隨著生成式 AI 技術的飛速發展,訓練專屬於自己的角色 LoRA 模型已成為許多創作者與開發者的核心技能。過去我們習慣於使用 Stable Diffusion XL (SDXL) 進行訓練,雖然效果不俗,但在細節捕捉與特定畫風的學習上,往往需要經過繁瑣的參數微調與長時間的磨合。近期,由 Ostris 開發的「AI Toolkit」憑藉其直觀的介面與對新一代大模型「Z-Image-Turbo」的優化支援,成為了訓練界的新寵。這款模型在保持極速生成的同時,對於角色特徵(如髮型、瞳色、服飾結構)的學習能力極強,精準度遠超舊時代模型,非常適合用於 IP 角色的數位資產化。
本次實戰教學,我選用了萌芽系列網站旗下吉祥物「萌樂(Mnyue)」作為訓練對象。為了確保數據集的高品質,我事先利用 Nano Banana Pro 繪製了共計 15 張涵蓋立繪與角色情境圖的高品質素材,並精準編寫了對應的訓練用標籤(可使用二次元動漫專用 Danbooru 標籤混搭自然語言敘述,建議都以英文下提示詞)。硬體環境方面,我使用了 RTX 5070 Ti 16GB VRAM 搭配 64GB RAM 的配置。在訓練設定中,我將 Batch Size 設為 2,實測顯存佔用約落在 15GB 左右。完成總計 3000 步的訓練流程僅需約一個半小時的時間,這對於追求效率的創作者來說是非常理想的。最終生成的 LoRA 模型大小約為 81 MB,不僅還原度極高,且在畫風的學習能力上表現驚人。
在訓練過程中,我們設定每 300 步生成一組樣本(共六張圖),藉此密切觀察角色還原度。除了確認萌樂標誌性的銀髮、藍色髮尖與精緻的綠色系服裝是否完美重現,重點還在於觀察是否會發生「風格污染」——即觀察模型是否會強行將動漫特徵套用在無關的提示詞(如男孩或真人)上。經過實測,Z-Image-Turbo 在學習畫風方面非常強勢,對於髮型、瞳色等關鍵設定的掌握遠比 SDXL 穩定。我發現訓練的甜蜜點大約落在 1500 至 2100 步之間,最終我選擇了 1800 步的模型作為成品,其生成的圖像不僅能精準還原角色 IP 設定,也保持了極佳的畫面細緻度,並且不汙染無關緊要的畫面元素。
📝 嘗試操作前請先安裝好 AI Toolkit by Ostris 軟體環境,並確保電腦擁有 NVIDIA 顯示卡,且至少擁有 12 GB(含)以上的 VRAM 及 32 GB(含)以上的 RAM,您可以參考我先前的教學文章建置環境,安裝後請透過我提供的批次檔解決方案啟動軟體。
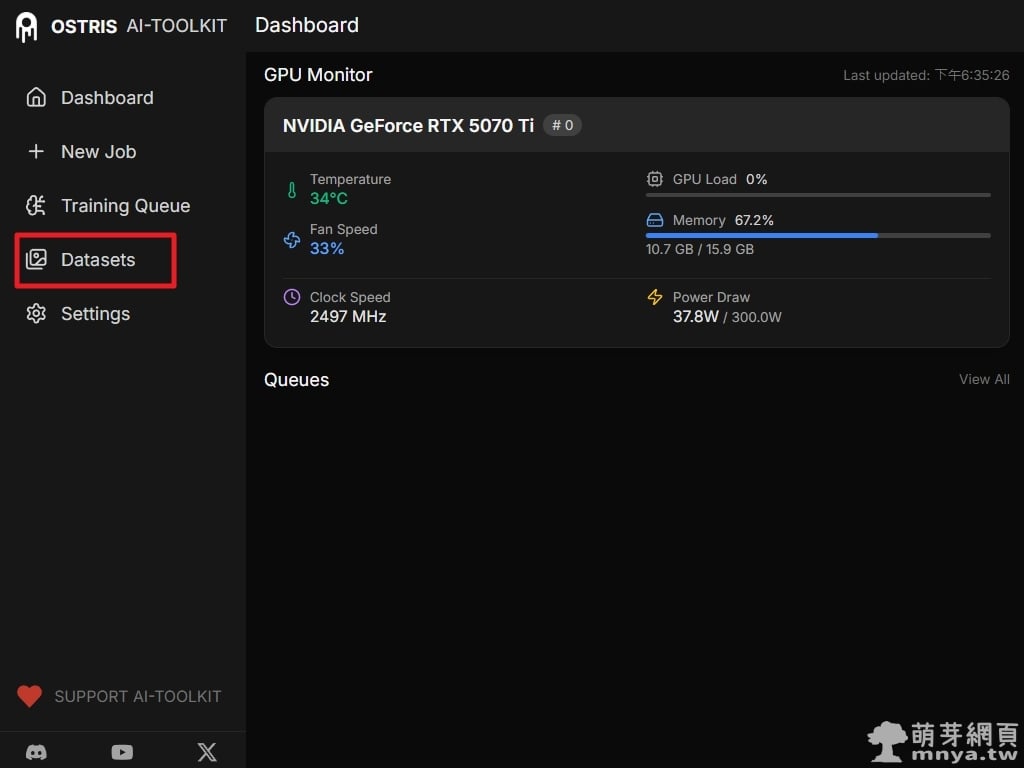
▲ 進入 AI Toolkit 的 Dashboard 儀表板,可以即時監測 GPU 狀態。本環境使用 NVIDIA GeForce RTX 5070 Ti,可見顯存容量為 16GB。在訓練前,請確保顯卡驅動與 CUDA 環境已正確配置。先進入左側「Datasets」建立訓練用資料集。
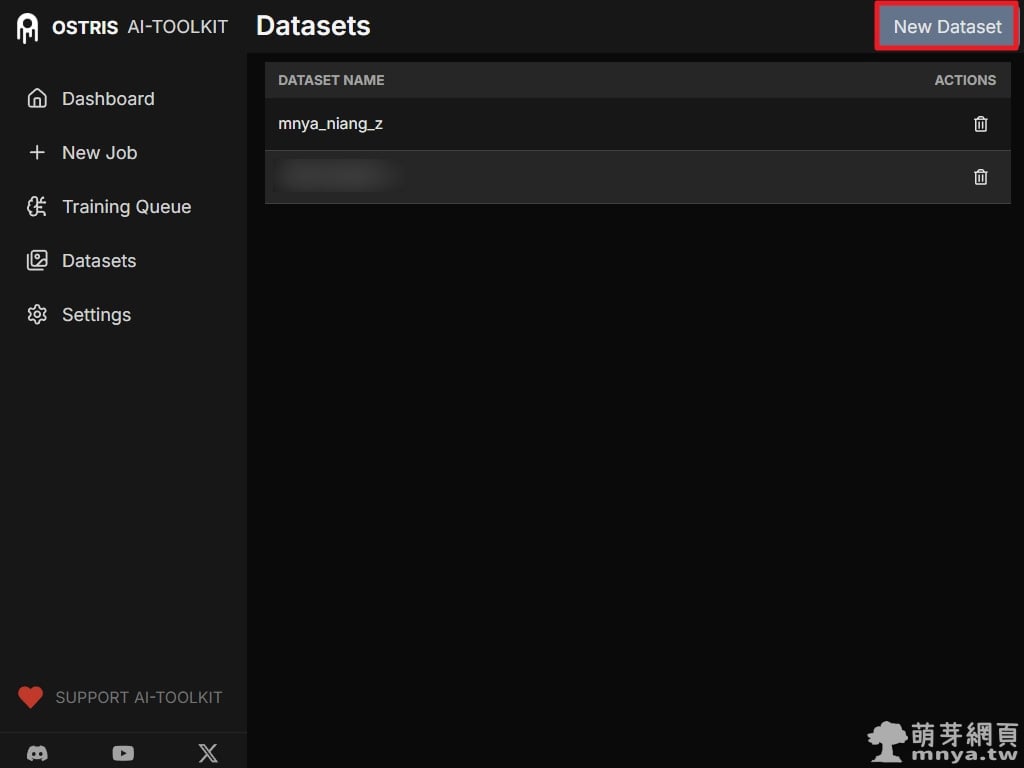
▲ 這是資料集管理介面。在這裡可以看到目前已建立的資料集清單,點擊右上角的「New Dataset」準備建立屬於萌樂的訓練資料。
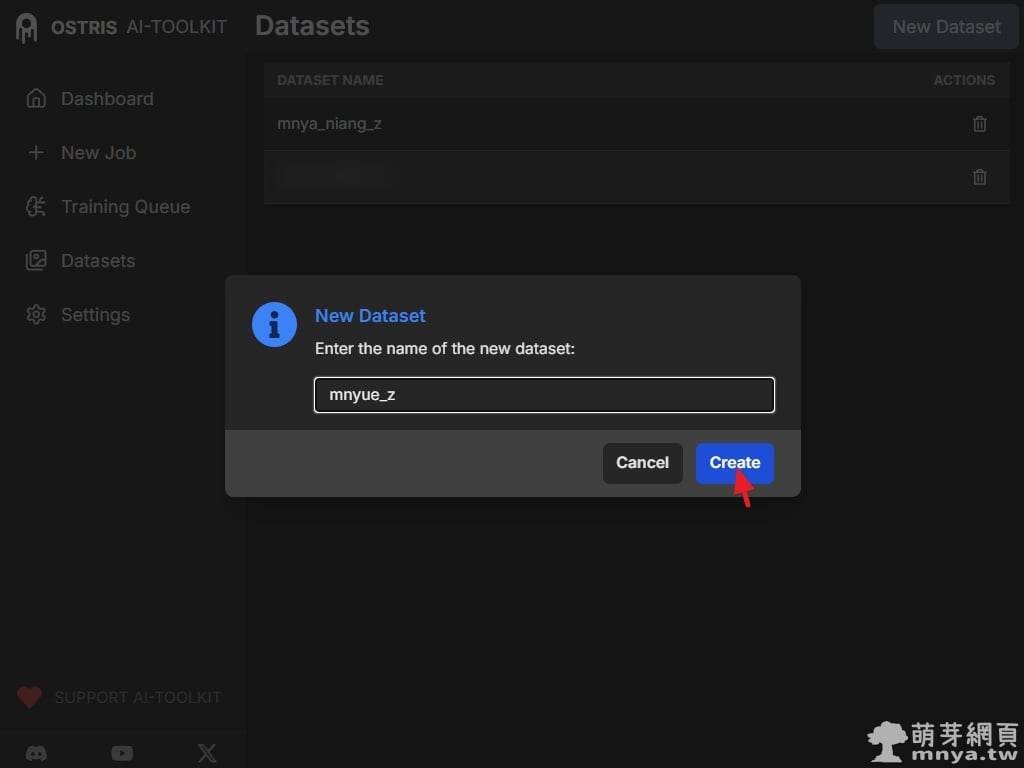
▲ 在跳出的視窗中輸入資料集名稱,本範例命名為 mnyue_z。建議名稱使用小寫英文與底線搭配,這邊 _z 代表是用於訓練 Z-Image 專用的 LoRA 模型的資料集,以便於後續在路徑管理與 YAML 配置中識別。
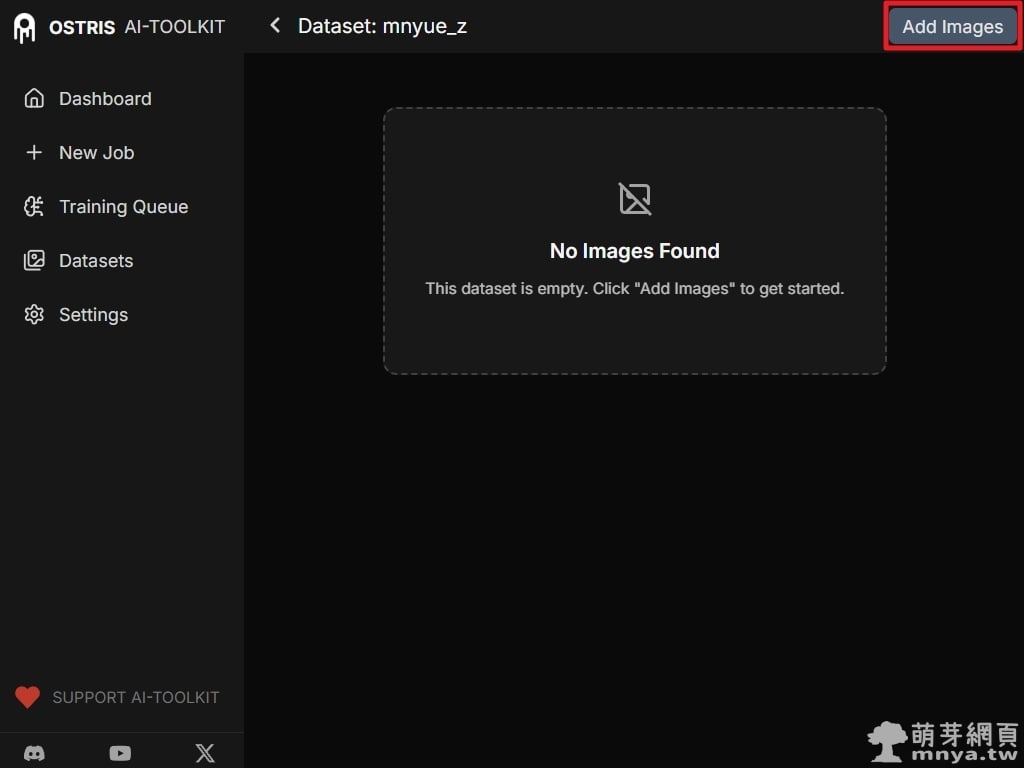
▲ 進入剛建立好的資料集頁面,目前顯示「No Images Found」,代表尚未上傳素材。點擊右上角的「Add Images」按鈕準備匯入事先準備好的萌樂圖片。
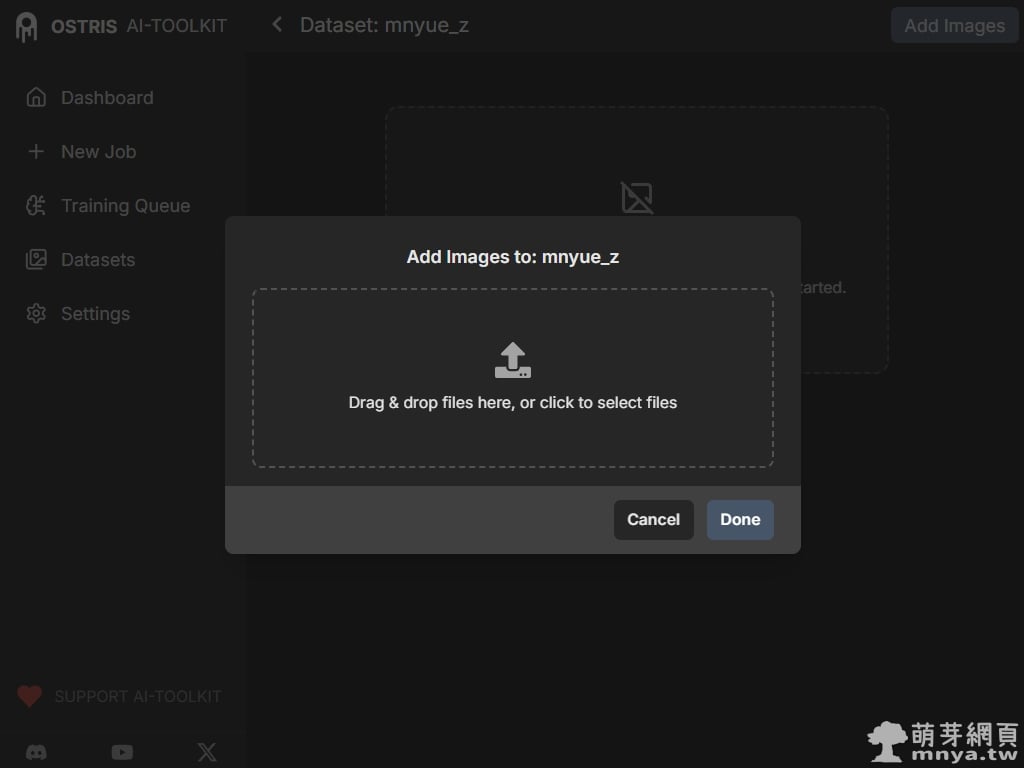
▲ 將準備好的 15 張圖片直接拖曳至上傳區塊。AI Toolkit 會自動處理檔案,上傳完成後點擊「Done」即可看到圖片預覽,這是訓練最基礎也最重要的一步。
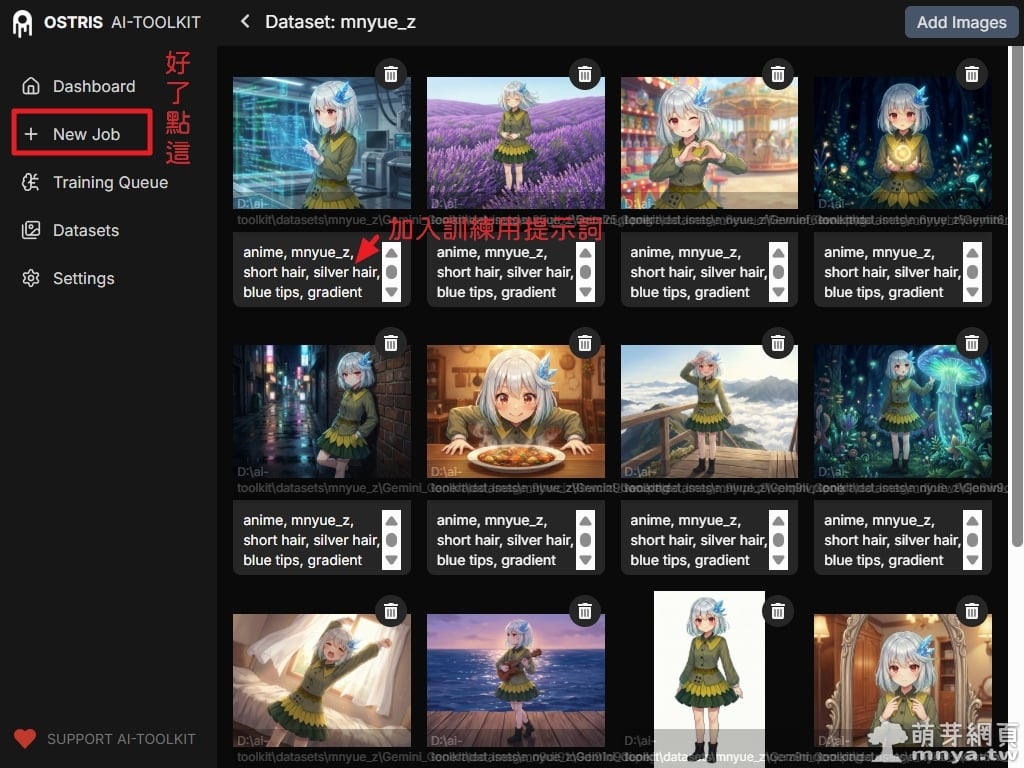
▲ 圖片上傳後,點擊下方文字區塊即可加入「訓練用提示詞」(Captions)。這一步能讓 AI 建立圖像內容與標籤之間的對應關係,我們在這裡詳細描述了萌樂的銀髮、藍色髮尖等特徵,風格方面開頭寫上 anime 就行了,不要有過多無關緊要的提示詞,背景、動作、表情、光影等跟人物特徵無關的敘述就不要放到訓練用提示詞中,另外每張圖我都是用一樣的訓練用提示詞。好了點左邊「New Job」建立新工作。
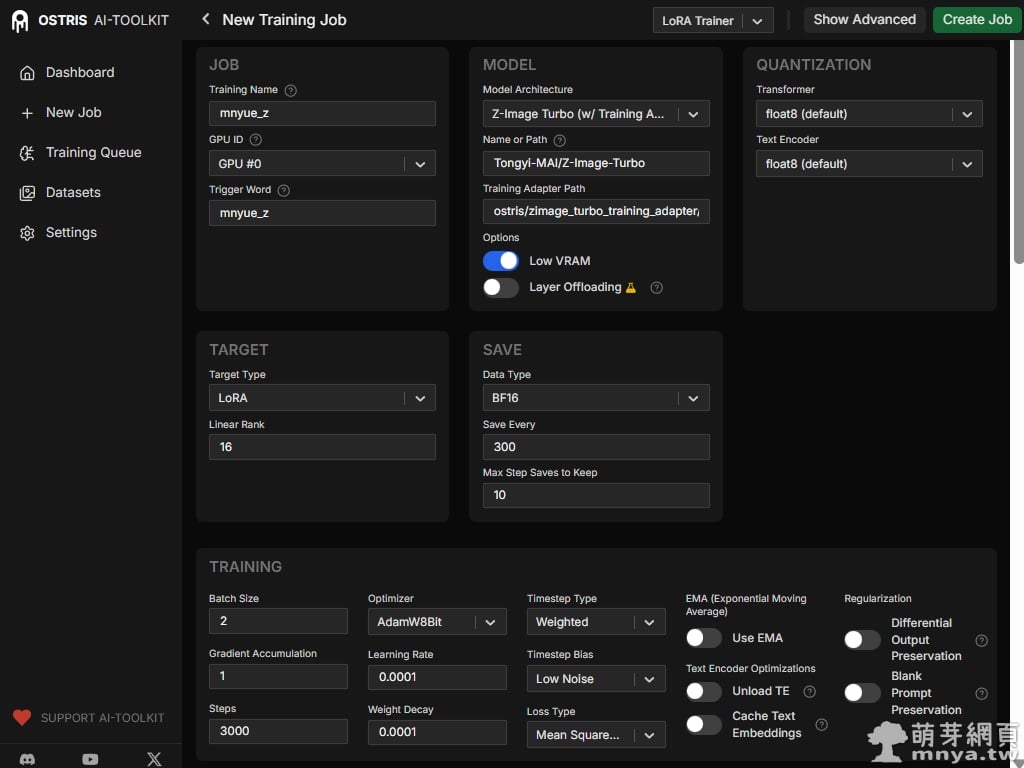
▲ 開始建立新工作,這是訓練的核心設定頁面,特別是針對模型架構與顯存優化的配置。在 JOB 區塊中,我們將觸發詞(Trigger Word)設為 mnyue_z(也就是以後生成時要加入的角色提示詞喔!)。最重要的部分在於 MODEL 與 QUANTIZATION 的設置:為了在 16GB VRAM 的 5070 Ti 上順利執行,我們啟用了 Low VRAM 模式,並將 Transformer 與 Text Encoder 全部設為 float8 量化。此外,Model Architecture 必須精確選擇 Z-Image Turbo,並掛載官方提供的 training_adapter 以確保訓練過程能正確適應 Turbo 模型的步數特性,如果電腦沒有主模型檔案,軟體都會自動下載不用擔心。在 TRAINING 參數頁面,我們設定了高效率的訓練方案。批次大小(Batch Size)設定為 2,如果 VRAM 不足請降低這個數值,反過來說,VRAM 充足則可以增加以加快訓練速度。訓練總步數(Steps)定為 3000。為了達到最佳的記憶體回收與運算速度,我們選用了 AdamW8Bit 優化器,搭配 0.0001 的學習率。
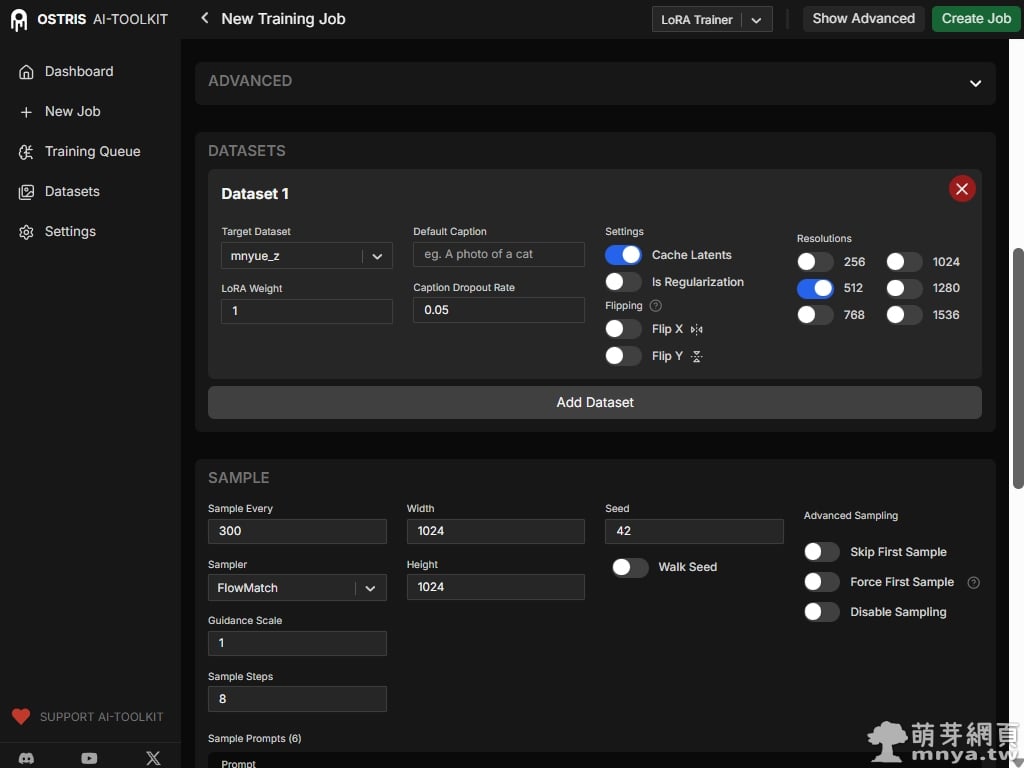
▲在 Datasets 子分頁中,一定要選中剛剛建立的訓練資料集,訓練解析度統一設為 512,並開啟 Cache Latents 以加速後續迴圈。SAMPLE 決定了樣本圖片的生成設定。我們設定 Sample Every 為每 300 步生成一組測試圖,並固定 Seed 為 42 以便對比各階段的細微變化。由於是 Turbo 模型,Sample Steps 僅需設為 8 步即可獲得清晰的採樣結果。
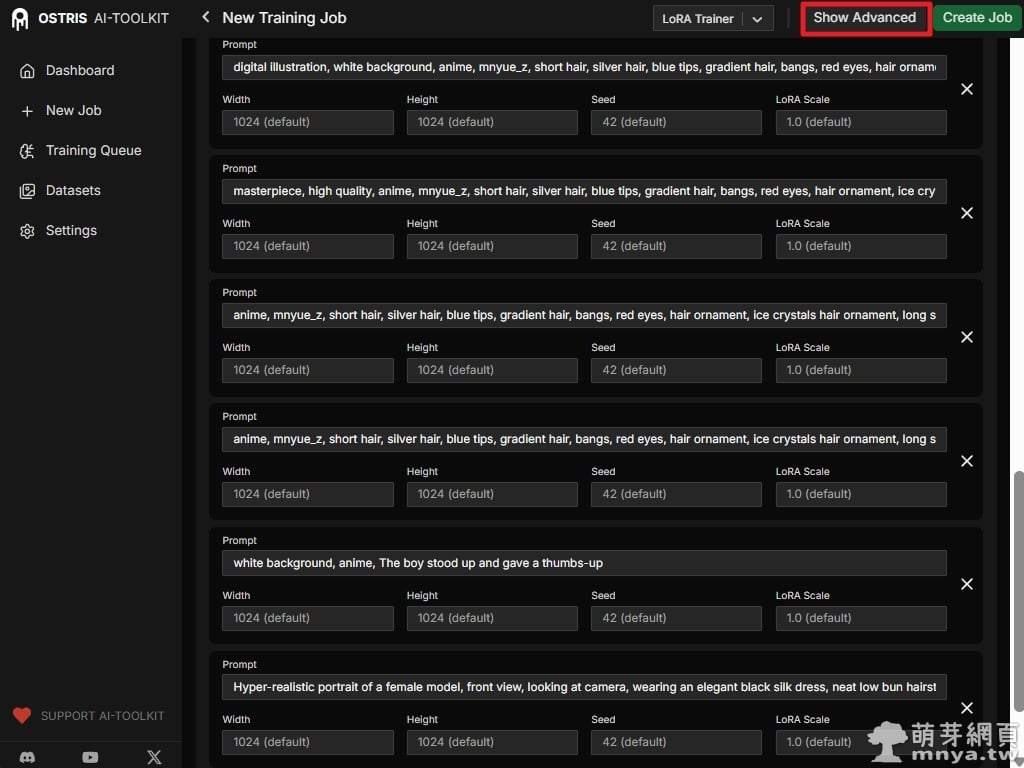
▲這裡的提示詞設計非常有考究:前幾組針對萌樂的特徵還原,只有稍微變換品質提示詞與加上特殊情境,而後兩組則故意放入「動漫風格男孩」與「超寫實女性模特兒」的提示詞。這是為了監控模型是否發生污染(Bleeding),若 LoRA 過度強勢,會導致連寫實照片都變成萌樂的動漫風格。這邊設定了六組提示詞,代表之後每 300 步會生成一組共六張的樣本圖。接著點右上「Show Advanced」查看完整配置。
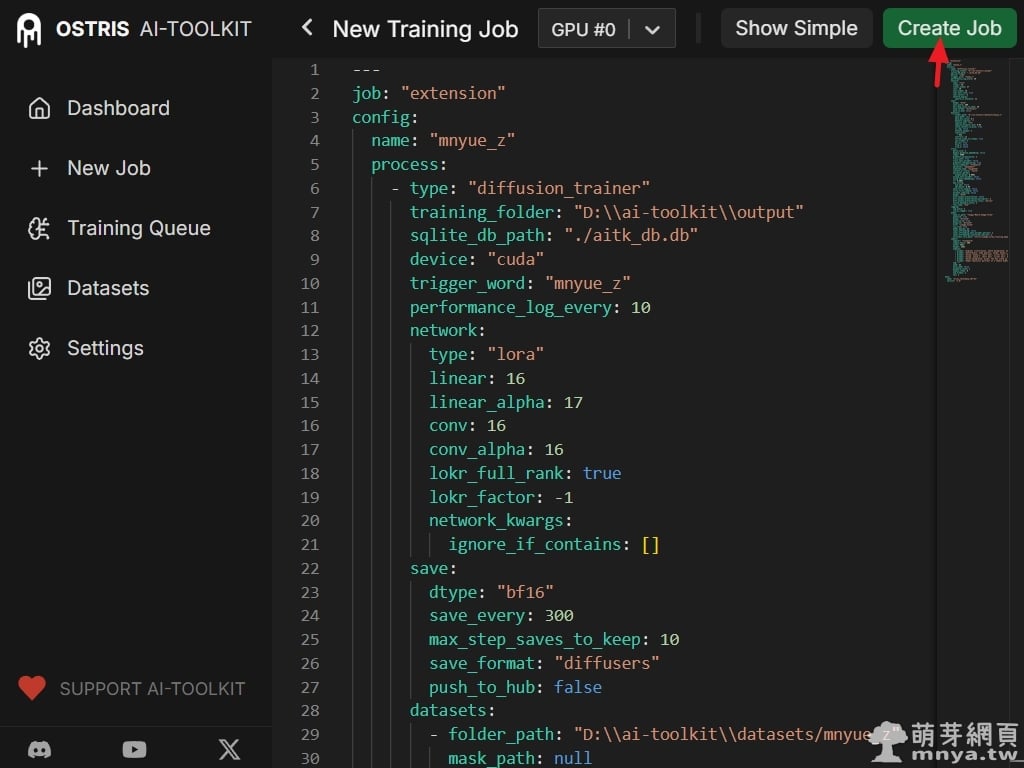
▲ 確認 YAML 配置原始碼,這包含了剛才手動設定的所有訓練細節,如 trigger_word、network 權重參數、save_every 等步數設定。您可以將配置備份或者貼上他人提供的配置參數。確認無誤後,點擊右上角的「Create Job」按鈕,正式建立該 LoRA 訓練任務。
🎁 如果您想要更快速開始,並且好奇我使用的「完整樣本提示詞」(其中也包含「訓練用提示詞」),可以透過以下贊助方案下載到我此次使用的 mnyue_z.yaml YAML 訓練配置檔,可直接在軟體中匯入即可使用,不用再對照文章截圖中的設定囉!提示詞的部分就依照您的需求改成您要訓練之角色的特徵即可,下載點 👉
【AI Toolkit訓練參數】訓練二次元動漫角色 Z-Image-Turbo 專用 LoRA 模型參數 YAML 檔
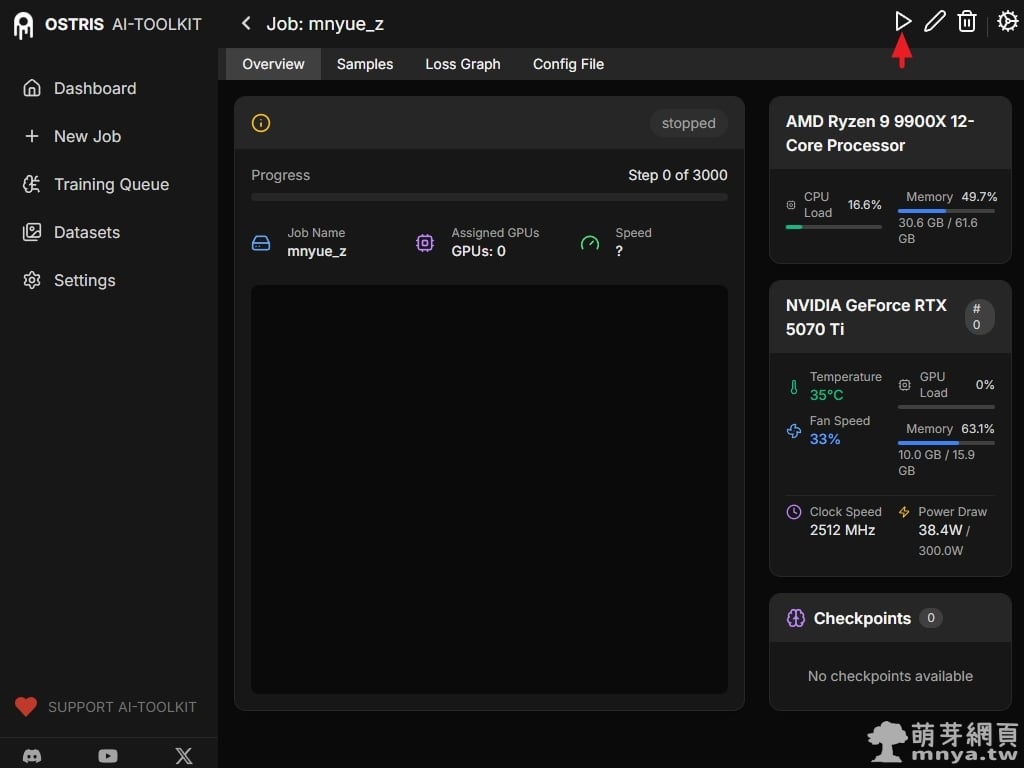
▲ 進入任務詳情頁面,狀態顯示為「stopped」。此時只需要點擊右上角的「播放(Start)」圖示,AI Toolkit 就會開始載入模型並進入正式的訓練流程。
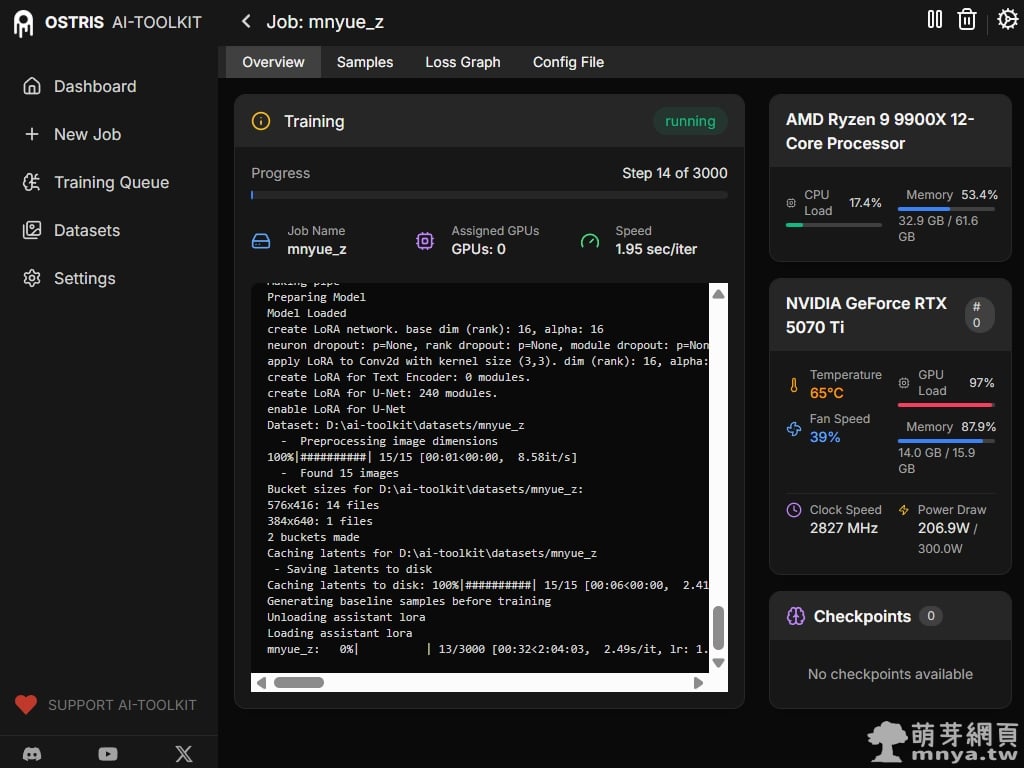
▲ 訓練正式開始!控制台會輸出詳細的日誌,包含 LoRA 網路的建立、U-Net 模組的啟用等。觀察右側監測器,RTX 5070 Ti 的顯存佔用來到 14.0GB(約 91.8%),GPU 負載達到 97%,代表顯卡效能正全力投入訓練中。
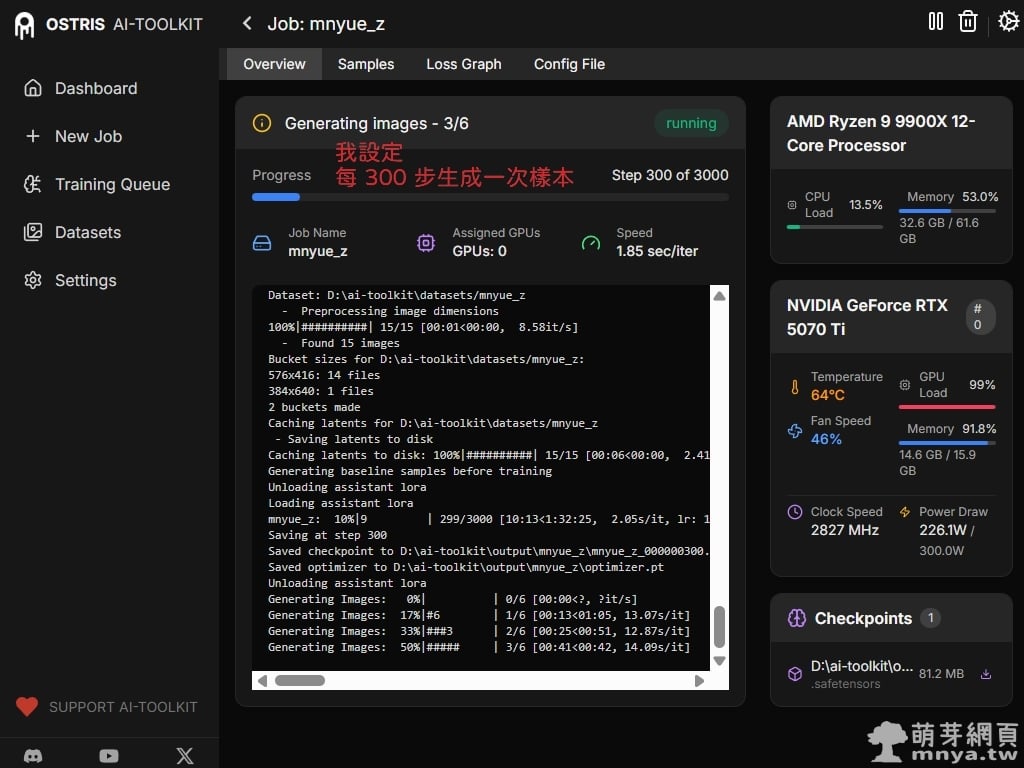
▲ 訓練進行到第 300 步時,系統會自動啟動樣本生成任務。此時系統正在根據我們預設的提示詞產生樣本圖,讓我們能即時評估當前訓練階段的效果。
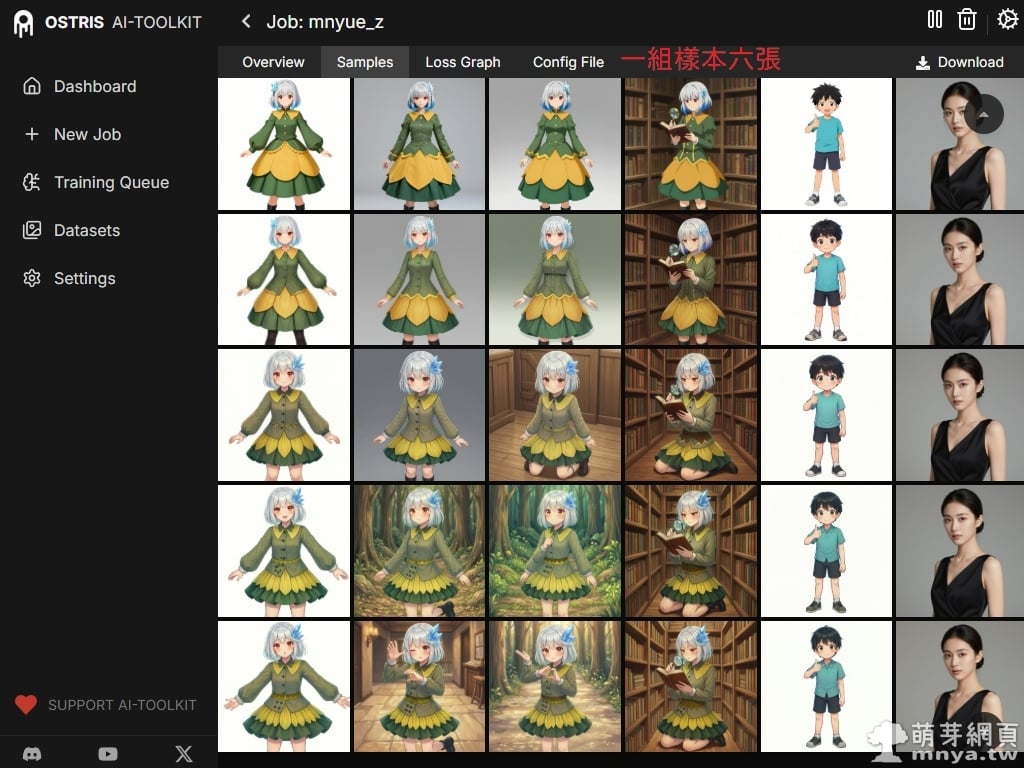
▲ 在「Samples」頁面中,我們可以看到每 300 步生成的一組六張樣本圖。早期的樣本可能在角色還原度上較為鬆散,但隨著步數增加,角色的特徵會愈發明顯且穩定。
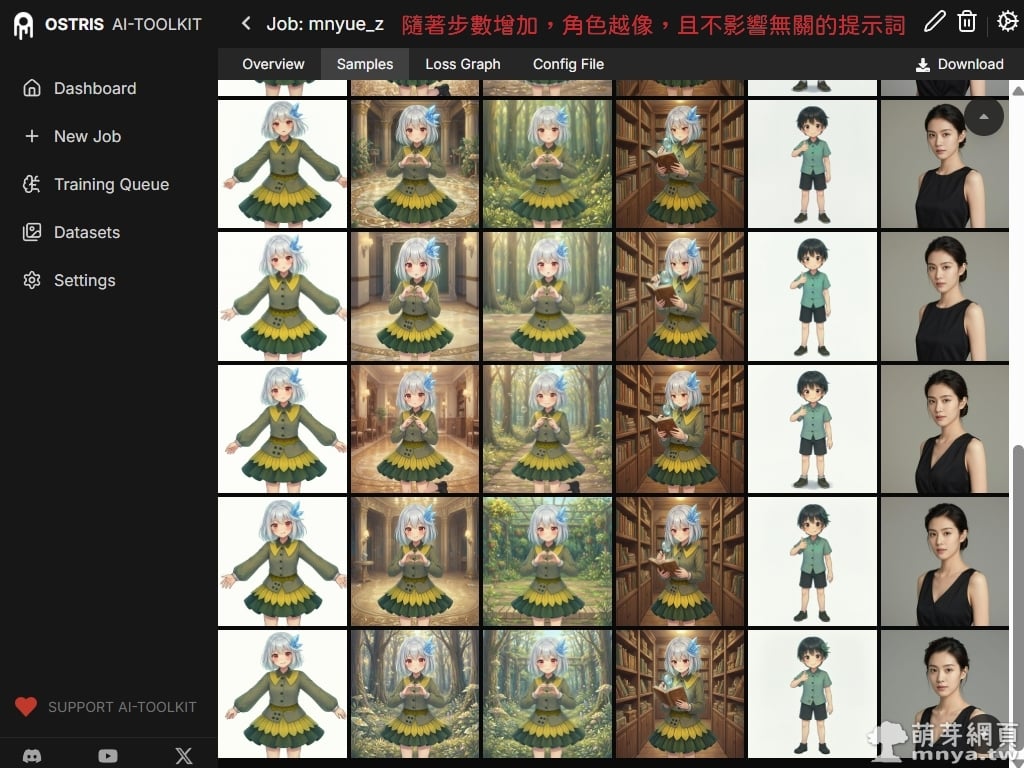
▲ 這是非常關鍵的收斂觀察:隨著步數增加,萌樂的銀髮、紅眼與特有服飾越來越像原始設定。同時觀察右側兩欄的男孩與真人測試圖,可以看到他們依然保持原有的風格,並未受到萌樂特徵的干擾,代表訓練標籤編寫得宜,沒有產生嚴重的污染問題。
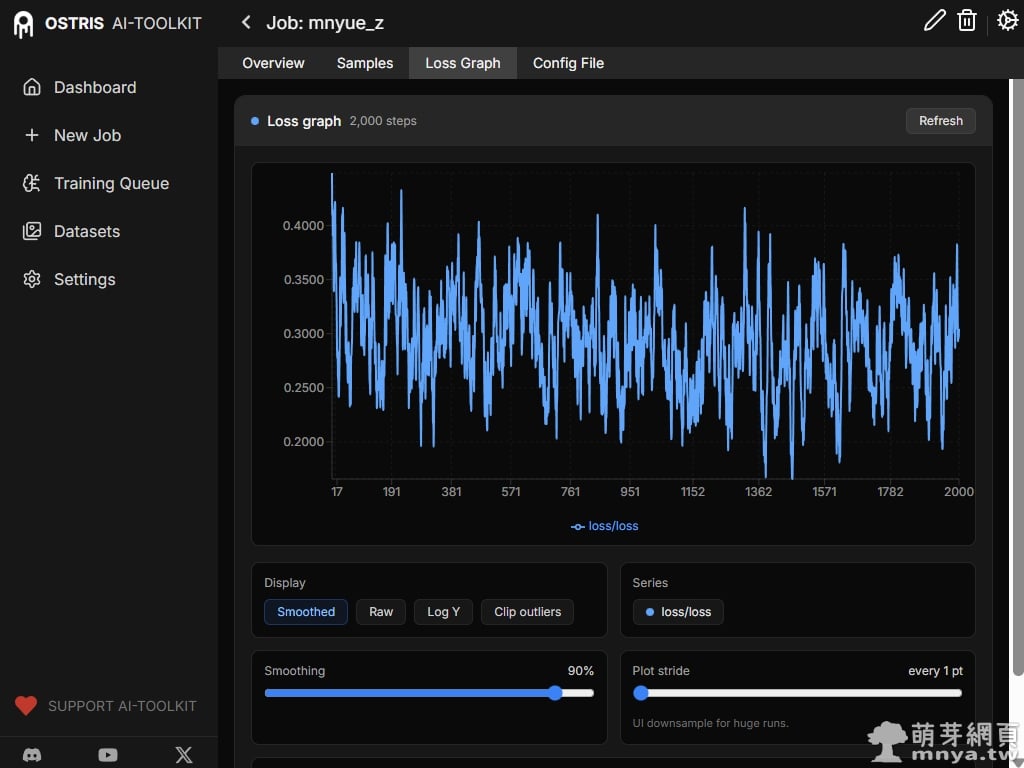
▲ 「Loss Graph」分頁展示了訓練的損失函數曲線。雖然曲線看起來充滿波動(這是擴散模型訓練的常態),但整體趨勢是穩定維持在一定區間內,沒有出現梯度爆炸或異常飆升,代表訓練過程相當健康。
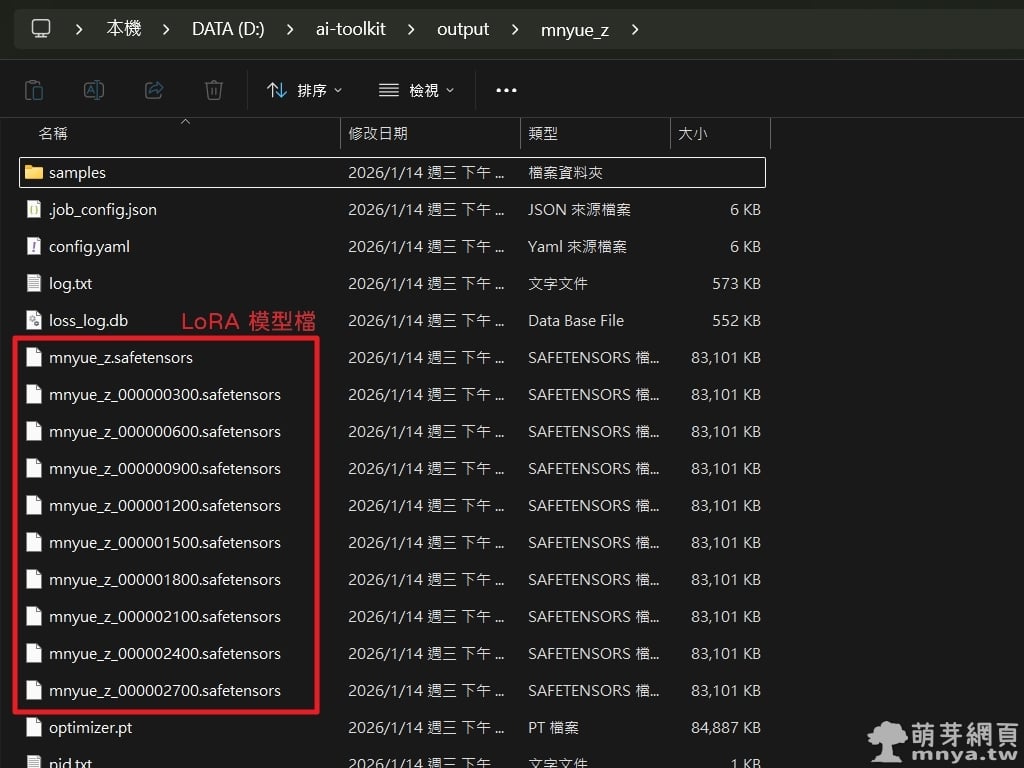
▲ 訓練完成後,我們可以在輸出資料夾(路徑為 ai-toolkit\output\<訓練名稱>)中看到生成的 LoRA 模型檔(.safetensors)。系統依照我們設定的步數儲存了多個權重檔,每個大小約為 83,101 KB (約 81 MB)。經過對比後,1800 步的模型效果最為滿意。

▲ 最後展示一張由 1800 步模型生成的最終成品:萌樂在風景優美的陽台上與飛鳥互動。可以看到 Z-Image-Turbo 對於角色 IP 的還原極為精準,無論是髮飾的透明質感還是層次豐富的裙擺細節都學習得非常完美!甚至感覺得出來 Nano Banana Pro 的畫風,實在厲害!我的硬體設備生成一張大概只花 12 ~ 15 秒間(原始大小為 1280 x 960 px),可以比 Nano Banana Pro 更快產圖,而且因為是本地生成,毫無限制,自由度超級高。





 《上一篇》ComfyUI x Wildcards:動態提示詞、透過 TXT 製作提示詞詞庫
《上一篇》ComfyUI x Wildcards:動態提示詞、透過 TXT 製作提示詞詞庫  《下一篇》ChatGPT 翻譯:AI 驅動的跨語言工具,支援 28 種主流語言
《下一篇》ChatGPT 翻譯:AI 驅動的跨語言工具,支援 28 種主流語言 








留言區 / Comments
萌芽論壇