站長已經玩 AI 繪圖半年的時間,也碰了最近非常熱門的 ChatGPT,非常明白理解到 AI 的進步速度跟好用程度,現在不去學習如何去使用它,那很快地就會被取代了!AI 語音其實不是什麼很新鮮的技術,但近期終於有人讓它變得更簡單、好使用,那就是近期登場的 Retrieval-based-Voice-Conversion-WebUI(簡稱 RVC),MIT 開源授權,擁有完全基於 Web 的 GUI 介面,支援多國語系,您可以輕鬆的在上頭訓練人聲成 .pth 模型檔,即讓 AI 學會一個人的聲音,接著透過載入模型並進行推理,將輸入的音檔做轉換,讓任何人聲都可以變成原始訓練的人聲,簡單來說就是可以讓 A 的聲音變成 B 的聲音,透過音高轉換,男女性聲音轉換也變得相當容易,例如男聲轉女聲推薦可以升八度(+12key)再給 AI 推理,這些軟體也都有提供文字解說。
AI 語音技術的進步已經帶來了許多令人興奮的結果,而 RVC 則是其中的一個重要發展方向。RVC 可以讓使用者將一個人的聲音樣本複製並轉移到另一個人身上,並可實現即時語音轉換。以下是 RVC 可能帶來的一些結果:
1. 更自然的語音轉換:RVC 技術可以讓語音轉換更加自然、逼真。這種技術可以學習一個人的語音特徵,包括音調、節奏和語速等,並將這些特徵應用到其他人的語音中,使其聽起來更加自然。
2. 音頻和影片後期制作:RVC 技術還可以用於音頻和影片後期制作。例如,在電影和電視劇中,演員的聲音可能需要進行修剪或處理,RVC 技術可以幫助製作人員快速、高效地完成這些任務。
3. 音樂創作:RVC 技術可以用於音樂創作,例如合成電子音樂或增強現有音樂。使用這種技術,音樂家可以從其他藝術家的聲音中獲得靈感,並將其應用到自己的創作中。
雖然這技術對於娛樂、語音合成等方面有著極大的應用價值。然而,這種技術也引發了許多道德等問題,例如濫用、欺騙、侵犯隱私等問題,需要你我共同關注,使用該技術時也要特別注意這些問題,請小心別踩線。
CPU 與 GPU 建議都不能太差再來操作,訓練需要用 CPU 提取音高、GPU 提取特徵,推理的部分 CPU 可以跑(畢竟非即時轉換,即時轉換可能就要靠 GPU 加速不然也許會延遲,這篇文章不做這部分),本人電腦 CPU 為 i7-8700(6 核心、12 執行緒)、GPU 為 NVIDIA GeForce RTX 3060(VRAM 12G),就供大家參考了!圖文操作教學開始:
一、訓練集準備
不管是語音音檔、歌聲音檔皆可以拿來訓練,當然為求穩定建議用單純、乾淨的語音音檔來訓練。這邊推薦使用由日本SSS合同會社「東北俊子Project」提供的研究用素材庫,只要有推特帳號及同意條款就能下載到可用於 AI 訓練的素材音檔囉!
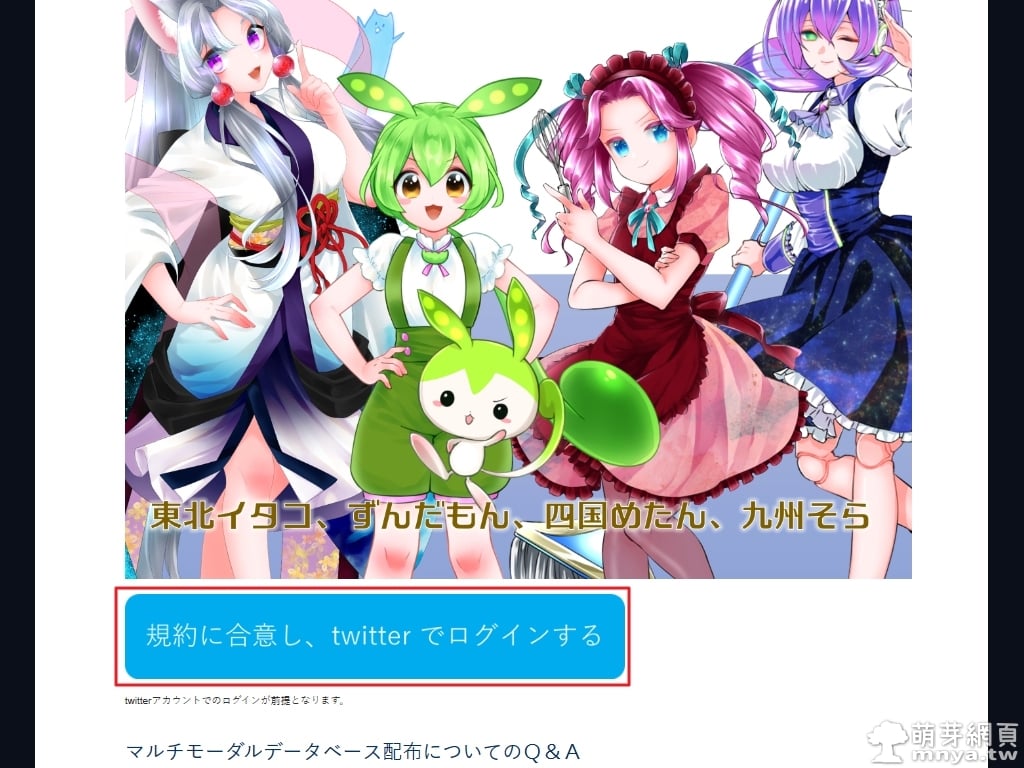
▲ 首先進入素材庫網頁,素材可供研究使用,這邊有 QA 可以看,詳讀後點擊藍色按鈕與推特(Twitter)帳號連接。
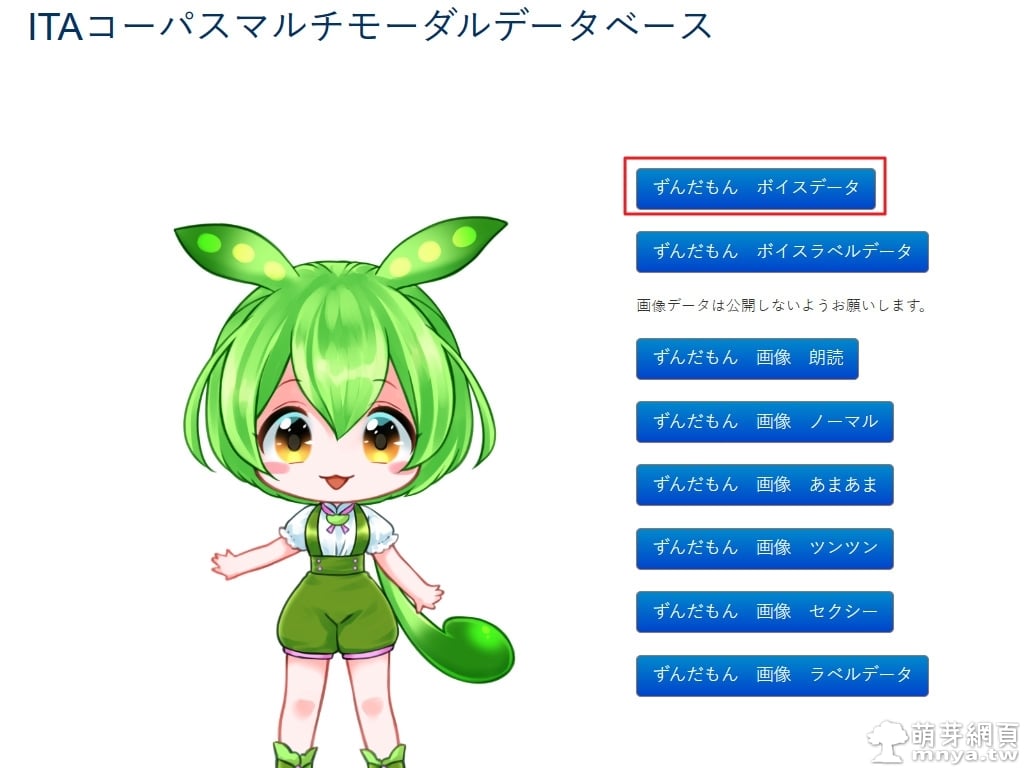
▲ 連接推特成功後,可以看到同意書,確認同意各個條款後就能下載素材了!這邊我選用「東北俊子Project」中的角色「俊達萌」(ずんだもん)的語音數據,CV 是「伊藤ゆいな」,下載後解壓縮,可以在 zundamon_voice_data\emotion\normal 路徑下找到一百個純語音音檔,這就是稍後要用到的訓練集。
二、RVC 訓練與推理
本文的重點就在這裡,如何透過基於 Web 的 GUI 完成人聲的訓練及推理呢?繼續看下去。
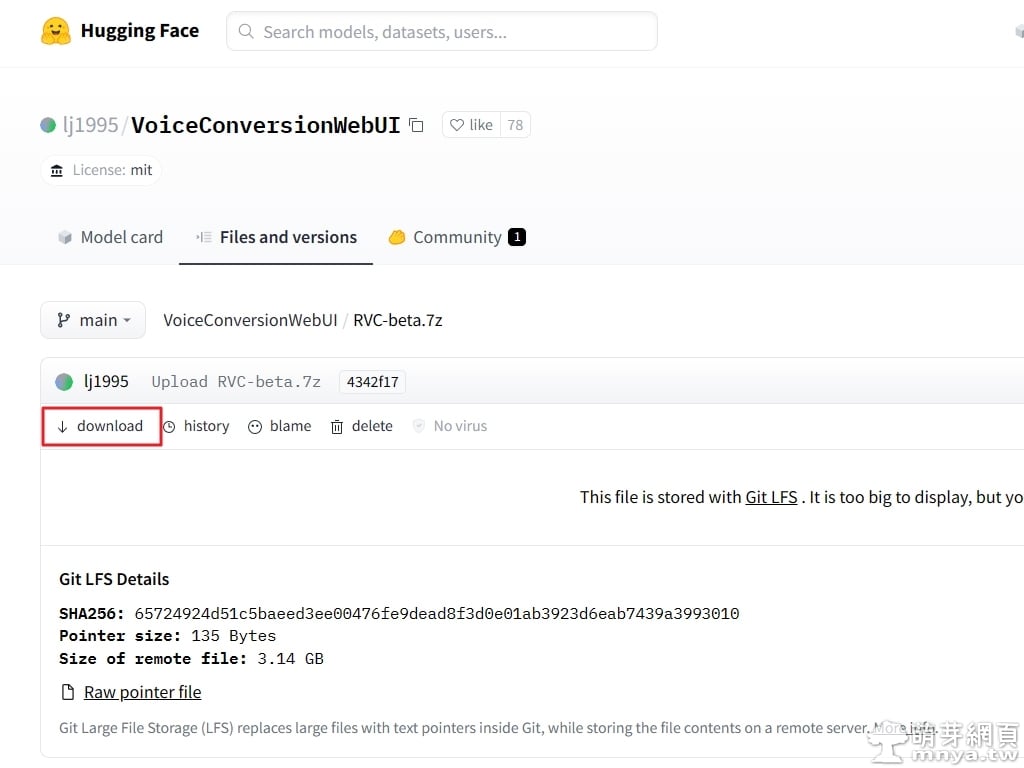
▲ RVC 開發者在 Hugging Face 放了完整的軟體包,請點擊 download 下載。
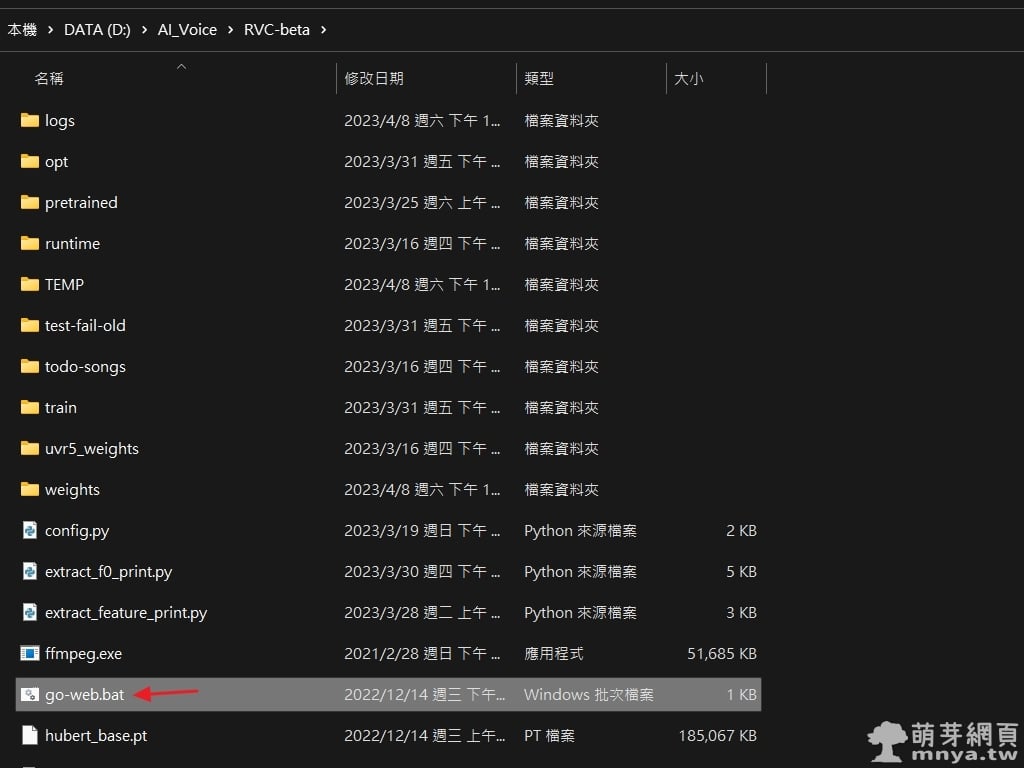
▲ 下載後解壓縮,進入軟體根目錄 RVC-beta/ 下,雙擊 go-web.bat 運行 RVC,會開啟終端機(小黑窗),預設透過瀏覽器連 http://127.0.0.1:7865 做使用,終端機視窗上會有提示。
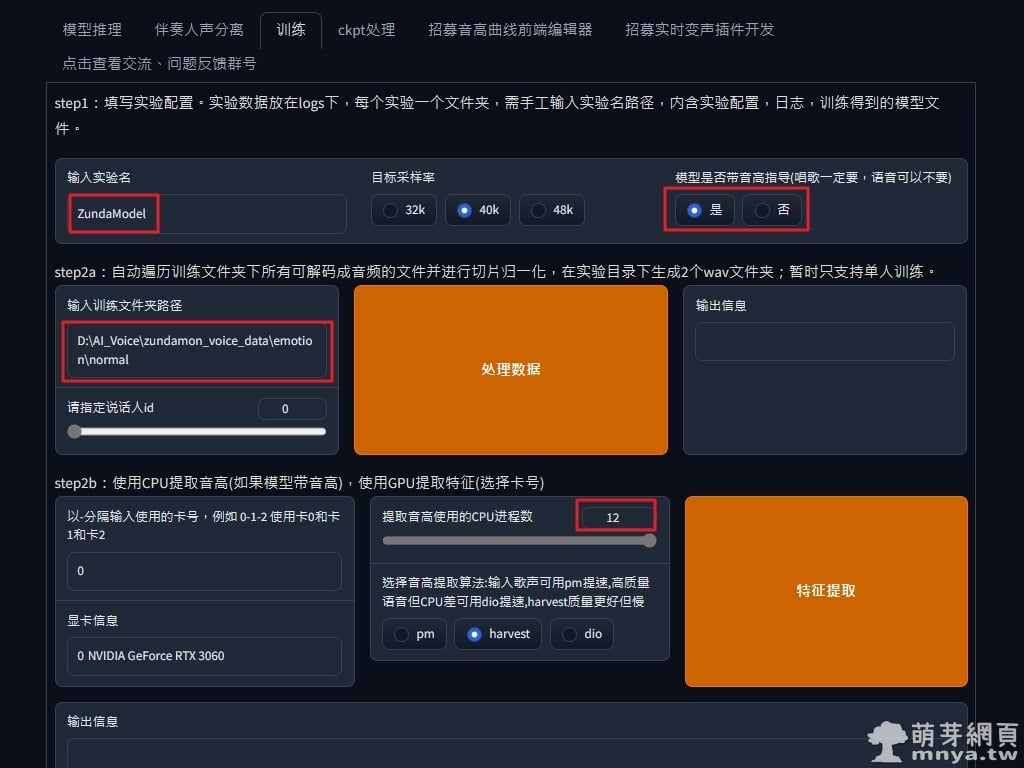
▲ 頁籤選到「訓練」,紅框的部分都是特別要修改及注意的參數!實驗名我輸入「ZundaModel」,由於是純語音,所以音高指導可以看你要不要,這邊選「是」,接著是訓練集路徑,這邊就是填剛剛下載的那一百個音檔所在的路徑(請確保路徑沒有空白,有空白會出錯),CPU 執行緒看自己電腦有多少就給多少,目前最高可以設定到 12,音高提取演算法建議用 harvest(沒有要帶音高指導就不用管這些音高相關的參數囉!)。
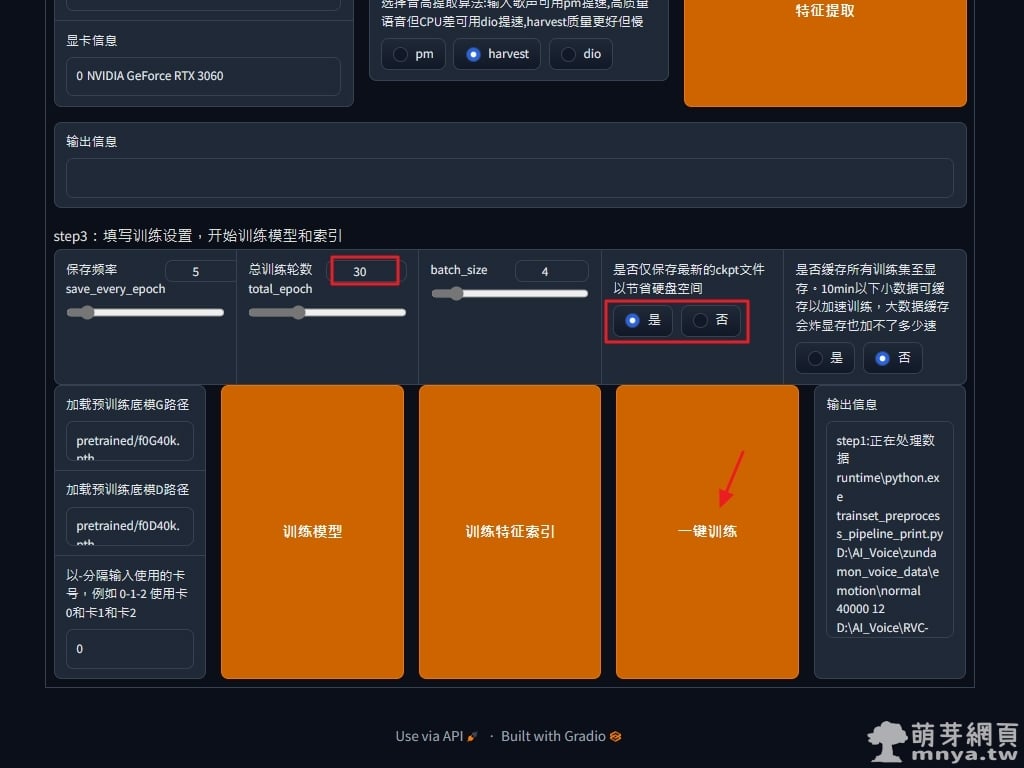
▲ 總訓練輪數這邊預設為 10,可以試著調高也許會增加訓練品質,這邊設定為 30,且僅儲存最新的訓練模型以節省硬碟空間,batch_size 越大越吃記憶體但也越快,我自己試過 8,GPU VRAM 大概會吃到接近 8 GB,首次設定先用預設的 4,吃的記憶體會少很多,最後點「一鍵訓練」開始跑訓練,這邊要等多久就看你的電腦效能,我大概十分鐘出頭。
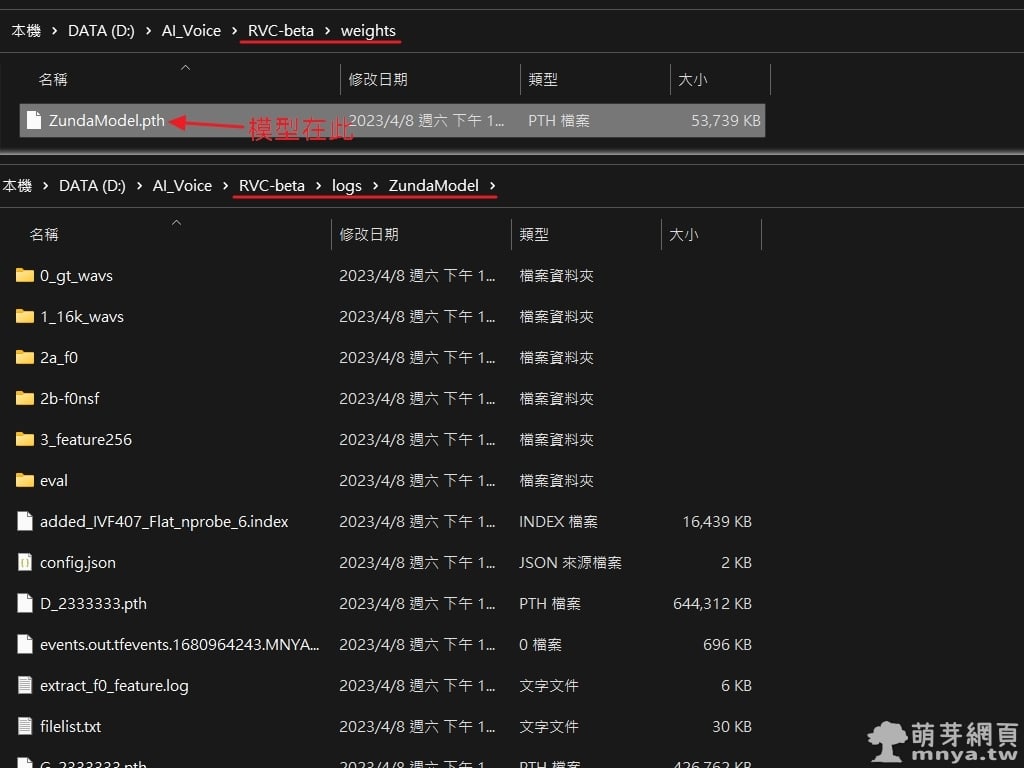
▲ 模型檔放在 RVC-beta\weights 中,副檔名為 .pth,LOG 記錄則是在 RVC-beta\logs\[實驗名] 中。
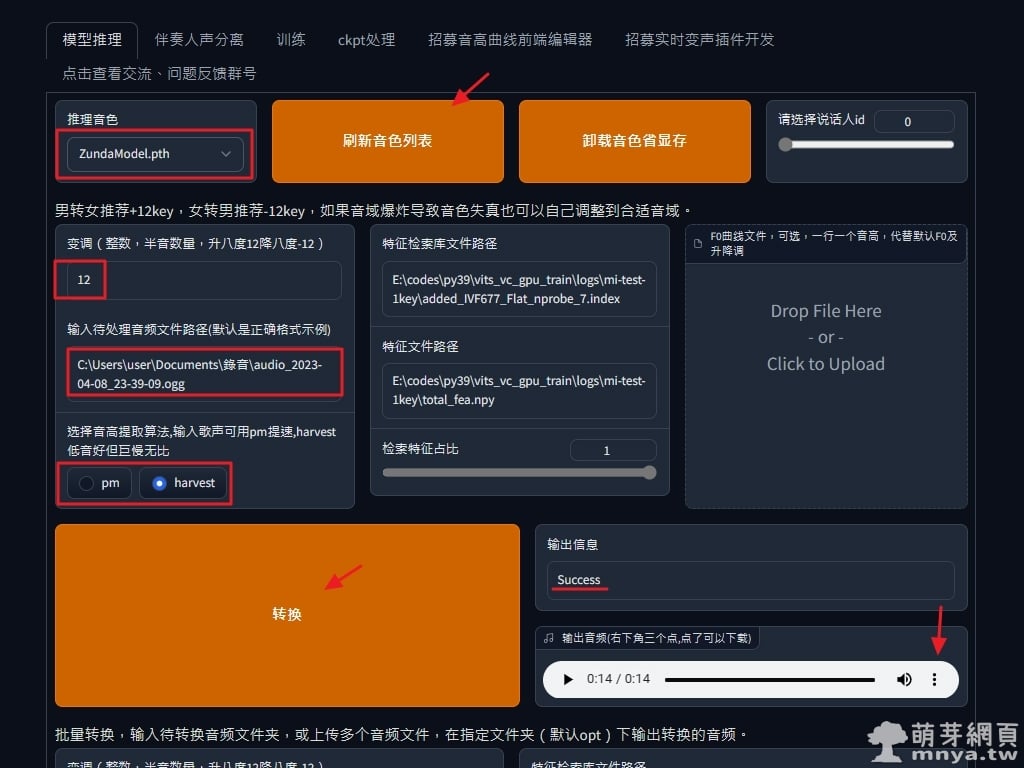
▲ 頁籤選「模型推理」,先點「刷新音色列表」,推理音色選到剛剛訓練的模型。我這邊預錄了一段自己的語音音檔,是念一段 ChatGPT 給的短故事,由於是男聲轉女聲,所以需要變調,依照建議升八度(+12key),輸入要處理的音檔,常見的格式都支援(如:.wav、.ogg),音高提取演算法仍然建議用 harvest,雖然很慢但那個品質值得等待,最後點「轉換」,看到輸出「Success」代表成功,可以立刻在輸出區試聽結果及下載成果音檔,成功將我的一段語音轉換成好像是俊達萌在說故事啦!訓練音檔是日本人講日文,我錄音用中文,轉換出來就有日本人講中文的口音,很有趣,詳情請看以下影片:
教學到此為止,歡迎大家到萌芽論壇討論或發表相關資訊!請持續關注本站取得更多相關資訊!
📝 相關文章
VC Client:用 RVC 人聲模型做即時 AI 語音轉換



 《上一篇》Stable Diffusion web UI x bilingual-localization:雙語對照翻譯!原文搭配翻譯更方便學習!
《上一篇》Stable Diffusion web UI x bilingual-localization:雙語對照翻譯!原文搭配翻譯更方便學習! 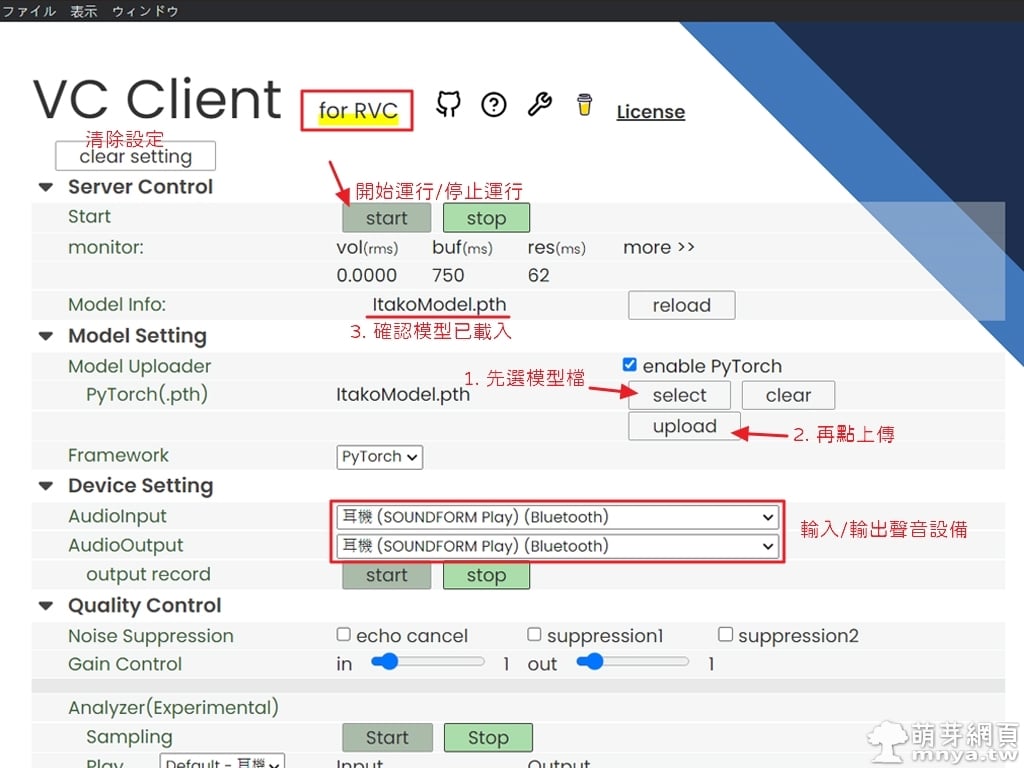 《下一篇》VC Client:用 RVC 人聲模型做即時 AI 語音轉換
《下一篇》VC Client:用 RVC 人聲模型做即時 AI 語音轉換 








留言區 / Comments
萌芽論壇