йҡЁи‘—дәәе·Ҙжҷәж…§жҠҖиЎ“зҡ„йЈӣйҖҹзҷјеұ•пјҢGoogle Gemini зҡ„иғҪеҠӣе·ІдёҚеҶҚдҫ·йҷҗж–јж–Үеӯ—е°Қи©ұиҲҮең–еғҸз”ҹжҲҗгҖӮиҝ‘жңҹпјҢGoogle DeepMind жӯЈејҸе°Үе…¶жңҖе…ҲйҖІзҡ„йҹіжЁӮз”ҹжҲҗжЁЎеһӢ Lyria 3 е°Һе…Ҙ Gemini жҮүз”ЁзЁӢејҸдёӯпјҢй–Ӣе•ҹдәҶгҖҢж–Үеӯ—иҪүйҹіжЁӮгҖҚзҡ„е…Ёж–°еҸҜиғҪгҖӮйҖҷж¬ҫжЁЎеһӢзӣ®еүҚжӯЈиҷ•ж–ј Beta жё¬и©ҰйҡҺж®өпјҢж—ЁеңЁи®“дҪҝз”ЁиҖ…йҖҸйҒҺз°Ўе–®зҡ„жҢҮд»ӨжҲ–дёҠеӮіең–зүҮпјҢе°ұиғҪеңЁзҹӯзҹӯе№ҫз§’йҗҳе…§еүөдҪңеҮәй•·йҒ” 30 з§’гҖҒе…·еӮҷе°ҲжҘӯиіӘж„ҹзҡ„йҹіжЁӮзүҮж®өгҖӮз„Ўи«–жҳҜжғіиҰҒдёҖж®өе……ж»ҝжҮ·иҲҠж„ҹзҡ„йқһжҙІзҜҖеҘҸпјҲAfrobeatпјүпјҢйӮ„жҳҜзӮәеҜөзү©еҪұзүҮй…ҚдёҠ詼諧зҡ„ R&B ж—ӢеҫӢпјҢLyria 3 йғҪиғҪзІҫжә–жҚ•жҚүдҪҝз”ЁиҖ…зҡ„ж„Ҹең–пјҢе°ҮжҠҪиұЎзҡ„жғ…ж„ҹиҪүеҢ–зӮәеӢ•иҒҪзҡ„йҹіз¬ҰгҖӮ
Lyria 3 зҡ„ж ёеҝғе„ӘеӢўеңЁж–је…¶е°ҚйҹіжЁӮзөҗж§Ӣзҡ„ж·ұеҲ»зҗҶи§ЈиҲҮй«ҳеәҰзҡ„еҸҜжҺ§жҖ§гҖӮзӣёијғж–јд»ҘеҫҖзҡ„жҠҖиЎ“пјҢе®ғдёҚеғ…иғҪиҮӘеӢ•ж №ж“ҡжҸҗзӨәи©һз·ЁеҜ«жӯҢи©һпјҢйӮ„е®№иЁұдҪҝз”ЁиҖ…йҮқе°ҚжӣІйўЁгҖҒдәәиҒІзү№иіӘеҸҠзҜҖеҘҸеҝ«ж…ўйҖІиЎҢзҙ°еҫ®иӘҝж•ҙгҖӮжӯӨеӨ–пјҢзӮәдәҶзўәдҝқз”ҹжҲҗе…§е®№зҡ„иІ иІ¬д»»иҲҮеҸҜиҝҪжәҜжҖ§пјҢжүҖжңүйҖҸйҒҺ Gemini з”ўеҮәзҡ„йҹіи»ҢйғҪжңғеөҢе…Ҙ SynthID йҡұеҪўжө®ж°ҙеҚ°пјҢйҖҷжҳҜдёҖзЁ®иӮүзңјиҲҮиӮүиҖіз„Ўжі•еҜҹиҰәзҡ„жҠҖиЎ“пјҢиғҪжңүж•ҲиӯҳеҲҘ AI з”ҹжҲҗе…§е®№гҖӮйҖҷй …е·Ҙе…·зҡ„жҺЁеҮәпјҢдёҰйқһзӮәдәҶеҸ–д»ЈдәәйЎһеүөдҪңиҖ…пјҢиҖҢжҳҜдҪңзӮәйқҲж„ҹзҡ„и§ёеӘ’пјҢи®“жҜҸеҖӢдәәйғҪиғҪиј•й¬Ҷең°зӮәж—Ҙеёёз”ҹжҙ»й…ҚдёҠе°Ҳеұ¬зҡ„иғҢжҷҜйҹіжЁӮпјҢдә«еҸ—科жҠҖиҲҮи—қиЎ“дәӨз№”зҡ„жЁӮи¶ЈгҖӮ
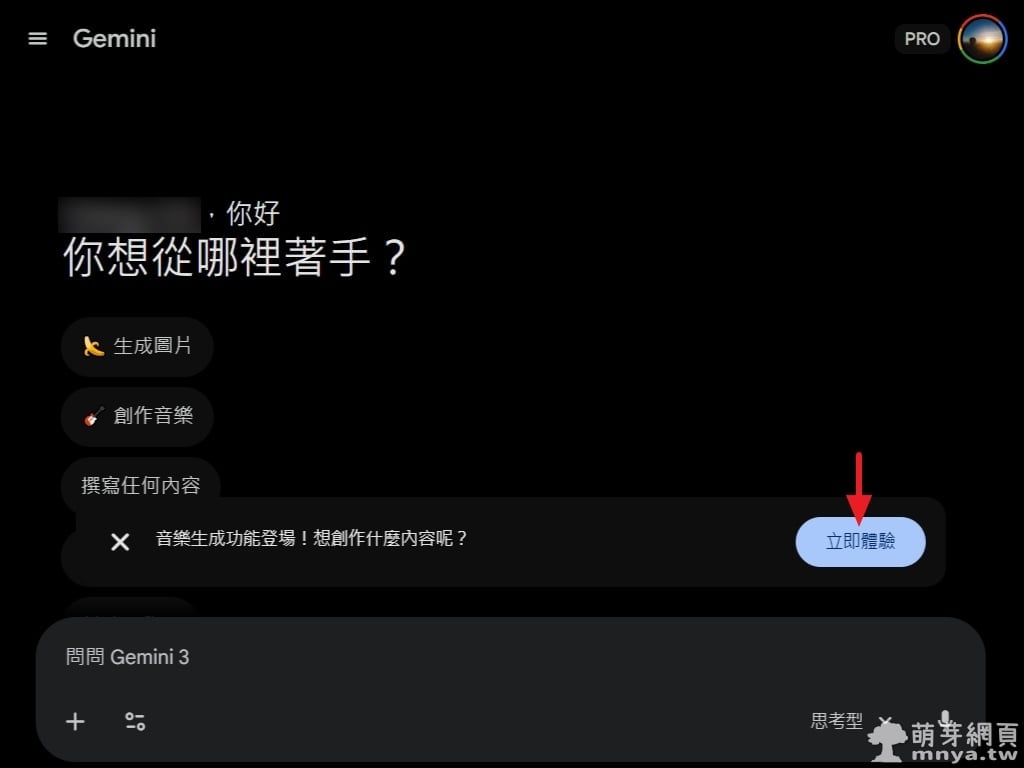
в–І йҖІе…Ҙ Gemini д»ӢйқўеҫҢпјҢзі»зөұжңғдё»еӢ•и·іеҮәгҖҢйҹіжЁӮз”ҹжҲҗеҠҹиғҪзҷ»е ҙгҖҚзҡ„е…Ёж–°жҸҗзӨәгҖӮйҖҷжЁҷиӘҢи‘— Lyria 3 жЁЎеһӢжӯЈејҸж•ҙеҗҲйҖІе°Қи©ұжөҒзЁӢдёӯгҖӮй»һж“ҠйҶ’зӣ®зҡ„гҖҢз«ӢеҚій«”й©—гҖҚжҢүйҲ•пјҢеҚіеҸҜй–Ӣе•ҹйҹіжЁӮеүөдҪңеҠҹиғҪпјҢи®“дҪҝз”ЁиҖ…иғҪеҫһж–Үеӯ—жҲ–ең–зүҮеҮәзҷјпјҢжҺўзҙўз„Ўйҷҗзҡ„ж—ӢеҫӢеҸҜиғҪжҖ§гҖӮ
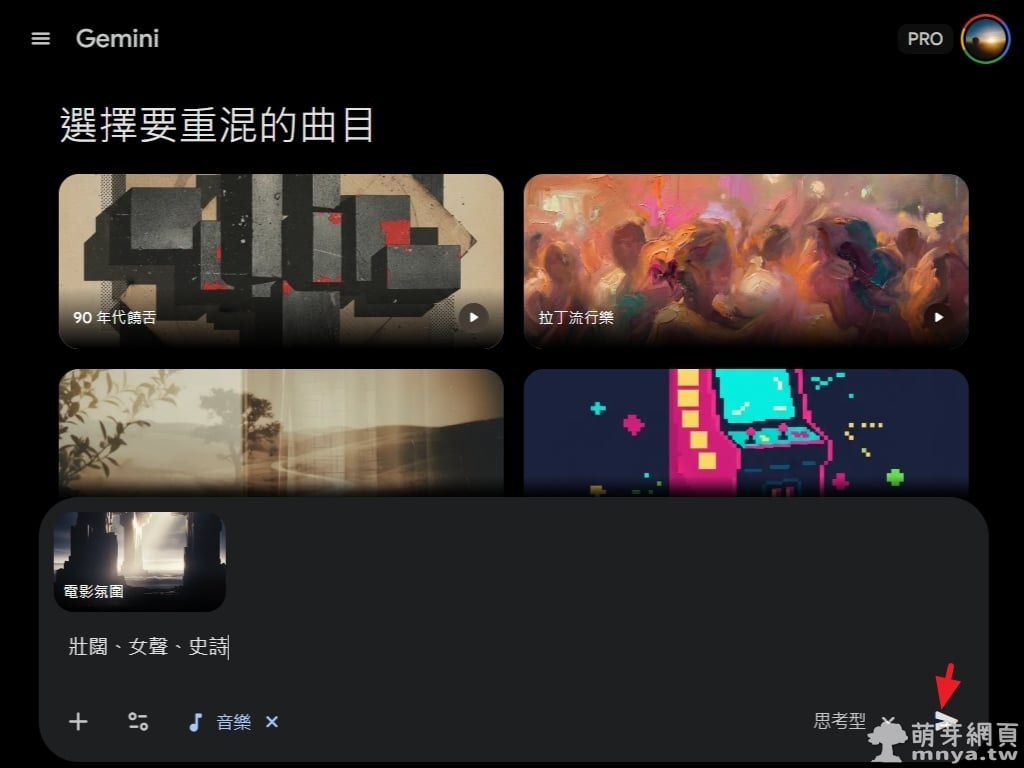
в–І еңЁз”ҹжҲҗд»ӢйқўдёӯпјҢзі»зөұжҸҗдҫӣдәҶеӨҡзЁ®жӣІйўЁжЁЎзө„дҫӣдҪҝз”ЁиҖ…еҸғиҖғгҖӮеңЁжӯӨзҜ„дҫӢдёӯпјҢжҲ‘йҒёж“ҮдәҶгҖҢйӣ»еҪұж°ӣеңҚгҖҚжЁЎжқҝпјҢдёҰиҮӘиЎҢијёе…ҘдәҶгҖҢеЈҜй—ҠгҖҒеҘіиҒІгҖҒеҸІи©©гҖҚзӯүж ёеҝғй—ңйҚөеӯ—гҖӮйҖҷзЁ®зӣҙиҰәзҡ„ж“ҚдҪңж–№ејҸпјҢи®“еҚідҫҝдёҚе…·еӮҷжЁӮзҗҶеҹәзӨҺзҡ„дҪҝз”ЁиҖ…пјҢд№ҹиғҪжё…жҷ°е®ҡзҫ©еҮәжғіиҰҒзҡ„йҹіжЁӮжғ…з·’гҖӮй»һеҸідёӢи§’зҙҷйЈӣж©ҹең–зӨәйҖҒеҮәжҢҮд»ӨгҖӮ
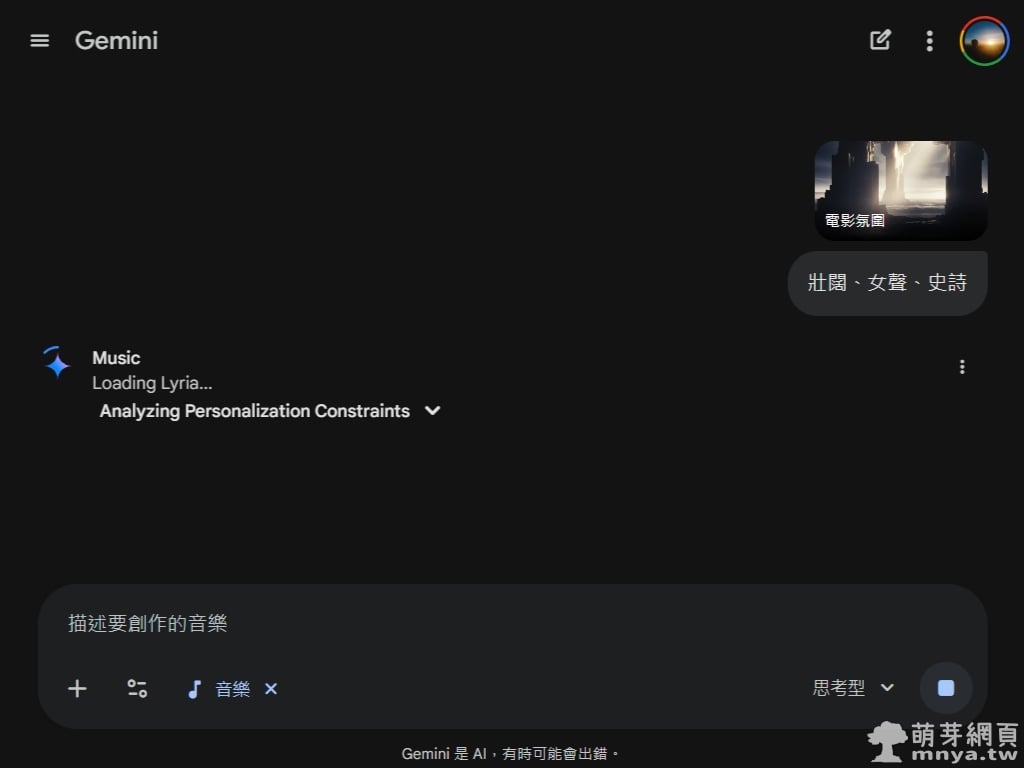
в–І йҖҒеҮәйңҖжұӮеҫҢпјҢGemini жңғйҖІе…ҘйҒӢз®—зӢҖж…ӢпјҢз•«йқўдёҠжңғйЎҜзӨәгҖҢLoading Lyria...гҖҚд»ҘеҸҠжӯЈеңЁеҲҶжһҗеҖӢдәәеҢ–зҙ„жқҹжўқ件зҡ„йҖІеәҰгҖӮйҖҷж®өйҒҺзЁӢеұ•зҸҫдәҶ AI жӯЈеңЁеҫҢз«Ҝеҝ«йҖҹеӘ’еҗҲжЁӮеҷЁз·ЁеҲ¶гҖҒиӘҝжҖ§иҲҮдҪҝз”ЁиҖ…жҸҗдҫӣзҡ„й—ңйҚөеӯ—пјҢзўәдҝқз”ҹжҲҗзҡ„жҜҸдёҖз§’йҹіи»ҢйғҪз¬ҰеҗҲгҖҢеҸІи©©ж„ҹгҖҚзҡ„иЁӯе®ҡгҖӮ
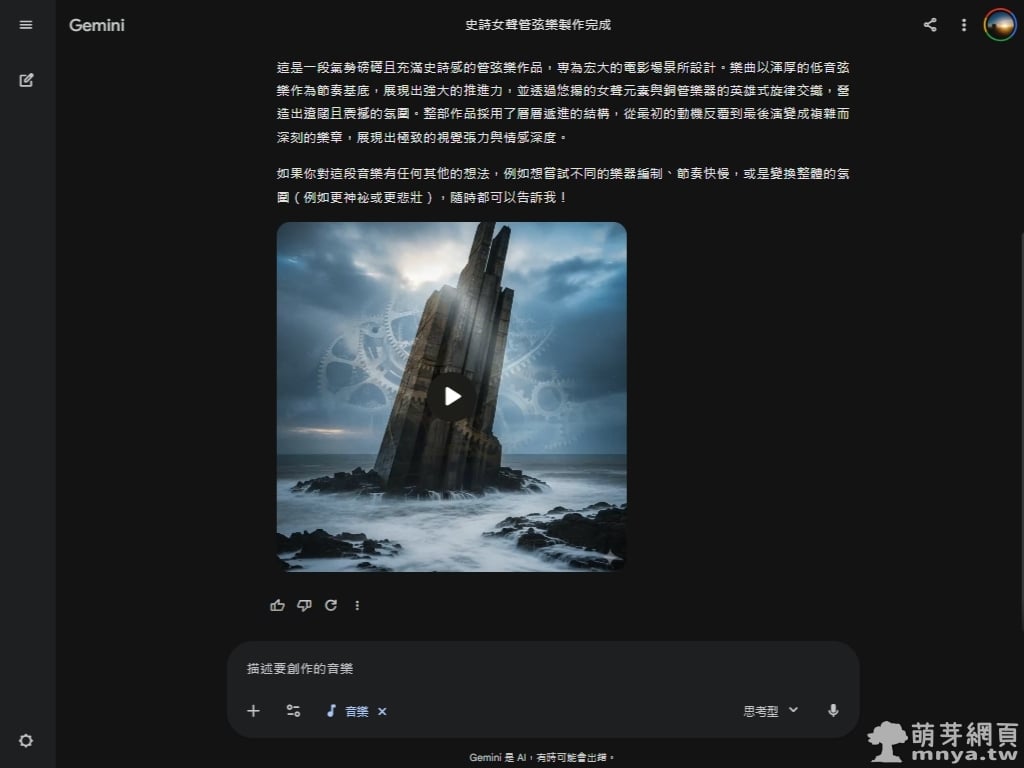
в–І еүөдҪңе®ҢжҲҗеҫҢпјҢзі»зөұжңғз”ҹжҲҗдёҖж®өзҙ„ 30 з§’зҡ„й«ҳе“ҒиіӘжЁӮжӣІпјҢдёҰйҷ„её¶и©ізҙ°зҡ„ж–Үеӯ—иіһжһҗгҖӮйҖҷж®өгҖҢеҸІи©©еҘіиҒІз®ЎејҰжЁӮгҖҚдҪңе“Ғд»ҘжёҫеҺҡзҡ„дҪҺйҹіејҰжЁӮзӮәеҹәеә•пјҢдәӨз№”и‘—иӢұеӢҮзҡ„ж—ӢеҫӢиҲҮз©әйқҲзҡ„еҘіиҒІе…ғзҙ пјҢдҪҶеҜҰйҡӣдёҠеҚ»жІ’жңүеҮәзҸҫеҘіиҒІпјҢйҖҷеҸҜиғҪе°ұжҳҜ AI дёҚе®ҢзҫҺзҡ„ең°ж–№еҗ§пјҒжҲҗжһңдёҖе®ҢжҲҗпјҒ
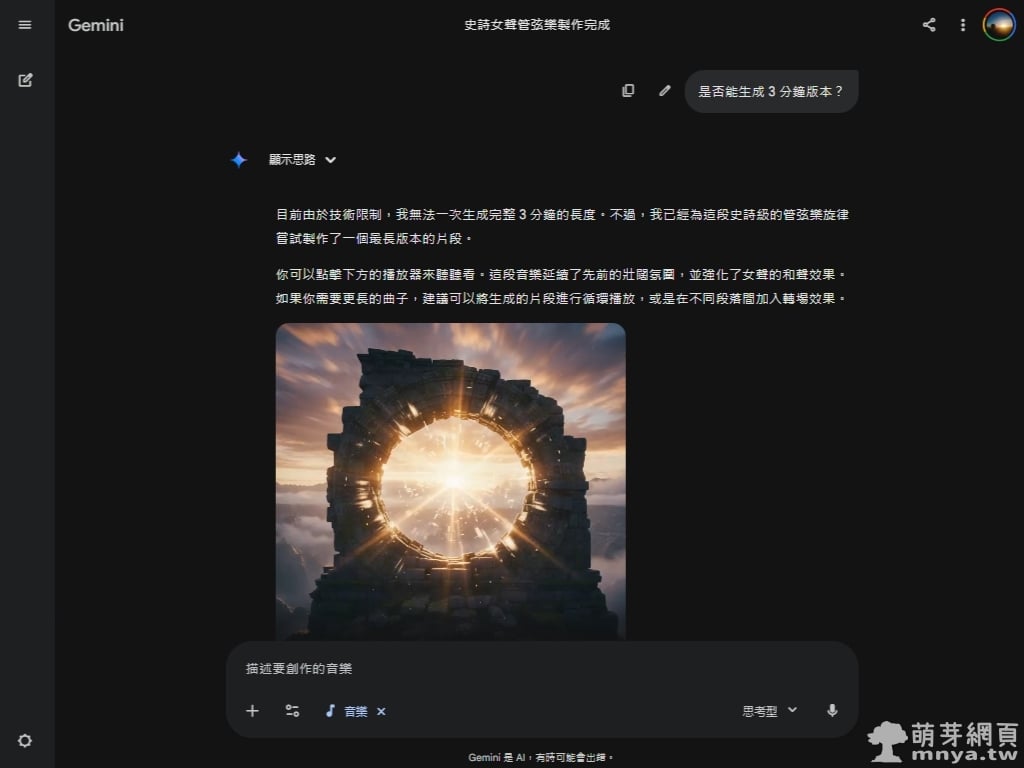
в–І жҲ‘еҫҢзәҢеҳ—и©ҰиҰҒжұӮз”ҹжҲҗжӣҙй•·зҡ„зүҲжң¬пјҲеҰӮ 3 еҲҶйҗҳпјүпјҢGemini жңғиӘ еҜҰиӘӘжҳҺзӣ®еүҚзҡ„жҠҖиЎ“йҷҗеҲ¶гҖӮйӣ–然зӣ®еүҚ Beta зүҲдёҖж¬Ўз”ҹжҲҗзҡ„й•·еәҰжңүйҷҗпјҢдҪҶ AI д»Қжңғеҳ—и©ҰиЈҪдҪңдёҖеҖӢж–°зҡ„зүҮж®өпјҢдёҰе»әиӯ°дҪҝз”ЁиҖ…еҸҜд»ҘйҖҸйҒҺеҫӘз’°ж’ӯж”ҫжҲ–еҫҢиЈҪиҪүе ҙдҫҶйҒ”жҲҗйңҖжұӮгҖӮйҖҷж¬Ўзҡ„жҲҗжһңдәҢзөӮж–јеҮәзҸҫеҘіиҒІдәҶпјҒ
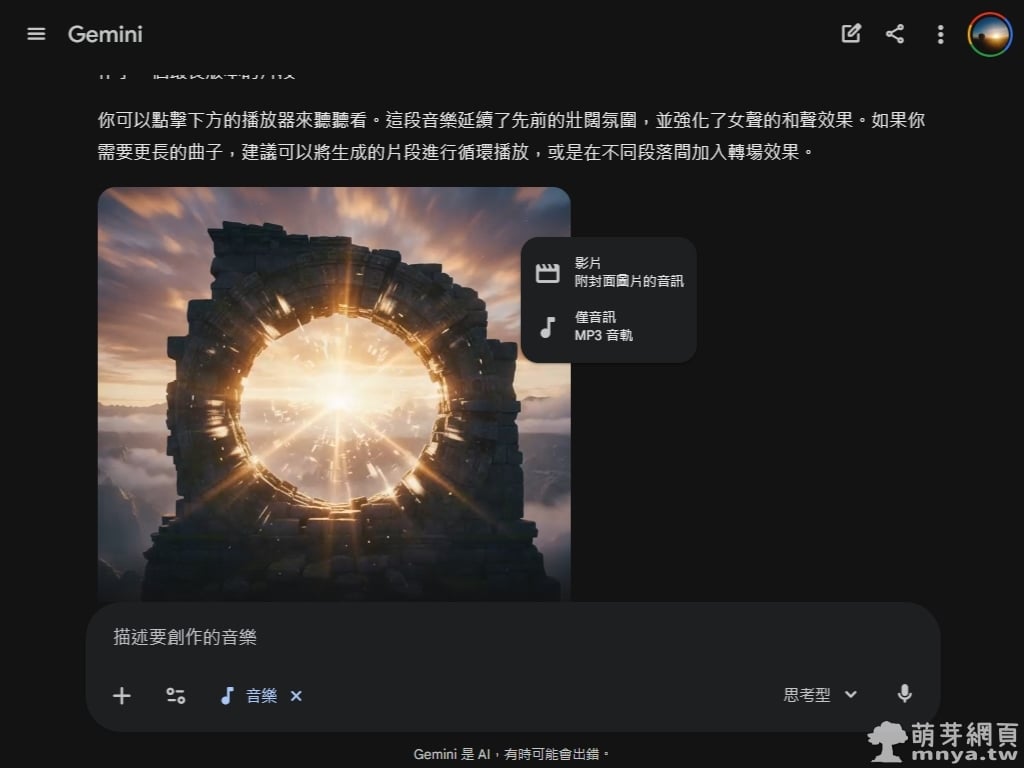
в–І з”ҹжҲҗеҫҢзҡ„дҪңе“Ғж”ҜжҸҙе…©зЁ®еҢҜеҮәж–№ејҸпјҢдҪҝз”ЁиҖ…й»һж“Ҡйҡұи—Ҹзҡ„дёӢијүжҢүйҲ•еҫҢпјҲжёёжЁҷиҰҒ移е…ҘдҪңе“ҒеҚҖеҹҹе…§пјҢжңҖеҸідёҠзҡ„жҢүйҲ•пјүпјҢеҸҜд»ҘйҒёж“ҮдёӢијүгҖҢйҷ„её¶е°Ғйқўең–зүҮзҡ„еҪұзүҮжӘ”жЎҲгҖҚд»ҘдҫҝзӣҙжҺҘеҲҶдә«иҮізӨҫзҫӨе№іеҸ°пјҢжҲ–жҳҜйҒёж“Үзҙ”зІ№зҡ„гҖҢMP3 йҹіиЁҠи»ҢгҖҚйҖІиЎҢе°ҲжҘӯеүӘијҜдҪҝз”ЁгҖӮйҖҷзЁ®йқҲжҙ»зҡ„ијёеҮәйҒёй …пјҢеӨ§еӨ§жҸҗеҚҮдәҶ AI йҹіжЁӮзҡ„еҜҰз”Ёеғ№еҖјгҖӮ


 гҖҠдёҠдёҖзҜҮгҖӢZ-Image Turboпјҡз№ӘиЈҪдәҢж¬Ўе…ғеӢ•жј«и§’иүІжӢҝз«Ӣй«”ж•ёеӯ— Q зүҲең–жҢҮеҚ—
гҖҠдёҠдёҖзҜҮгҖӢZ-Image Turboпјҡз№ӘиЈҪдәҢж¬Ўе…ғеӢ•жј«и§’иүІжӢҝз«Ӣй«”ж•ёеӯ— Q зүҲең–жҢҮеҚ—  гҖҠдёӢдёҖзҜҮгҖӢDJI Osmo Action 5 Pro жҡўжӢҚеҘ—иЈқ йҒӢеӢ•зӣёж©ҹ/иҝ·дҪ зӣёж©ҹ
гҖҠдёӢдёҖзҜҮгҖӢDJI Osmo Action 5 Pro жҡўжӢҚеҘ—иЈқ йҒӢеӢ•зӣёж©ҹ/иҝ·дҪ зӣёж©ҹ 







з•ҷиЁҖеҚҖ / Comments
иҗҢиҠҪи«–еЈҮ