A * (1 - M) + B * M": "結果 = A * (1 - M) + B * M",
"Result = A + (B - C) * M": "結果 = A + (B - C) * M",
"1st and last digit must be 1. ex:'1, 2, 1'": "第一個和最後一個數字必須是 1。例:'1, 2, 1'",
"how fast should the training go. Low values will take longer to train, high values may fail to converge (not generate accurate results) and/or may break the embedding (This has happened if you see Loss: nan in the training info textbox. If this happens, you need to manually restore your embedding from an older not-broken backup).\n\nYou can set a single numeric value, or multiple learning rates using the syntax:\n\n rate_1:max_steps_1, rate_2:max_steps_2, ...\n\nEG: 0.005:100, 1e-3:1000, 1e-5\n\nWill train with rate of 0.005 for first 100 steps, then 1e-3 until 1000 steps, then 1e-5 for all remaining steps.": "訓練應該多快。低值將需要更長的時間來訓練,高值可能無法收斂(無法產生準確的結果)以及/也許可能會破壞 embedding(如果你在訓練資訊文字方塊中看到 Loss: nan 就會發生這種情況。如果發生這種情況,你需要從較舊的未損壞的備份手動恢復 embedding)\n\n你可以使用以下語法設定單個數值或多個學習率:\n\n 率1:步限1, 率2:步限2, …\n\n如: 0.005:100, 1e-3:1000, 1e-5\n\n即前 100 步將以 0.005 的速率訓練,接著直到 1000 步為止以 1e-3 訓練,然後剩餘所有步以 1e-5 訓練",
"Path to directory with input images": "帶有輸入圖像的路徑",
"Path to directory where to write outputs": "進行輸出的路徑",
"Input images directory": "輸入圖像目錄",
"Use following tags to define how filenames for images are chosen: [steps], [cfg], [prompt], [prompt_no_styles], [prompt_spaces], [width], [height], [styles], [sampler], [seed], [model_hash], [prompt_words], [date], [datetime], [datetime<Format>], [datetime<Format><Time Zone>], [job_timestamp]; leave empty for default.": "使用以下標記定義如何選擇圖像的檔案名: [steps], [cfg], [prompt], [prompt_no_styles], [prompt_spaces], [width], [height], [styles], [sampler], [seed], [model_hash], [prompt_words], [date], [datetime], [datetime<Format>], [datetime<Format><Time Zone>], [job_timestamp]; 預設請留空",
"If this option is enabled, watermark will not be added to created images. Warning: if you do not add watermark, you may be behaving in an unethical manner.": "如果啟用此選項,浮水印將不會加入到生成出來的圖像中。警告:如果你不加入浮水印,你的行為可能是不符合道德操守的",
"Use following tags to define how subdirectories for images and grids are chosen: [steps], [cfg], [prompt], [prompt_no_styles], [prompt_spaces], [width], [height], [styles], [sampler], [seed], [model_hash], [prompt_words], [date], [datetime], [datetime<Format>], [datetime<Format><Time Zone>], [job_timestamp]; leave empty for default.": "使用以下標記定義如何選擇圖像和宮格圖的子目錄: [steps], [cfg], [prompt], [prompt_no_styles], [prompt_spaces], [width], [height], [styles], [sampler], [seed], [model_hash], [prompt_words], [date], [datetime], [datetime<Format>], [datetime<Format><Time Zone>], [job_timestamp]; 預設請留空",
"Restore low quality faces using GFPGAN neural network": "使用 GFPGAN 神經網路修復低品質面部",
"This regular expression will be used extract words from filename, and they will be joined using the option below into label text used for training. Leave empty to keep filename text as it is.": "此正則表達式將用於從檔案名中提取單詞,並將使用以下選項將它們接合到用於訓練的標記文本中。留空以保持檔案名文本不變",
"This string will be used to join split words into a single line if the option above is enabled.": "如果啟用了上述選項,則此處的字元會用於將拆分的單詞接合為同一行",
"Only applies to inpainting models. Determines how strongly to mask off the original image for inpainting and img2img. 1.0 means fully masked, which is the default behaviour. 0.0 means a fully unmasked conditioning. Lower values will help preserve the overall composition of the image, but will struggle with large changes.": "僅適用於局部重繪專用的模型(模型後綴為 inpainting.ckpt 的模型)。決定了蒙版在局部重繪以及圖生圖中屏蔽原圖內容的強度。 1.0 表示完全屏蔽原圖,這是預設行為。 0.0 表示完全不屏蔽讓原圖進行圖像調節。較低的值將有助於保持原圖的整體構圖,但很難遇到較大的變化",
"List of setting names, separated by commas, for settings that should go to the quick access bar at the top, rather than the usual setting tab. See modules/shared.py for setting names. Requires restarting to apply.": "設定項名稱列表,以逗號分隔,該設定會移動到頂部的快速存取列,而不是預設的設定頁籤。有關設定名稱,請參見 modules/shared.py。需要重新啟動才能套用",
"If this values is non-zero, it will be added to seed and used to initialize RNG for noises when using samplers with Eta. You can use this to produce even more variation of images, or you can use this to match images of other software if you know what you are doing.": "如果這個值不為零,它將被加入到隨機種子中,並在使用帶有 Eta 的採樣器時用於初始化隨機噪聲。你可以使用它來產生更多的圖像變化,或者你可以使用它來模仿其他軟體生成的圖像,如果你知道你在做什麼",
"Leave empty for auto": "留空時自動生成",
"Autocomplete options": "自動補全選項",
"Enable Autocomplete": "開啟Tag補全",
"Select which Real-ESRGAN models to show in the web UI. (Requires restart)": "選擇哪些 Real-ESRGAN 模型顯示在網頁使用者介面。(需要重新啟動)",
"Allowed categories for random artists selection when using the Roll button": "使用抽選藝術家按鈕時將會隨機的藝術家類別",
"Append commas": "附加逗號",
"latest": "最新",
"behind": "落後",
"Roll three": "抽三位出來",
"Generate forever": "無限生成",
"Cancel generate forever": "停止無限生成",
"How many times to improve the generated image iteratively; higher values take longer; very low values can produce bad results": "疊代改進生成的圖像多少次;更高的值需要更長的時間;非常低的值會產生不好的結果",
"Draw a mask over an image, and the script will regenerate the masked area with content according to prompt": "在圖像上畫一個蒙版,指令碼會根據提示重新生成蒙版區域的內容",
"Upscale image normally, split result into tiles, improve each tile using img2img, merge whole image back": "正常放大圖像,將結果分割成圖塊,用圖生圖改進每個圖塊,最後將整個圖像合併回來",
"Create a grid where images will have different parameters. Use inputs below to specify which parameters will be shared by columns and rows": "創建一個網格,圖像將有不同的參數。使用下面的輸入來指定哪些參數將由列和行共享",
"Run Python code. Advanced user only. Must run program with --allow-code for this to work": "執行 Python 程式碼。僅限老手使用。必須以 --allow-code 來開啟程式,才能使其執行",
"Separate a list of words with commas, and the first word will be used as a keyword: script will search for this word in the prompt, and replace it with others": "以逗號分割的單詞列表,第一個單詞將被用作關鍵詞:指令碼將在提示詞中搜尋這個單詞,並用其他單詞替換它",
"Separate a list of words with commas, and the script will make a variation of prompt with those words for their every possible order": "以逗號分割的單詞列表,指令碼會排列出這些單詞的所有排列方式,並加入提示詞各生成一次",
"Reconstruct prompt from existing image and put it into the prompt field.": "從現有的圖像中重構出提示詞,並將其放入提示詞的輸入文字方塊",
"Set the maximum number of words to be used in the [prompt_words] option; ATTENTION: If the words are too long, they may exceed the maximum length of the file path that the system can handle": "設定在[prompt_words]選項中要使用的最大字數;注意:如果字數太長,可能會超過系統可處理的檔案路徑的最大長度",
"Process an image, use it as an input, repeat.": "處理一張圖像,將其作為輸入,並重複",
"Insert selected styles into prompt fields": "在提示詞中插入選定的模版風格",
"Save current prompts as a style. If you add the token {prompt} to the text, the style use that as placeholder for your prompt when you use the style in the future.": "將當前的提示詞儲存為模版風格。如果你在文本中加入{prompt}標記,那麼將來你使用該模版風格時,你現有的提示詞會替換模版風格中的{prompt}",
"Loads weights from checkpoint before making images. You can either use hash or a part of filename (as seen in settings) for checkpoint name. Recommended to use with Y axis for less switching.": "在生成圖像之前從模型權重存檔點中載入權重。你可以使用哈希值或檔案名的一部分(如設定中所示)作為模型權重存檔點名稱。建議用在Y軸上以減少過程中模型的切換",
"Torch active: Peak amount of VRAM used by Torch during generation, excluding cached data.\nTorch reserved: Peak amount of VRAM allocated by Torch, including all active and cached data.\nSys VRAM: Peak amount of VRAM allocation across all applications / total GPU VRAM (peak utilization%).": "Torch active: 在生成過程中,Torch使用的顯存(VRAM)峰值,不包括快取的數據。\nTorch reserved: Torch 分配的顯存(VRAM)的峰值量,包括所有活動和快取數據。\nSys VRAM: 所有應用程式分配的顯存(VRAM)的峰值量 / GPU 的總顯存(VRAM)(峰值利用率%)",
"Uscale the image in latent space. Alternative is to produce the full image from latent representation, upscale that, and then move it back to latent space.": "放大潛空間中的圖像。而另一種方法是,從潛變量表達中直接解碼並生成完整的圖像,接著放大它,然後再將其編碼回潛空間",
"Start drawing": "開始繪製",
"Description": "描述",
"Action": "行動",
"Aesthetic Gradients": "美術風格梯度",
"aesthetic-gradients": "美術風格梯度",
"Dynamic Prompts": "動態提示詞",
"images-browser": "圖庫瀏覽器",
"Inspiration": "靈感",
"Deforum": "Deforum",
"Artists to study": "藝術家圖庫",
"Aesthetic Image Scorer": "美術風格評分",
"Dataset Tag Editor": "數據集標記編輯器",
"Face restoration model": "面部修復模型",
"Install": "安裝",
"Installing...": "安裝中…",
"Installed": "已安裝"
}贊助廣告 ‧ Sponsor advertisements






 《上一篇》Stable Diffusion web UI x Evt_V2:本機 AI 生成高品質二次元動漫角色
《上一篇》Stable Diffusion web UI x Evt_V2:本機 AI 生成高品質二次元動漫角色  《下一篇》Stable Diffusion web UI x Stable Diffusion 2.0:本機 AI 生成各式各樣的影像
《下一篇》Stable Diffusion web UI x Stable Diffusion 2.0:本機 AI 生成各式各樣的影像 







留言區 / Comments
萌芽論壇