隨著大型語言模型(LLM)的普及,越來越多開發者與科技愛好者傾向在本地端(Local)運行 AI 模型,以確保隱私、降低延遲並免去昂貴的雲端 API 費用。然而,面對 Llama、Gemma、Qwen 等五花八門的開源模型,以及各自不同的參數大小(如 8B、14B、32B)與量化版本(Quantization),一般使用者往往難以判斷自己的電腦配備(尤其是顯示卡的 VRAM 與系統記憶體 RAM)究竟能不能順利跑得動,或者運行速度是否會慢如蝸牛。
為了解決這個痛點,「CanIRun.ai」應運而生。這是一個完全在瀏覽器端運行的網頁工具,透過 WebGL、WebGPU 以及瀏覽器原生 API,它能在幾秒鐘內偵測出使用者的顯示卡型號、VRAM 容量、記憶體大小以及處理器核心數。接著,系統會結合內建的硬體資料庫與模型所需的記憶體公式,評估各款熱門 AI 模型在該設備上的運行表現(如每秒輸出的 Token 數量),並給予直觀的評級。最棒的是,所有的偵測與運算都在本地端完成,不會將任何隱私數據上傳至伺服器,既安全又高效率。
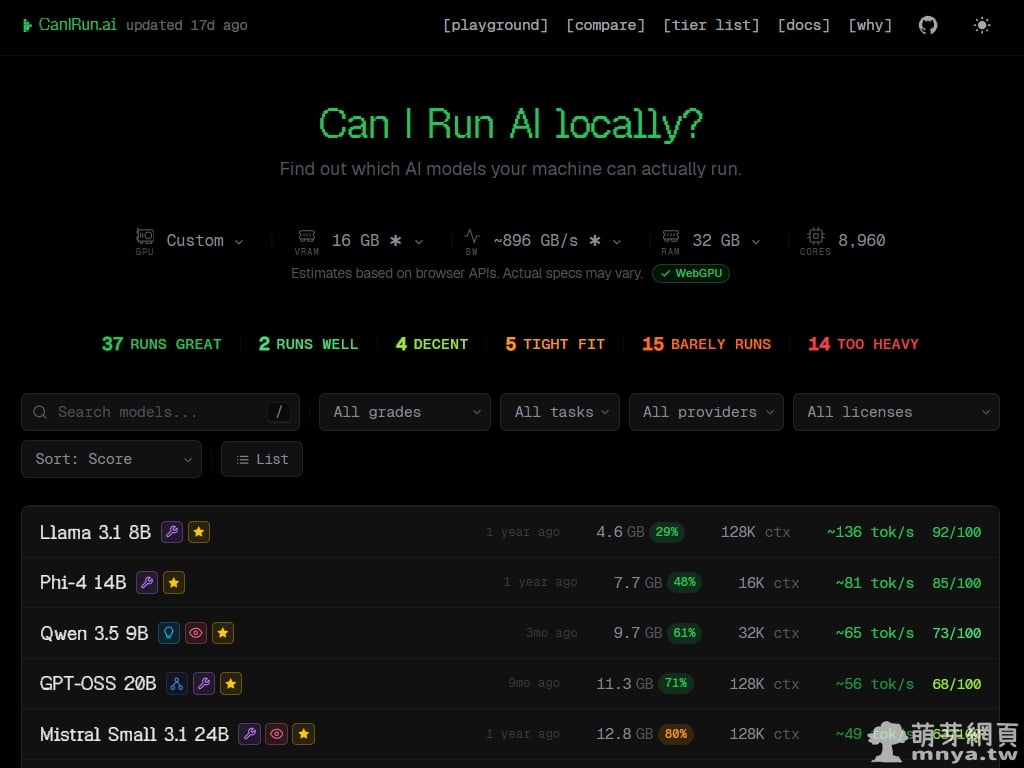
▲ 這是 CanIRun.ai 的主畫面,系統會自動偵測或讓使用者自訂硬體規格(如 16 GB VRAM)。下方會列出各模型在該配置下的評分與速度,例如 Llama 3.1 8B 獲得 92 分的極佳評價,預估速度達每秒 136 個 Token。
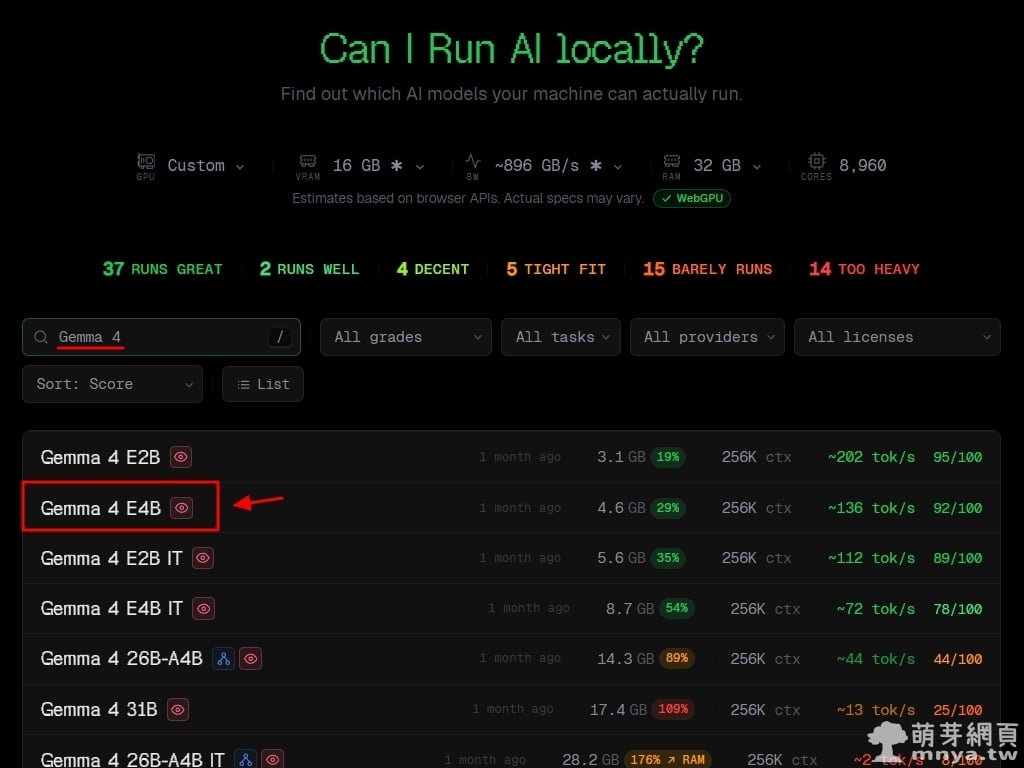
▲ 使用者可利用搜尋功能篩選特定模型,此處以關鍵字搜尋「Gemma 4」。紅色箭頭指出的「Gemma 4 E4B」在當前配置下表現優異,僅需 4.6 GB VRAM,並能跑出每秒 136 個 Token 的高速,綜合評分為 92 分。
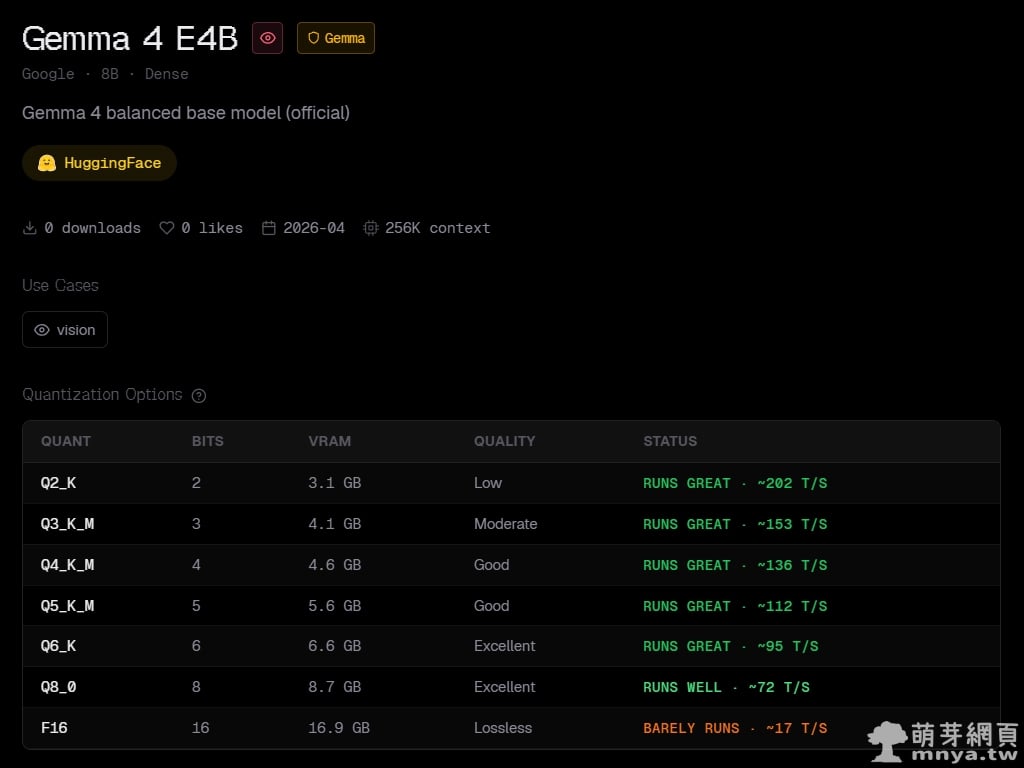
▲ 點擊特定模型可檢視詳細的量化選項(Quantization Options)。從 Q2_K 到 F16,系統完整列出各版本所需的 VRAM、生成品質及運行狀態。例如 Q4_K_M 版本在保持良好品質之餘,仍維持極佳的運行狀態。



 《上一篇》首次使用特力屋官網網購居家裝修用品
《上一篇》首次使用特力屋官網網購居家裝修用品 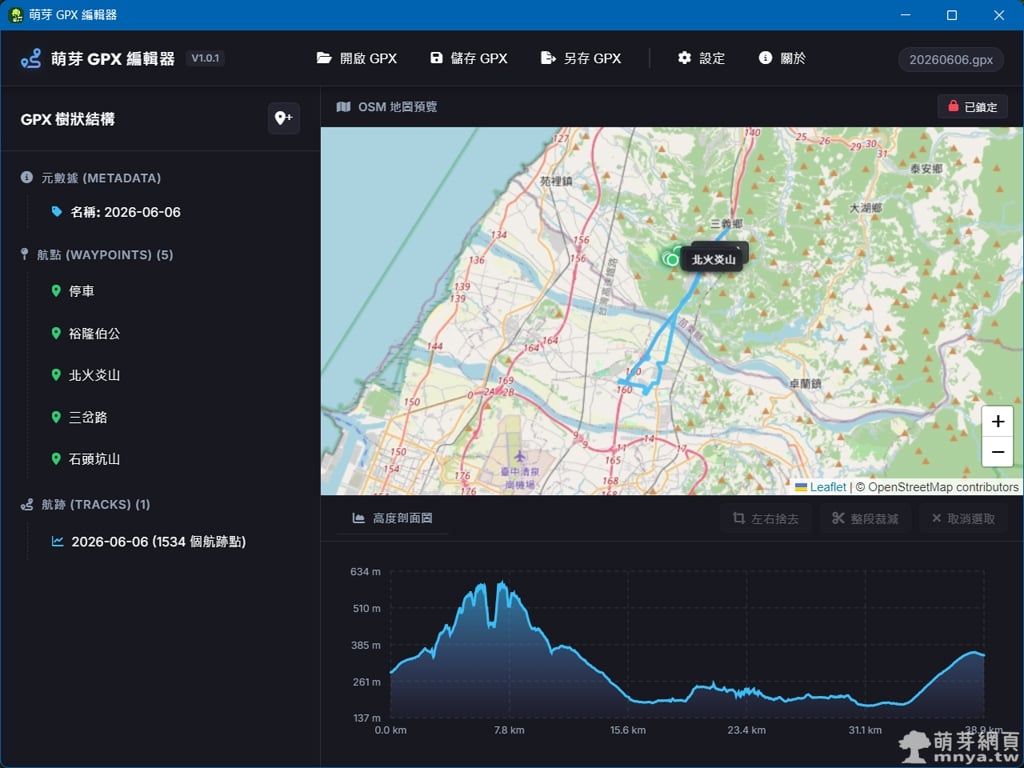 《下一篇》萌芽 GPX 編輯器:輕量級且美觀的 GPX 編輯神器!簡單易用、航點航跡皆可編輯!
《下一篇》萌芽 GPX 編輯器:輕量級且美觀的 GPX 編輯神器!簡單易用、航點航跡皆可編輯! 








留言區 / Comments
萌芽論壇