隨著 2026 年生成式 AI 技術的演進,高品質的音樂創作已不再是雲端訂閱服務的專利。最近開源界迎來了劃時代的進展 —— ACE-Step 1.5 正式發布,這是一款由 ACE Studio 與 StepFun 共同打造的頂尖開源音樂基礎模型。ACE-Step 1.5 採用了創新的「混合語言模型 (LM) + 擴散變換器 (DiT)」架構,將語言模型作為智慧規劃器,能將簡單的文字指令轉化為精密的音樂藍圖,實現了從短循環到長達 10 分鐘的連貫創作。這不僅達到了商業級的輸出音質,更讓生成速度達到了驚人的境界:在 RTX 3090 等級的顯示卡上,僅需不到 10 秒即可生成完整曲目。我的 RTX 5070 Ti 16 GB VRAM + 64 GB RAM 實際生成兩分鐘的音樂首次花費約三分鐘的時間,也是蠻快速的了!

對於 ComfyUI 的使用者來說,現在可以直接透過官方提供的範例工作流,在本地端流暢地運行這款模型。ACE-Step 1.5 的強大之處在於其極低的硬體門檻,僅需不到 4GB 的顯示記憶體即可運作,且支援超過 50 種語言的歌詞精準對齊。這意味著創作者可以完全掌控生成過程,無需擔心隱私洩漏或昂貴的訂閱費用。本文將帶領大家透過 ComfyUI 整合 ACE-Step 1.5,從工作流載入到模型自動下載,體驗 2026 年當前最具效率的本地開源音樂生成方案。
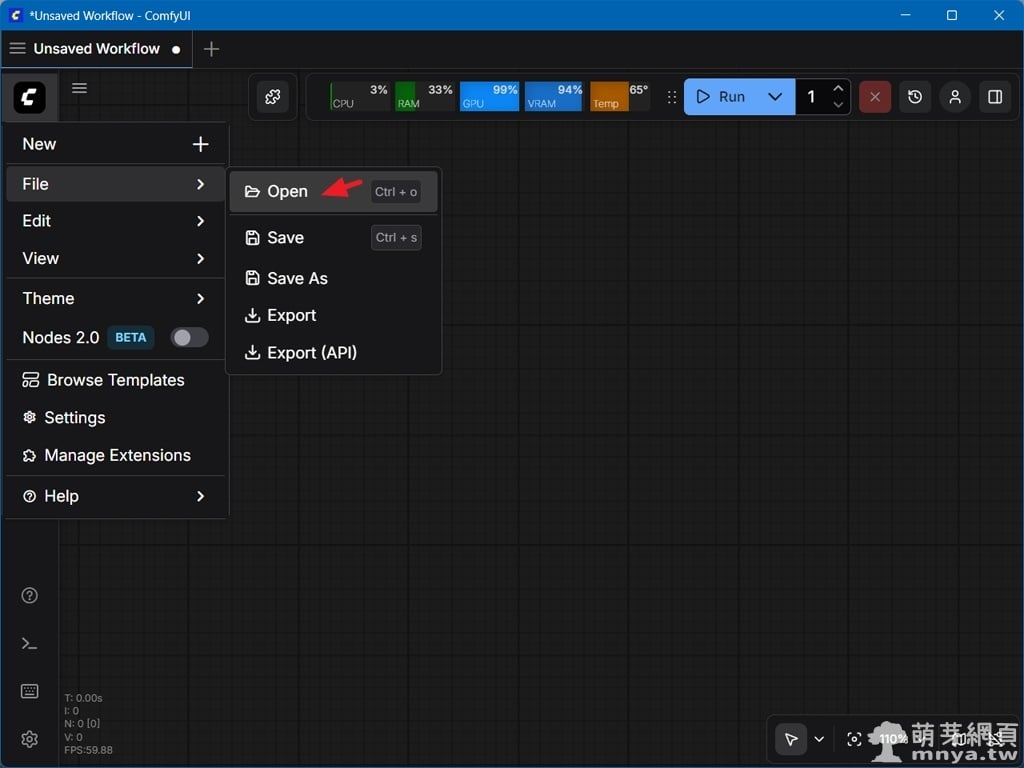
▲ 啟動 ComfyUI 後,首先點擊 LOGO 選單的「File」,選擇「Open」來載入 ACE-Step 1.5 的範例工作流檔案。這次我們直接使用官方提供的標準範例工作流,它已經預先配置好所有必要的節點與路徑邏輯,能大幅簡化初次設定的複雜度。
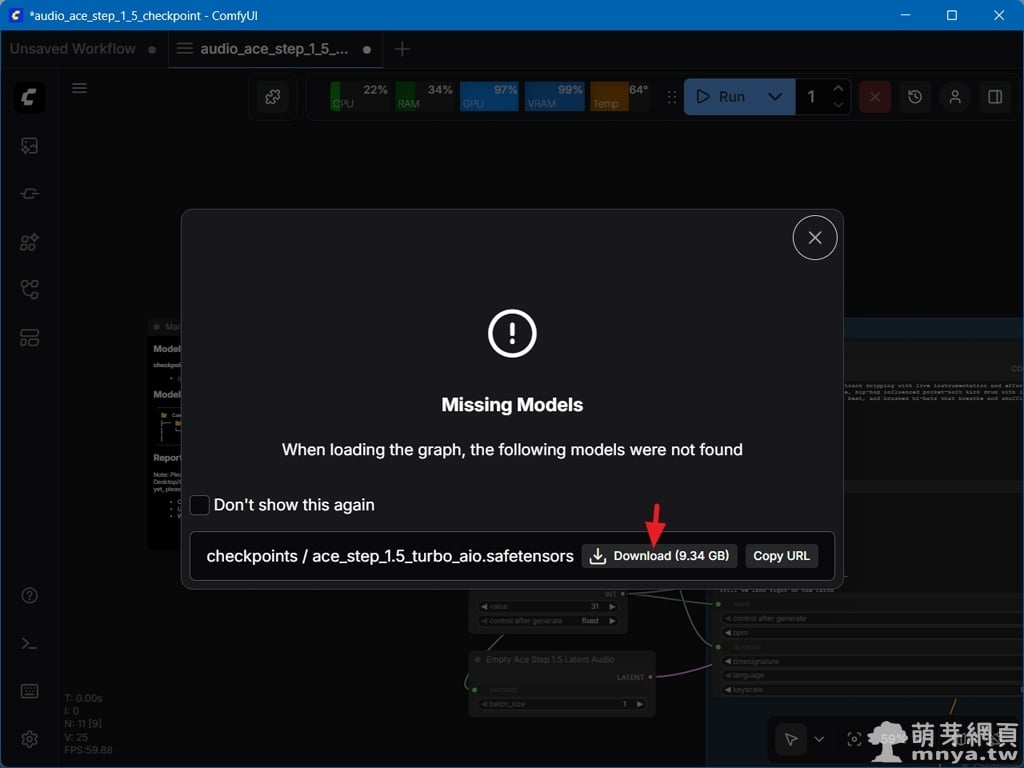
▲ 載入工作流後,ComfyUI 若偵測到本地目錄缺少模型權重,會自動彈出「Missing Models」提示視窗。在此可以直接看到所需的 ace_step_1.5_turbo_aio.safetensors 模型檔(約 9.34 GB),點擊後方的「Download」按鈕,系統將自動從遠端倉庫抓取並存放到正確路徑。
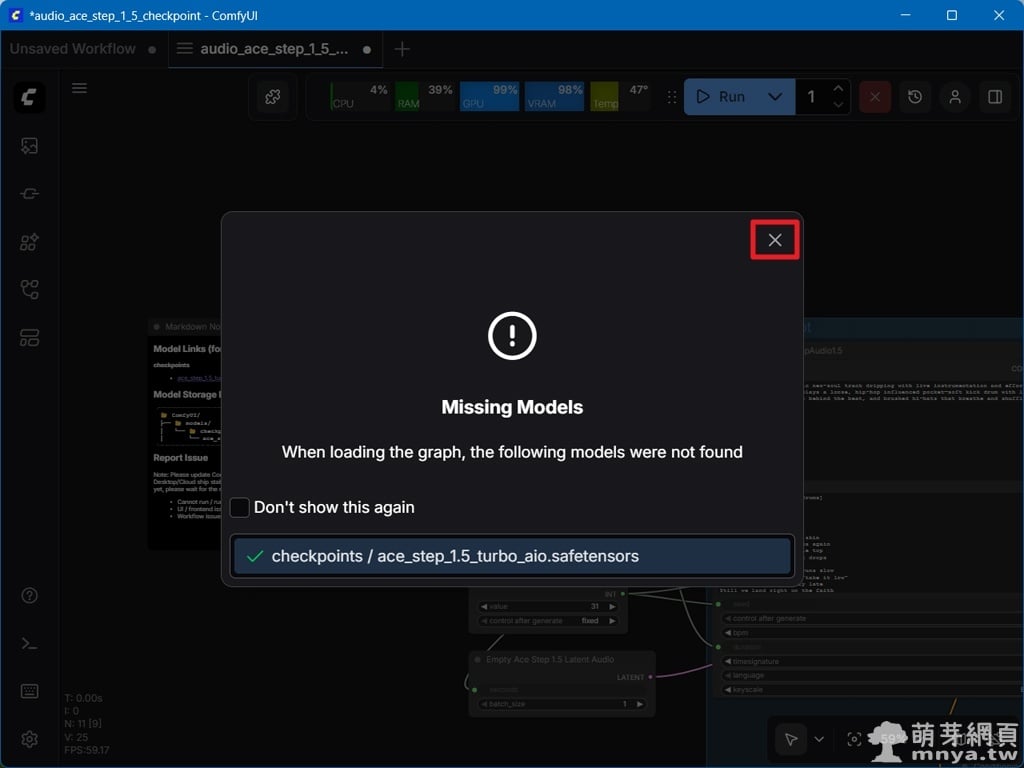
▲ 模型下載過程中會顯示即時進度,完成後該項目前方會出現綠色的勾選符號,代表權重已正確部署。此時只需點擊視窗右上角的「X」關閉對話框,ComfyUI 就會自動識別並加載下載好的模型,準備進入後續的 AI 音訊推理階段。
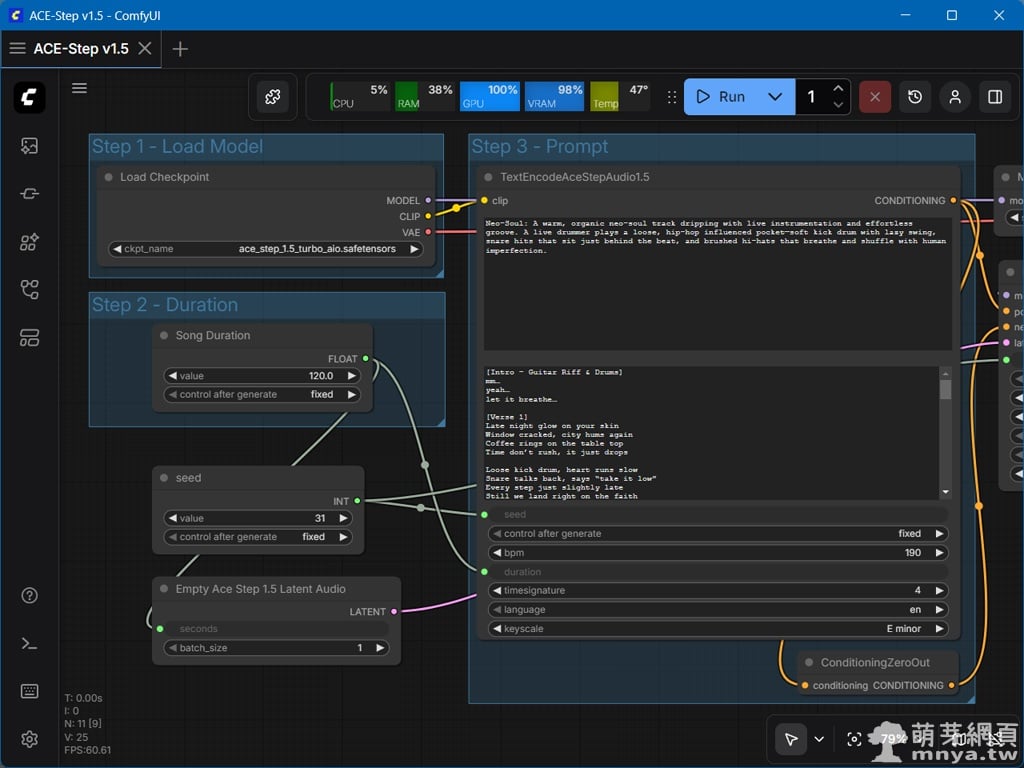
▲ 工作流主介面清晰地劃分為三個核心步驟。Step 1 負責加載剛下載的 Checkpoint 模型;Step 2 可設定音樂總長度(例如 120 秒)與隨機種子模式;Step 3 則是提示詞區塊,可在此輸入風格標籤(Tags)與歌詞(Lyrics),細膩定義音樂的風格與結構。
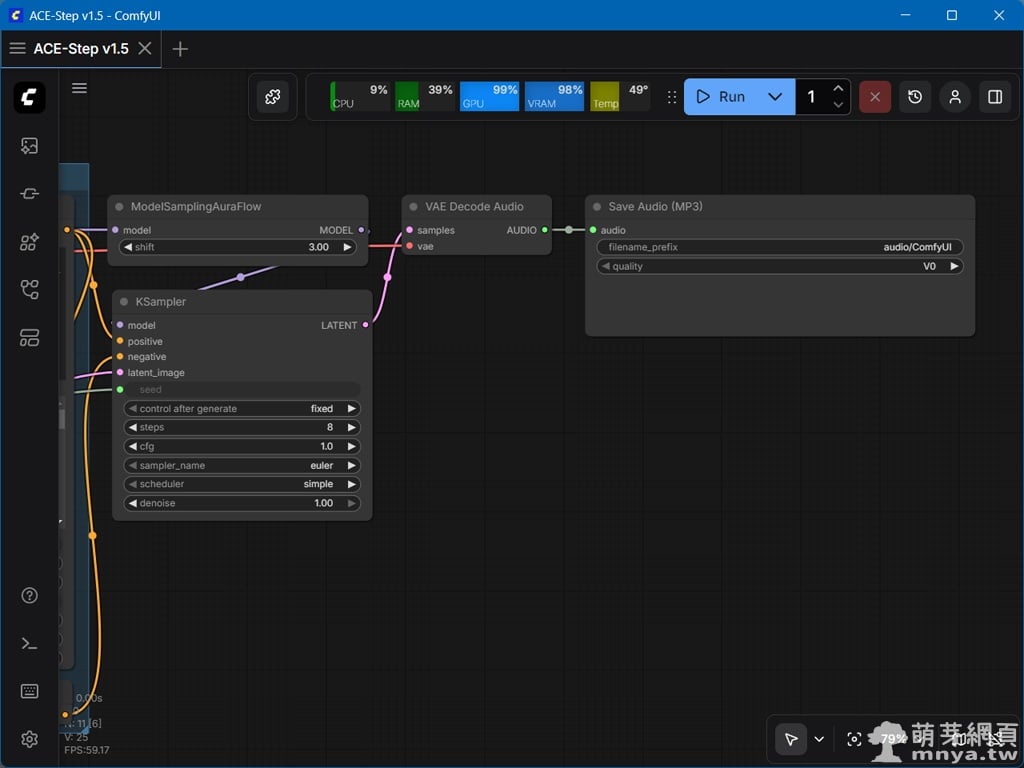
▲ 接著是負責音訊合成的運算區塊,包含處理潛在空間數據的 KSampler 以及負責最終輸出的音訊解碼節點。最後連接至「Save Audio (MP3)」儲存節點,我們在此將品質設定為 V0,確保產出的 MP3 檔案具備極高保真度。
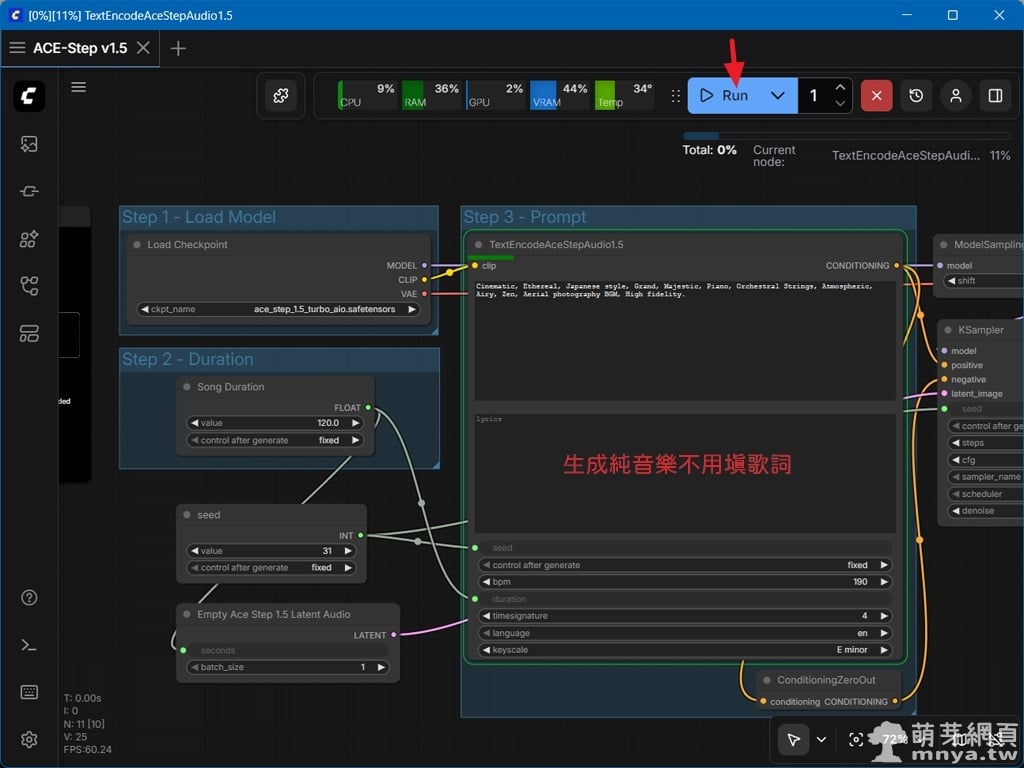
▲ 確認所有參數設定無誤後,點擊上方工具列的「Run」按鈕即可開始生成。本次示範的是「純音樂(Instrumental)」生成,因此歌詞欄位(下)保持空白即可,風格標籤(上)我填入 Cinematic, Ethereal, Japanese style, Grand, Majestic, Piano, Orchestral Strings, Atmospheric, Airy, Zen, Aerial photography BGM, High fidelity.。生成時可以看到節點周圍出現綠色邊框,並在上方顯示原生進度條,表示系統正全力進行旋律合成。
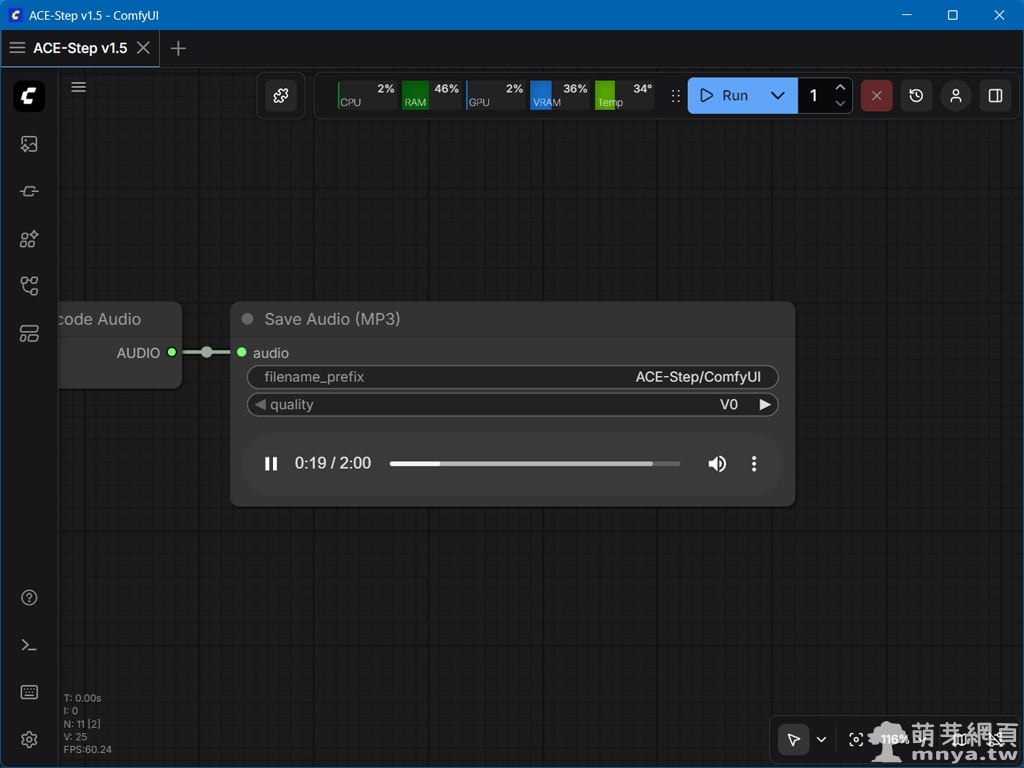
▲ 生成完成後,Save Audio 節點會直接出現內建播放器供即時預覽,下方顯示已成功產出 2 分鐘的完整音軌。以我修改的設定來說,所有作品都將自動儲存於 ComfyUI\output\ACE-Step 路徑中。

 《上一篇》Z-Image Turbo:讓角色更生動!30 款二次元動漫手部動作提示詞大公開
《上一篇》Z-Image Turbo:讓角色更生動!30 款二次元動漫手部動作提示詞大公開  《下一篇》PDNob:最佳的 NotebookLM 簡報編輯器、將 PDF 轉換為可編輯的 PPT!
《下一篇》PDNob:最佳的 NotebookLM 簡報編輯器、將 PDF 轉換為可編輯的 PPT! 







留言區 / Comments
萌芽論壇