近年來,隨著生成式 AI 與擴散模型的快速演進,影音內容的自動化生成已不再侷限於靜態圖片或簡單動畫,而是逐步邁向「可控、可對齊、可延展」的動態影片層級。特別是在語音驅動角色動畫(Audio-driven Avatar)領域中,如何在嘴型同步、表情情緒、角色一致性之間取得平衡,一直是技術上的核心難題。對於硬體資源有限的使用者而言,能否在消費級 GPU 上實際運行,更是影響技術普及的重要關鍵。
本文以 WanGP 整合 HunyuanVideo-Avatar 為主軸,實際示範如何透過「參考音源」製作 AI 對嘴影片。HunyuanVideo-Avatar 本質上是為真人角色設計的模型,但此處刻意以二次元角色「萌芽娘」作為展示範例,讓讀者更容易觀察不同風格下模型的嘴型同步、動作連貫與整體穩定度。整個流程僅需一張角色圖片、一段語音檔(甚至可以是歌唱片段)與極簡提示詞(例如:她正在說話),即可生成具備說話動作的短影片,展現出目前開源影音生成技術已達到的實用水準。
語音檔台詞:初次見面,我是萌芽系列網站的代表吉祥物,萌芽娘。 我的存在,是為了守護這片充滿知識與技術的網頁天地。
簡短提示詞:She is speaking.
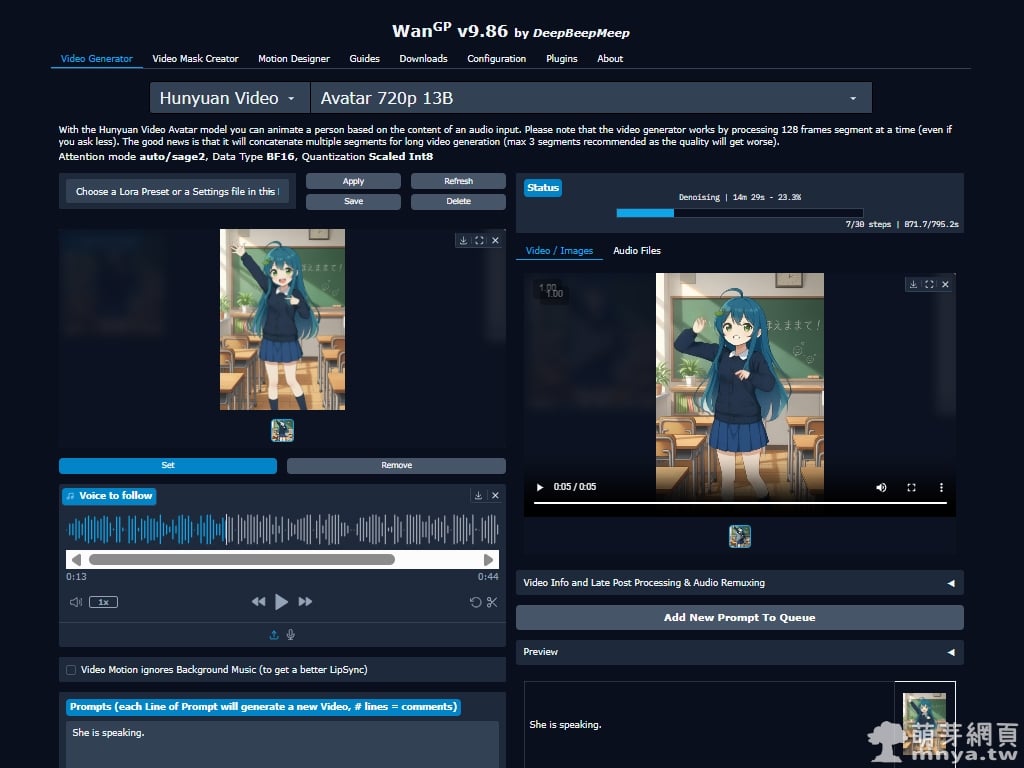
▲ 此畫面為 WanGP 的 Video Generator 主介面,已選擇 HunyuanVideo-Avatar 720p 13B 模型並載入角色圖片與參考音源。左側為輸入設定區,右側可即時預覽生成中的影片結果。
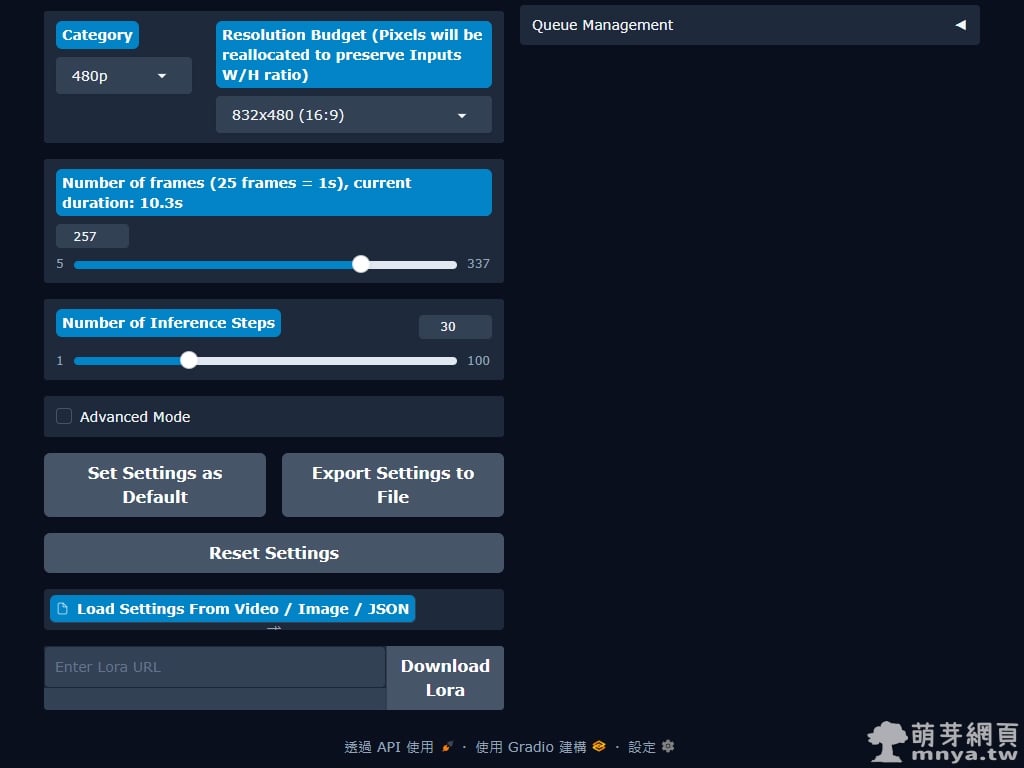
▲ 下方設定區可調整解析度、影格數與推理步數,我這樣設定所輸出的影片尺寸是 528 x 768 px(輸入圖片為 496 x 720 px)。在 RTX 5070 Ti 16GB VRAM 環境下,每 5 秒影片約需 30 分鐘生成,消耗 VRAM 約 10 GB,效能表現供大家評估參考。
▼ 範例影片(一):萌芽娘
就成品來說,二次元的圖確實如想像中容易破圖。
▼ 範例影片(二):真人
真人效果就好些了,不過可能解析度不足效果沒這麼好,建議參考圖可以取上半身就好。




 《上一篇》Pinokio x WanGP:快速建置本地 AI 影片工作室
《上一篇》Pinokio x WanGP:快速建置本地 AI 影片工作室  《下一篇》WanGP x Wan 2.2 Animate:參考動作製作指定角色 AI 跳舞影片
《下一篇》WanGP x Wan 2.2 Animate:參考動作製作指定角色 AI 跳舞影片 








留言區 / Comments
萌芽論壇