AI 繪圖會需要編寫大量的提詞(咒語),然而常常都是反向提詞遠遠多於提詞,以提高最終產出成品的品質,那有沒有辦法不要輸入這麼多反向提詞就能生成出好作品?網上就有熱心網友分享了名為 EasyNegative 的 Negative Embedding(即用在反向提詞的 Textual Inversion),這邊我以自己常用的工具 Stable Diffusion web UI 來教大家如何使用!
※ 備註:大概只適用於產生二次元動漫風格影像的模型,實際生成效果可能因為參數及模型不同而有所差異,請依照個人需求斟酌使用。懶人包並非唯一答案,您或許也可以找到最適合自己的「一堆反向提詞」😉。
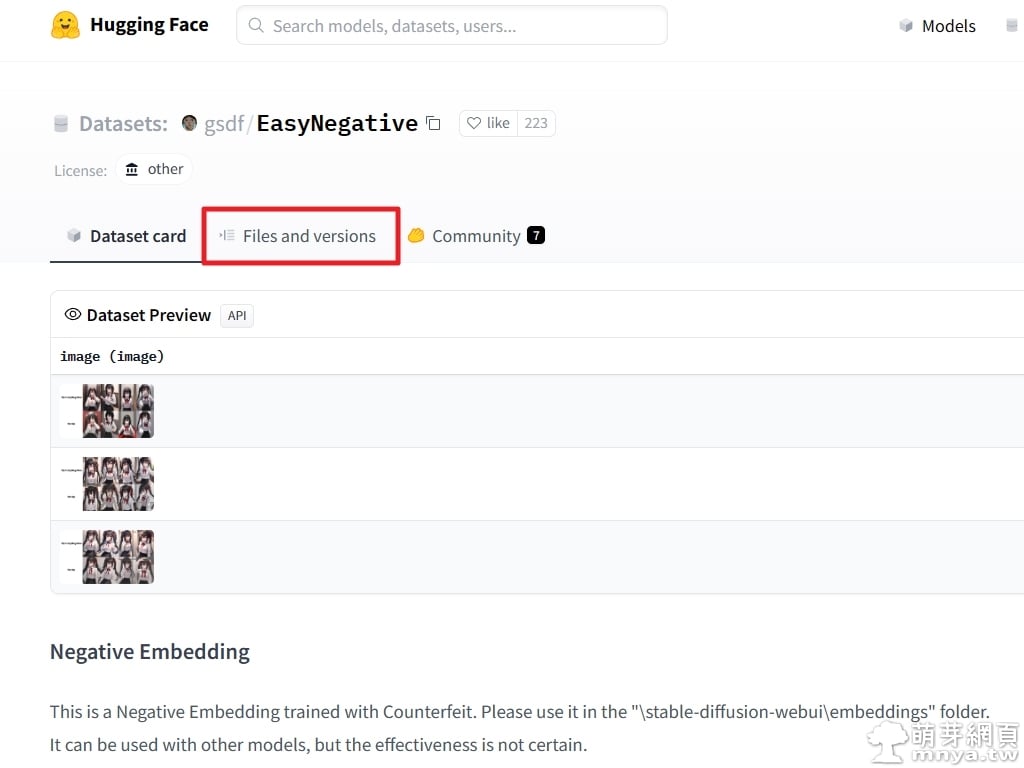
▲ 首先來到 EasyNegative 的 Hugging Face 頁面,感謝 gdgsfsfs 熱心提供這麼好用的 Textual Inversion!點「Files and versions」。
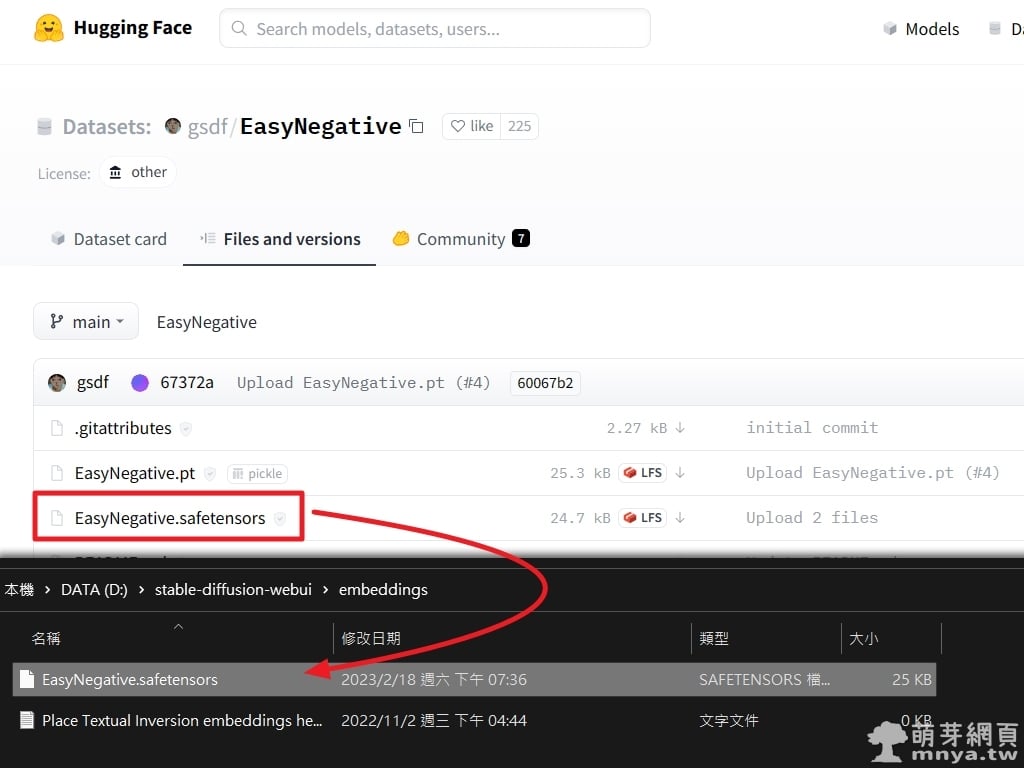
▲ 將「EasyNegative.safetensors」下載後放到 stable-diffusion-webui\embeddings 路徑之下。
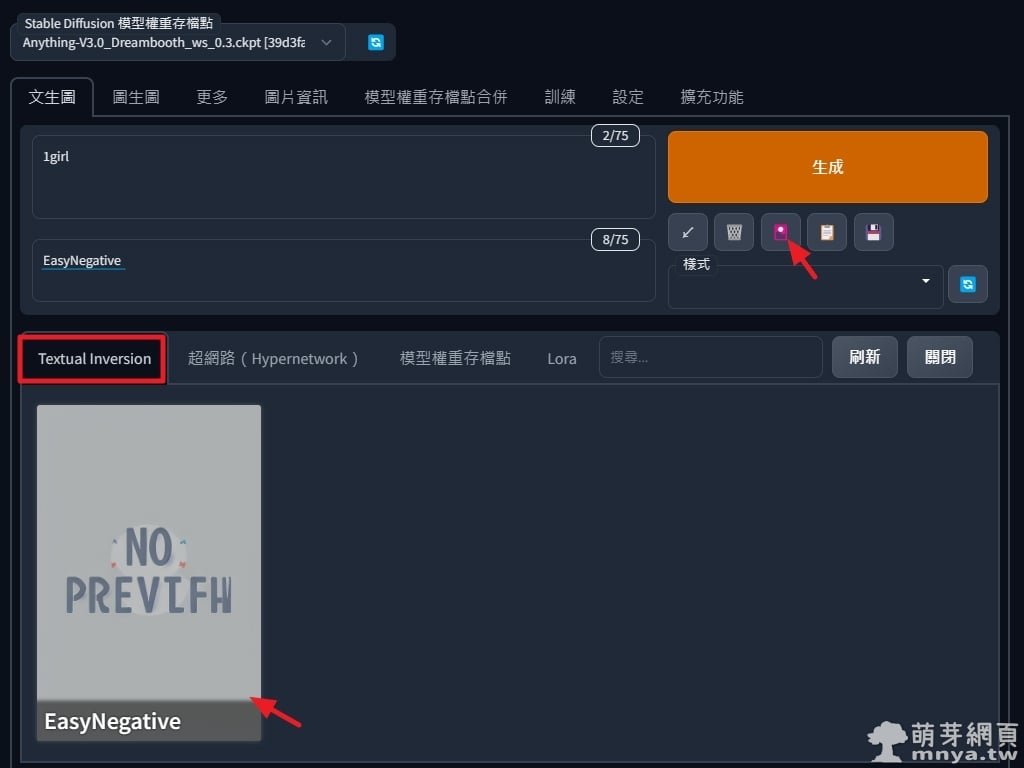
▲ 進入 Stable Diffusion web UI,提詞先簡單輸入 1girl 稍後要做測試,接著點右側「🎴」(Show extra networks)按鈕,選「Textual Inversion」,游標先點一下反向提詞區塊再點「EasyNegative」,這樣就成功將 EasyNegative 應用在反向提詞了!(※ 如果沒看到「EasyNegative」可以刷新一下~)
提詞只有 1girl,種子碼及其他參數固定,來看輸出結果:

▲ 左圖完全沒有反向提詞,右圖是用了一大堆的反向提詞。

▲ 左圖反向提詞為 EasyNegative,右圖反向提詞為 (EasyNegative),也就是 1.1 倍權重的 EasyNegative。
接著我試著搭配自訓練喜多郁代的 LoRA 跟自己撰寫的提詞,成品如下:

▲ 反向提詞皆為 (EasyNegative),種子碼不同,發現效果跟一大堆的反向提詞差距不多。
這個是比較懶人的做法,請您依照自己的需求與使用情境服用。





 《上一篇》Stable Diffusion web UI x ControlNet:AI 參考指定影像構圖進行重新繪圖
《上一篇》Stable Diffusion web UI x ControlNet:AI 參考指定影像構圖進行重新繪圖  《下一篇》Stable Diffusion web UI x OpenPose Editor:自訂骨骼動作、識別姿勢、收藏骨架
《下一篇》Stable Diffusion web UI x OpenPose Editor:自訂骨骼動作、識別姿勢、收藏骨架 







留言區 / Comments
萌芽論壇