我知道大家等這篇圖文教學很久了!站長這邊一直在等軟體跟時機成熟,網路上有比較多的參考資料跟資源時才開始研究 LoRA 訓練。過去我自己最常使用的是超網路(Hypernetwork)訓練小模型來達成特定畫風或人物(物件)的繪製,但訓練步數要 2000 至 10000 步,我都設定每 500 步存一個小模型,訓練完後自己去挑選 LOSS 值較低且效果較佳的模型,整個流程相當耗時費力(通常耗時約兩至三小時),成功率不一定很高。
而 LoRA 訓練小模型有特定的公式,每張圖最少訓練 100 步,總步數不低於 1500 步,也就是說建議訓練圖片大於 15 張,若小於則用這個公式計算每張步數:「1500/圖片張數=每張訓練步數」,舉例來說,我訓練的圖片共 10 張,那我就是每張訓練 150 步即可,只要依照這個公式去訓練產生的小模型效果就會很好,若不好就是要去檢查訓練圖片是否合適,圖片品質很重要(建議都用 R-ESRGAN 4x+ Anime6B 去跑一次去除雜訊及優化),尺寸統一都是 1:1,而我就設為基本的 512 x 512 px 效果就很好了!如果顯卡夠力可以試著 768 x 768 px 的圖片拿去訓練看看!訓練 LoRA 最低顯示卡 VRAM 為 7G!所以市售 8G、12G VRAM 的顯卡都適合拿來用。
LoRA 訓練出來的小模型檔案不大,頂多 100 多 MB 而已,而且每訓練一個模型只要不到十分鐘,很快就能讓 AI 學會一個物件如何繪製,非常強大,實際產圖成功率極高,能非常接近我想要的模樣,二次元動漫風格用 LoRA 訓練出來的模型繪製非常合適,這次就以「孤獨搖滾!」(ぼっち・ざ・ろっく!,Bocchi the Rock!)中的登場角色「喜多郁代」(きた いくよ,Kita Ikuyo)來做訓練,並撰寫這篇教學給大家參考。
使用軟體列表
1. Stable Diffusion web UI:處理訓練圖片、AI 繪圖用
2. Kohya's GUI:訓練 LoRA 模型※ 備註:請先點入個別軟體連結去依照教學安裝好,熟悉軟體介面操作後再往下看教學。
為了準備訓練圖片,我以 D 碟作為主要工作位置,資料夾之安排如下:
資料夾安排
📂 D:\ai\source -> 訓練圖片放的資料夾(已經去雜訊跟裁切為 1:1 比例)
📂 D:\ai\model -> LoRA 模型輸出位置
📂 D:\ai\destination -> 整理過後訓練圖片放的位置,訓練時讀取該資料夾(包含 txt 提詞註記)
這次我共準備了 17 張訓練圖片,每張 100 次訓練,預計 1700 步即可完成 LoRA 模型訓練。
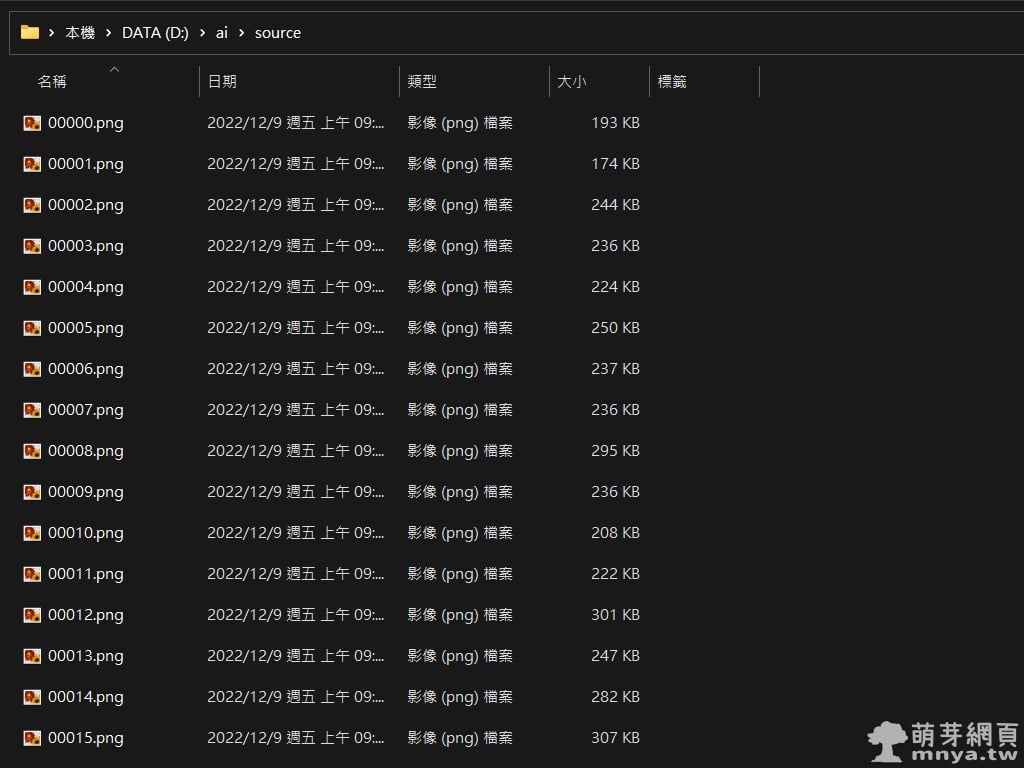
▲ 這是我已經裁切處理好的 17 張要訓練的圖片,都是喜多郁代!特別注意,建議多個角度、表情,以臉為主,全身的圖幾張就好,這樣訓練效果最好。
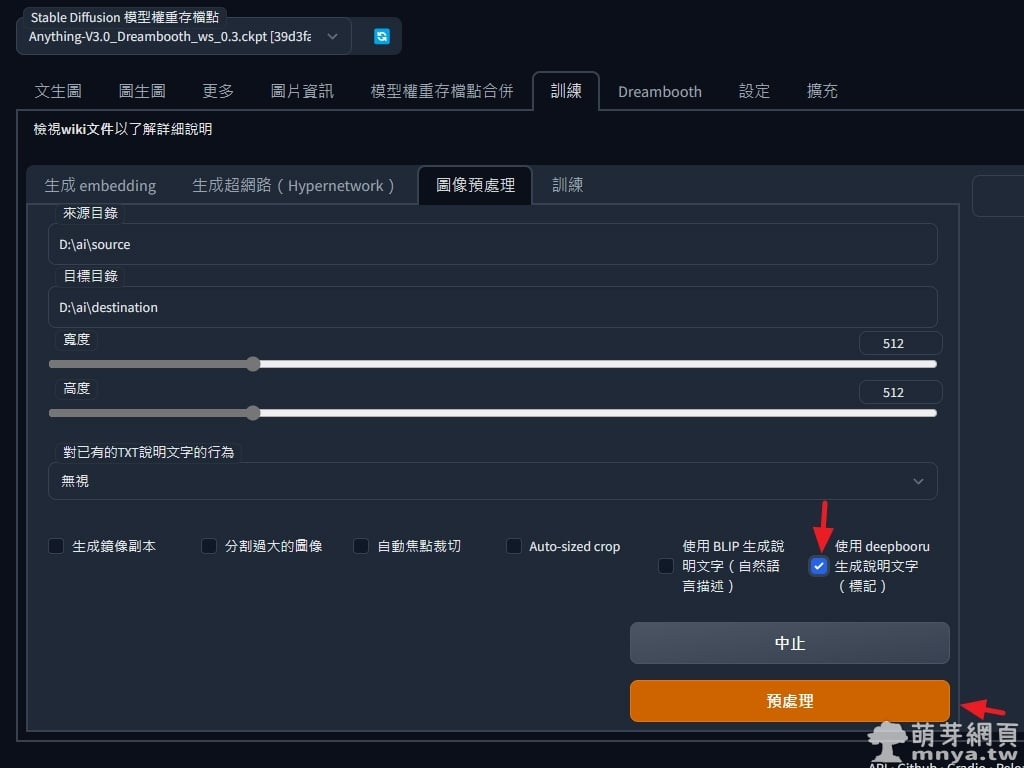
▲ 先使用 Stable Diffusion web UI 產生提詞註記 txt 檔,到「訓練」→「圖像預處理」這邊將來源及目標目錄寫清楚,將「使用 deepbooru 生成說明文字(標記)」打勾,最後按「預處理」。
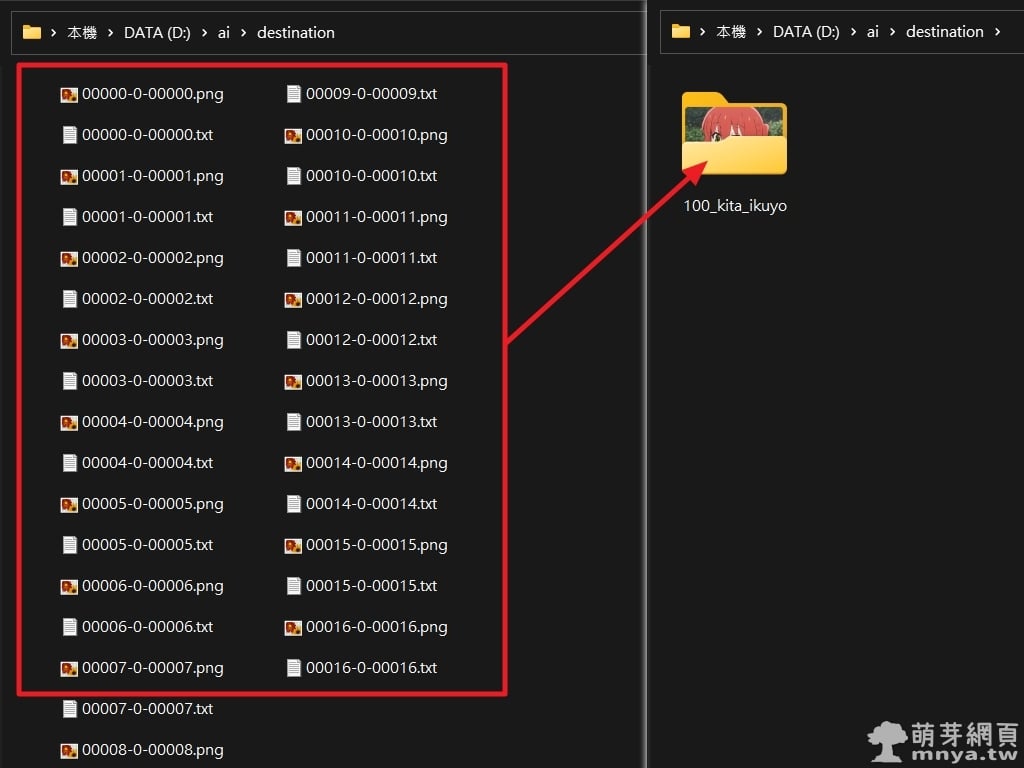
▲ 最後可以在目標目錄看到搭配 txt 的訓練圖片,將它們整理到一個子目錄,用「每張步數+底線+模型名稱」命名,前文已經告知每張步數的計算公式了!依照著算就不會有問題囉!這邊我命名「100_kita_ikuyo」,軟體會直接讀取每張步數。
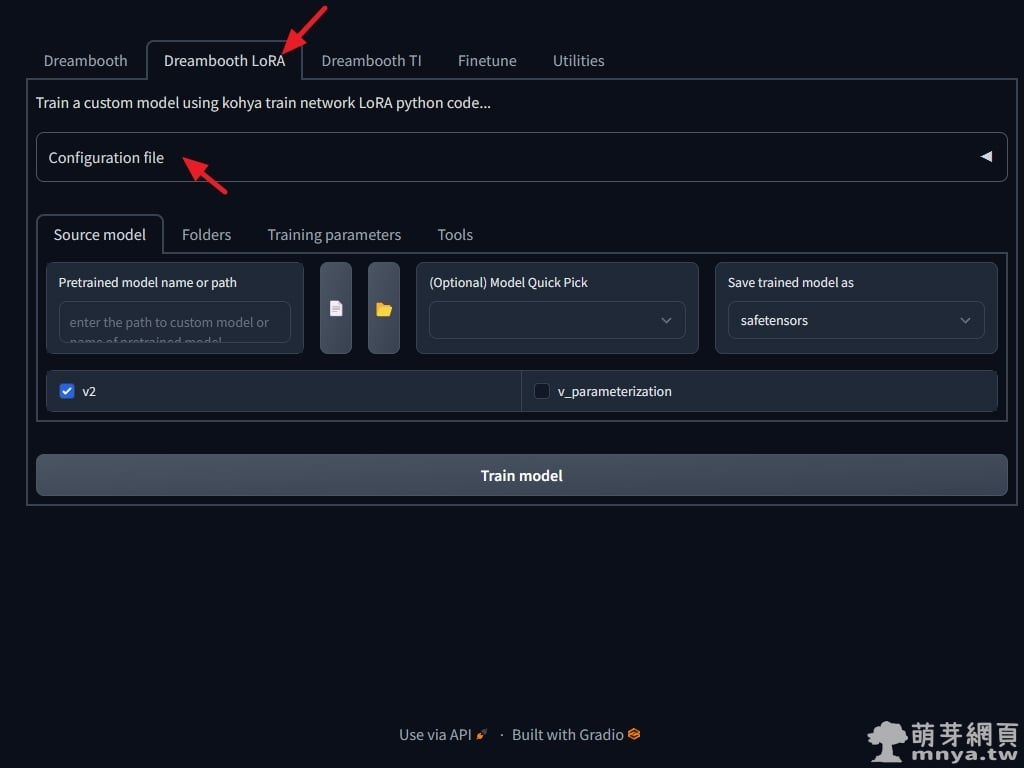
▲ 再來切換到 Kohya's GUI,到「Dreambooth LoRA」點「Configuration file」載入快速設定檔案。這邊我有參考外國網友的教學整理出以下兩種快速設定檔,請複製全文存成 .json 並在這邊載入。(※ 載入一種設定檔就好)
LoraBasicSettings.json (基礎設定檔)
{
"pretrained_model_name_or_path": "runwayml/stable-diffusion-v1-5",
"v2": false,
"v_parameterization": false,
"logging_dir": "",
"train_data_dir": "D:/ai/destination",
"reg_data_dir": "",
"output_dir": "D:/ai/model",
"max_resolution": "512,512",
"learning_rate": "0.0001",
"lr_scheduler": "constant",
"lr_warmup": "0",
"train_batch_size": 2,
"epoch": "1",
"save_every_n_epochs": "1",
"mixed_precision": "fp16",
"save_precision": "fp16",
"seed": "1234",
"num_cpu_threads_per_process": 2,
"cache_latents": true,
"caption_extension": ".txt",
"enable_bucket": false,
"gradient_checkpointing": false,
"full_fp16": false,
"no_token_padding": false,
"stop_text_encoder_training": 0,
"use_8bit_adam": true,
"xformers": true,
"save_model_as": "safetensors",
"shuffle_caption": false,
"save_state": false,
"resume": "",
"prior_loss_weight": 1.0,
"text_encoder_lr": "5e-5",
"unet_lr": "0.0001",
"network_dim": 128,
"lora_network_weights": "",
"color_aug": false,
"flip_aug": false,
"clip_skip": 2,
"gradient_accumulation_steps": 1.0,
"mem_eff_attn": false,
"output_name": "Addams",
"model_list": "runwayml/stable-diffusion-v1-5",
"max_token_length": "75",
"max_train_epochs": "",
"max_data_loader_n_workers": "1",
"network_alpha": 128,
"training_comment": "",
"keep_tokens": "0",
"lr_scheduler_num_cycles": "",
"lr_scheduler_power": ""
}LoraLowVRAMSettings.json (低VRAM設定檔)
{
"pretrained_model_name_or_path": "runwayml/stable-diffusion-v1-5",
"v2": false,
"v_parameterization": false,
"logging_dir": "",
"train_data_dir": "D:/ai/destination",
"reg_data_dir": "",
"output_dir": "D:/ai/model",
"max_resolution": "512,512",
"learning_rate": "0.0001",
"lr_scheduler": "constant",
"lr_warmup": "0",
"train_batch_size": 1,
"epoch": "1",
"save_every_n_epochs": "1",
"mixed_precision": "fp16",
"save_precision": "fp16",
"seed": "1234",
"num_cpu_threads_per_process": 2,
"cache_latents": true,
"caption_extension": ".txt",
"enable_bucket": false,
"gradient_checkpointing": true,
"full_fp16": false,
"no_token_padding": false,
"stop_text_encoder_training": 0,
"use_8bit_adam": true,
"xformers": true,
"save_model_as": "safetensors",
"shuffle_caption": false,
"save_state": false,
"resume": "",
"prior_loss_weight": 1.0,
"text_encoder_lr": "5e-5",
"unet_lr": "0.0001",
"network_dim": 128,
"lora_network_weights": "",
"color_aug": false,
"flip_aug": false,
"clip_skip": 2,
"gradient_accumulation_steps": 1.0,
"mem_eff_attn": true,
"output_name": "Addams",
"model_list": "runwayml/stable-diffusion-v1-5",
"max_token_length": "75",
"max_train_epochs": "",
"max_data_loader_n_workers": "1",
"network_alpha": 128,
"training_comment": "",
"keep_tokens": "0",
"lr_scheduler_num_cycles": "",
"lr_scheduler_power": ""
}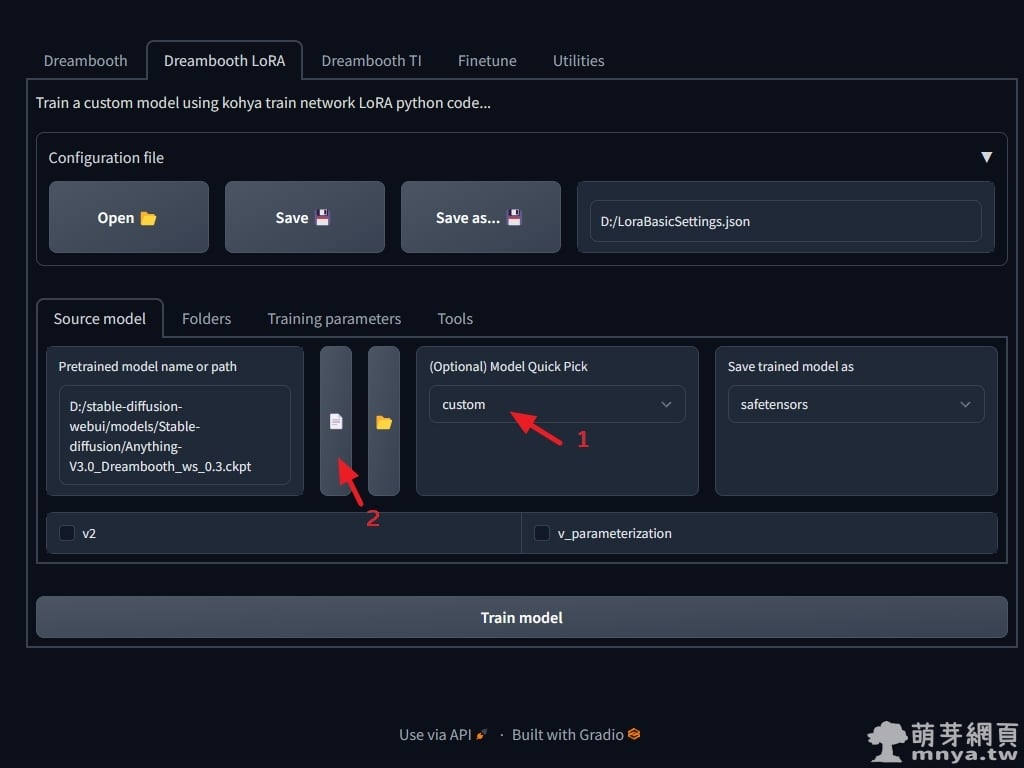
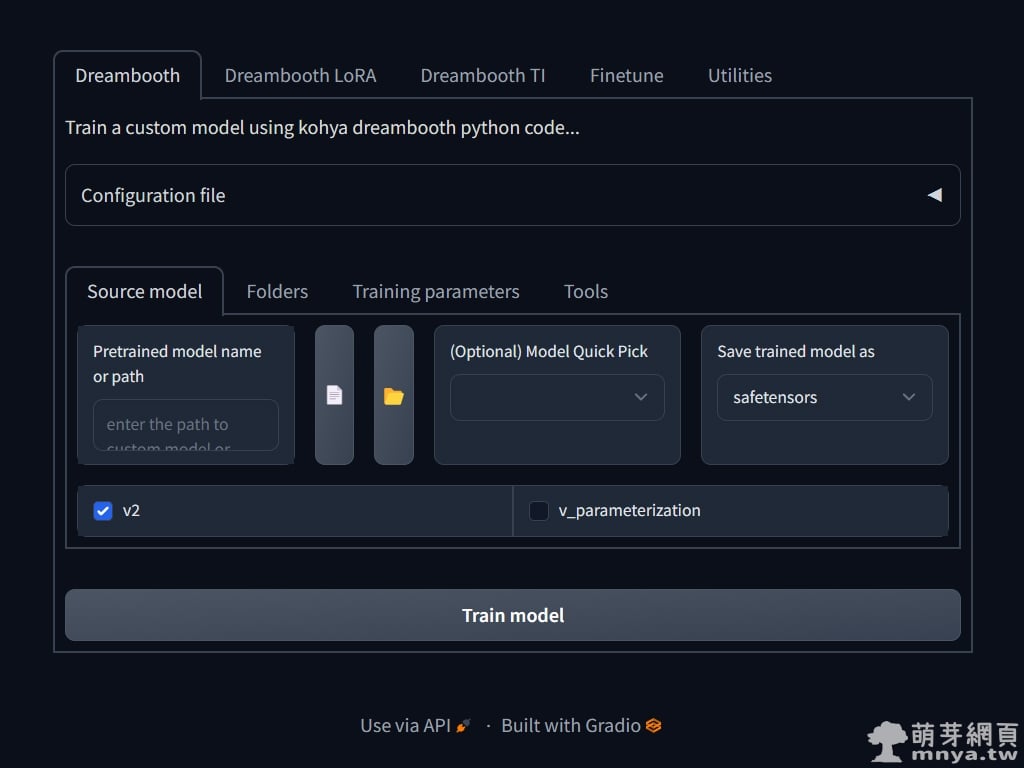
▲ 接著「(Optional) Model Quick Pick」選「custom」客製化訓練基礎模型,左邊「Pretrained model name or path」在選定大模型,由於我們是要訓練二次元動漫人物的模型,因此要選用來繪製這類物件的大型模型作為基礎模型喔!底下兩個選擇方塊是用到以 Stable Diffusion 2.0 架構產生的大模型才需要勾選,不過目前網上多數大模型都還是以 Stable Diffusion 1.0 架構去產生大模型的,因此這邊都不勾。
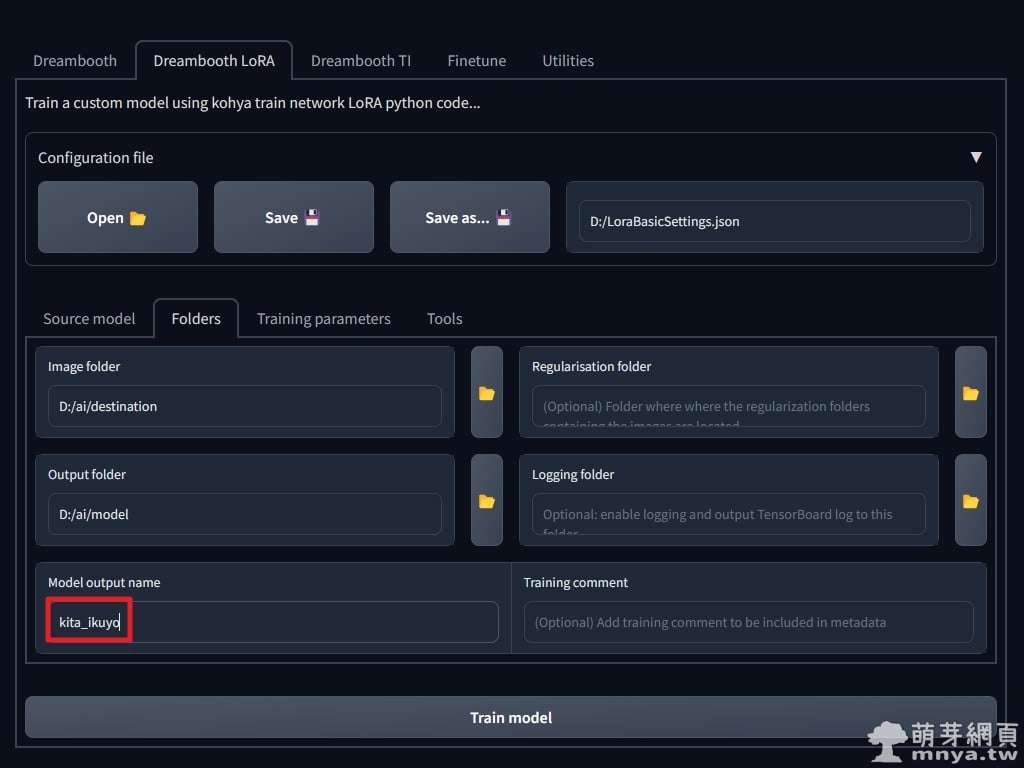
▲「Folders」這邊的路徑我都幫大家設定了,可以改成您喜歡的路徑喔!「Model output name」可以設定模型輸出名稱。
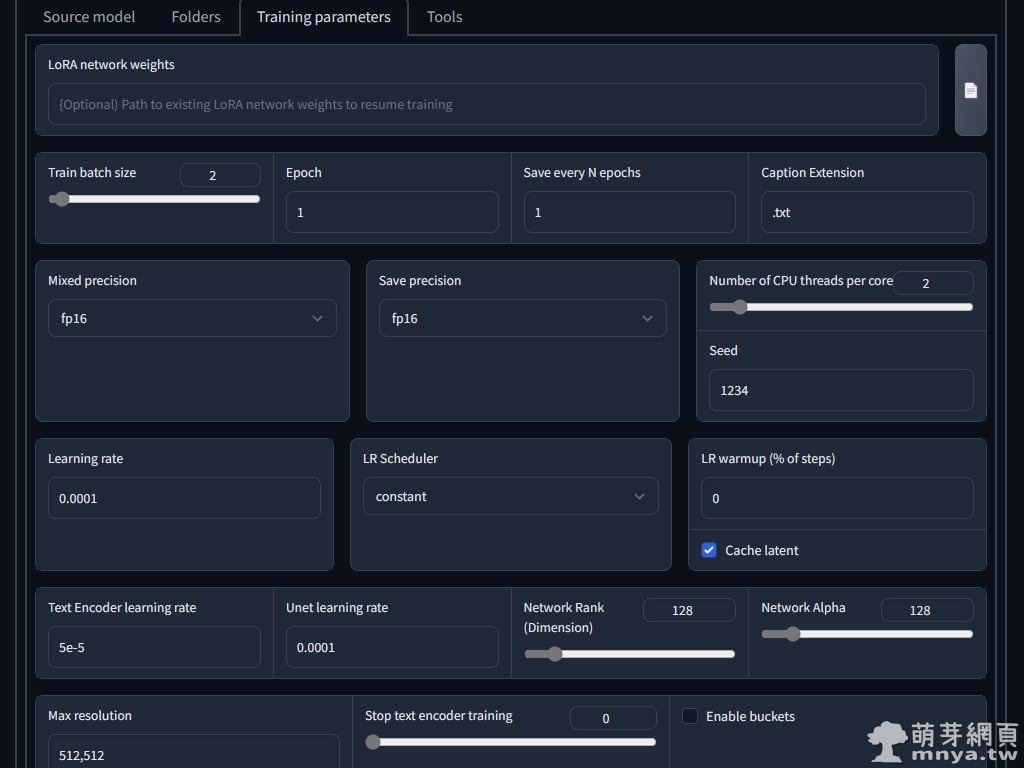
▲「Training parameters」這邊基本上都已經在快速設定檔載入時設定好了!基礎設定的「Train batch size」設定為 2,意思是訓練批次為 2,因此原本 1700 步的訓練只要 850 步就能完成,不過相對會犧牲比較多 VRAM,這邊就是看 GPU 夠不夠力。「Max resolution」是訓練圖片的寬高,這邊一般為 512 x 512 px,除非您 GPU 很強,不然不用動。其他設定有想研究的人可以再近一步去理解設定!
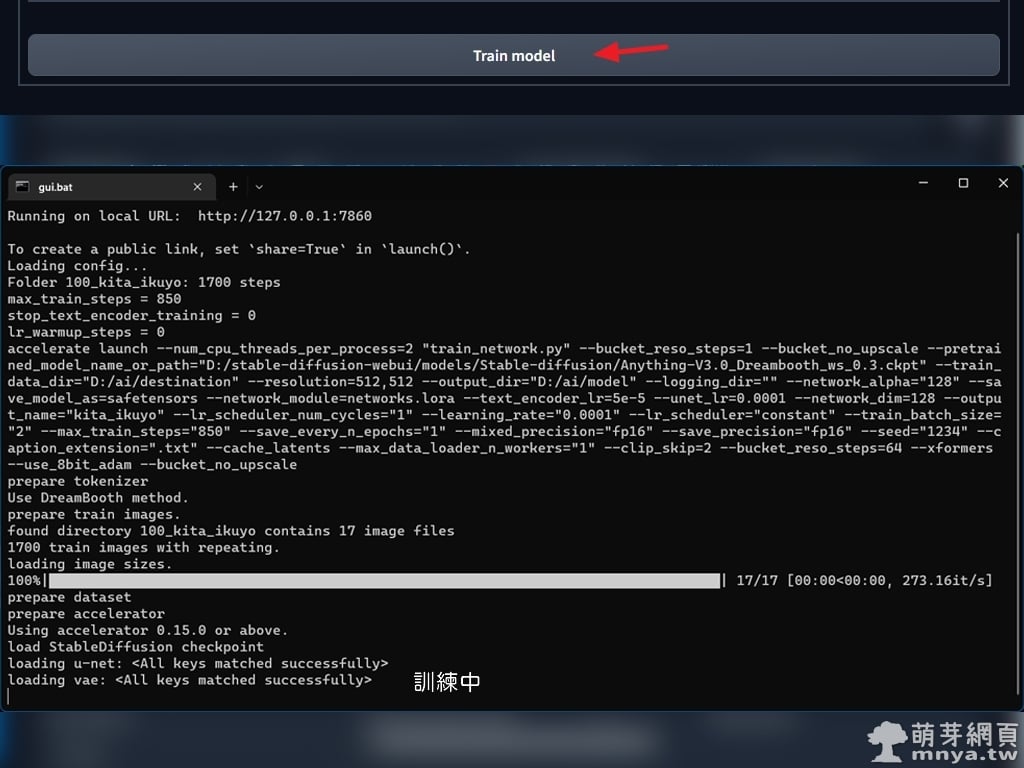
▲ 往下點「Train model」開始訓練 LoRA 小模型,終端機輸出端也可以看到運作中的畫面。
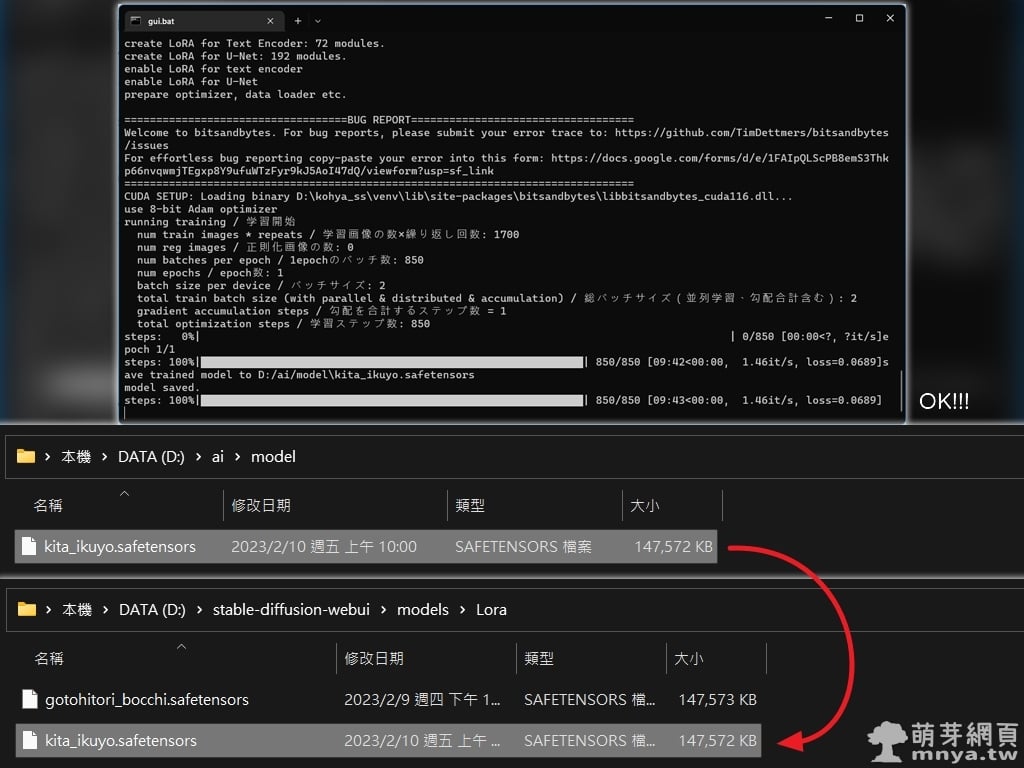
▲ 訓練完成!可以到輸出目錄找到單個小模型檔案,直接複製到 stable-diffusion-webui\models\Lora 之下,這樣就能用它來 AI 繪圖囉!您看是不是很快,十分鐘不到就產生一個小模型了!
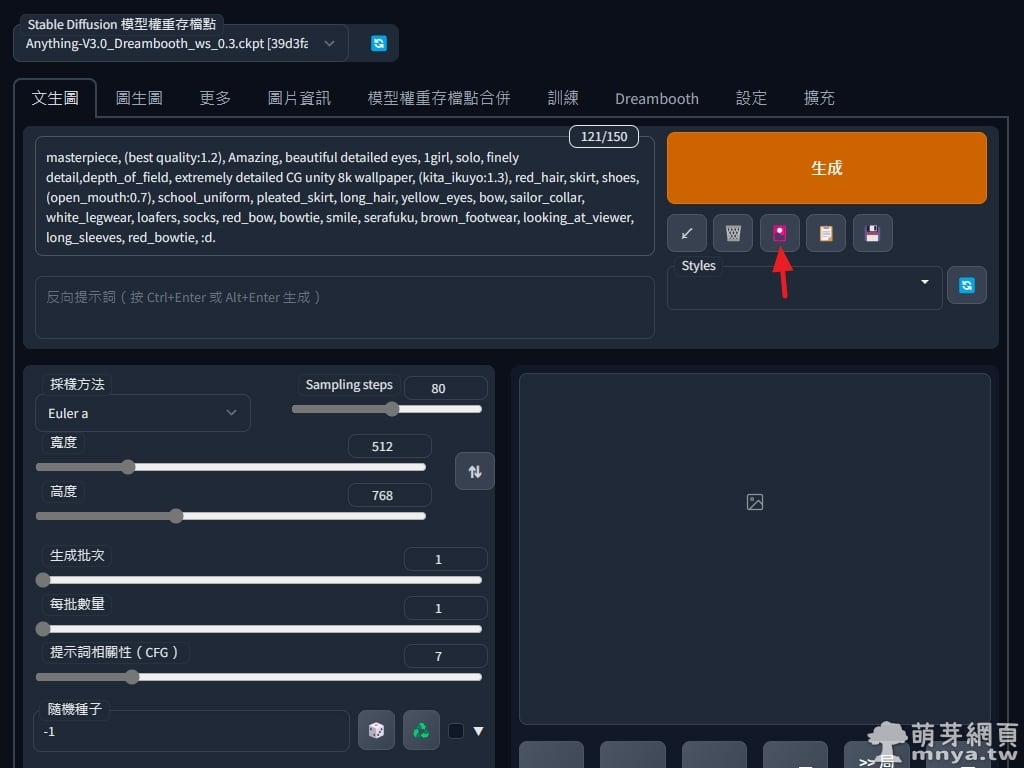
▲ 大模型選一樣的,提詞、參數設定好點紅色箭頭處的圖示。(這邊提詞用站長以前用來繪製喜多郁代的提詞)
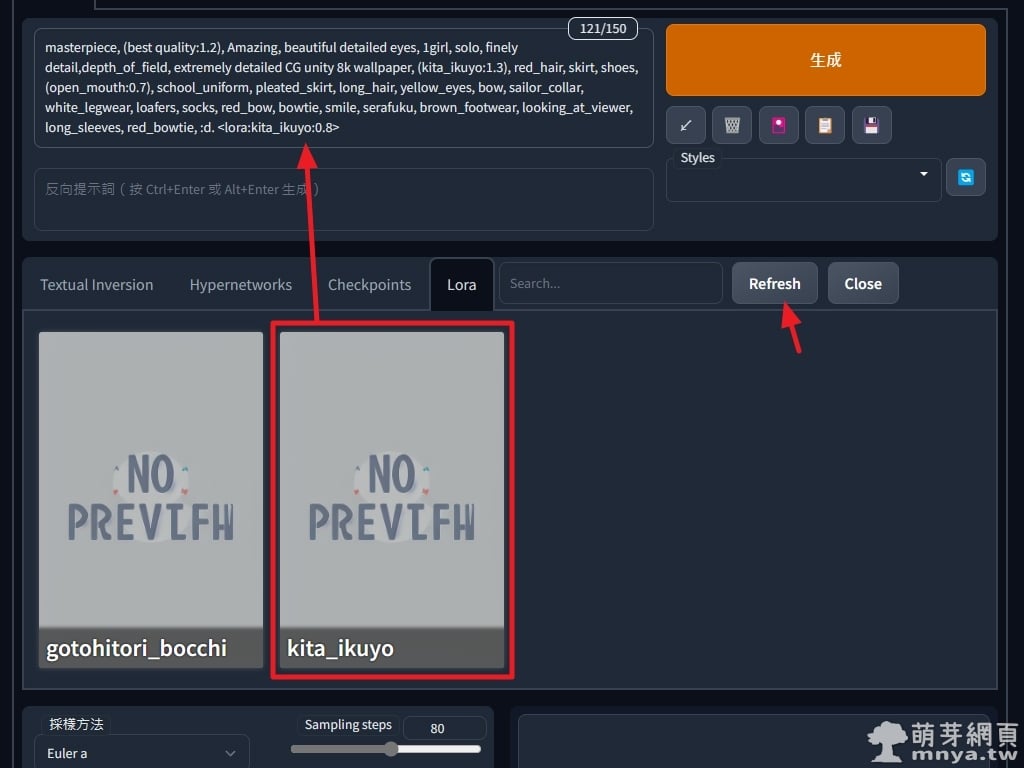
▲ 選「Lora」標籤,點剛剛訓練好的小模型就會自動在提詞處末端加入 <lora:name:1>,1 代表強度為 100%,我常常設定 0.8,即強度為 80%。如果沒看到剛剛訓練好的小模型,可以點「Refresh」重新載入喔!都確認無誤就能點「生成」開始 AI 繪圖了!

▲ AI 繪圖生成結果,有無 LoRA 模型就是差這麼多!這兩張種子碼一樣,一次輸出就有如此高的成功率,非常強大。
希望這次的教學能幫助您突飛猛進,AI 繪圖短短幾個月發展成這樣,非常驚人。當然目前要操作到訓練等還是需要不少技術能力,門檻不算低,不過隨著軟體進步,未來入手門檻將會大大降低。當然要能好好運用 AI 繪圖,還是要從基礎下手啦!歡迎分享教學連結給需要的人,歡迎瀏覽萌芽二次元欣賞本站更多 AI 繪圖作品。
錯誤排除
2023/02/20 更新
如果更新 Kohya's GUI 後進行訓練時遇到以下這個錯誤訊息:
Traceback (most recent call last):
File "D:\kohya_ss\train_network.py", line 573, in <module>
train(args)
File "D:\kohya_ss\train_network.py", line 356, in train
"ss_noise_offset": args.noise_offset,
AttributeError: 'Namespace' object has no attribute 'noise_offset'
[...]
別擔心,先到 https://github.com/kohya-ss/sd-scripts 下載 ZIP 檔案,將 sd-scripts-main\library 中的 train_util.py 複製到 kohya_ss\library 下取代原檔,重新跑一次訓練就能正常運作了!目前發現新版軟體訓練時吃比較多 GPU VRAM。

 《上一篇》Kohya's GUI:Stable Diffusion 訓練 AI 繪圖模型專用 Gradio GUI 完整安裝教學
《上一篇》Kohya's GUI:Stable Diffusion 訓練 AI 繪圖模型專用 Gradio GUI 完整安裝教學  《下一篇》Stable Diffusion web UI x Latent Couple extension:進階 AI 繪圖!同時分割繪製多個主題或人物
《下一篇》Stable Diffusion web UI x Latent Couple extension:進階 AI 繪圖!同時分割繪製多個主題或人物 








留言區 / Comments
萌芽論壇