Stable Diffusion web UI 是基於 Gradio 的瀏覽器界面,用於 Stable Diffusion 模型的各種應用,如:文生圖、圖生圖等,適用所有以 Stable Diffusion 延伸的擴充模型。關於這個工具軟體的安裝方式請參考我之前寫過的另一篇圖文,請先安裝並學習使用後再接續看本文教學。這次的主題是「Dreambooth Extension」,這是一個可以讓您在不離開 web UI 的情況下自行訓練 ckpt 大型模型的擴充,DreamBooth 是指一種客製化文生圖模型的方法,可以給特定主題或風格的幾張影像來實現穩定擴散。另外由於訓練大型模型非常吃實體硬體資源,因此該擴充也進行了優化,只要做好設定就能在較低 VRAM 的 GPU 上正常跑訓練(不然可能會吃掉 2X GB 以上,極少數人才擁有這樣瘋狂的設備!),當然建議起碼要有 10 GB 以上的 VRAM 再來訓練。
Stable Diffusion web UI 官方網站:https://github.com/AUTOMATIC1111/stable-diffusion-webui
Dreambooth Extension 官方網站:https://github.com/d8ahazard/sd_dreambooth_extension
本文會從安裝擴充開始講起,中途會敘述我自己遇到的錯誤與狀況,並在後續給予排除方式,因此建議您整篇文看完再操作。開始前可以先準備訓練集,由於現在多數 Stable Diffusion 模型都是針對第一版訓練的,因此訓練集一律建議 512 x 512 px 的寬高,可以先用 AI 處理優化,針對特定主題張數不用多,針對畫風或場景的可以給百張以上訓練。另外也請先準備一個沒有裁切過的初始大模型,讓您站在巨人肩膀上再訓練大模型,而不是從零開始。
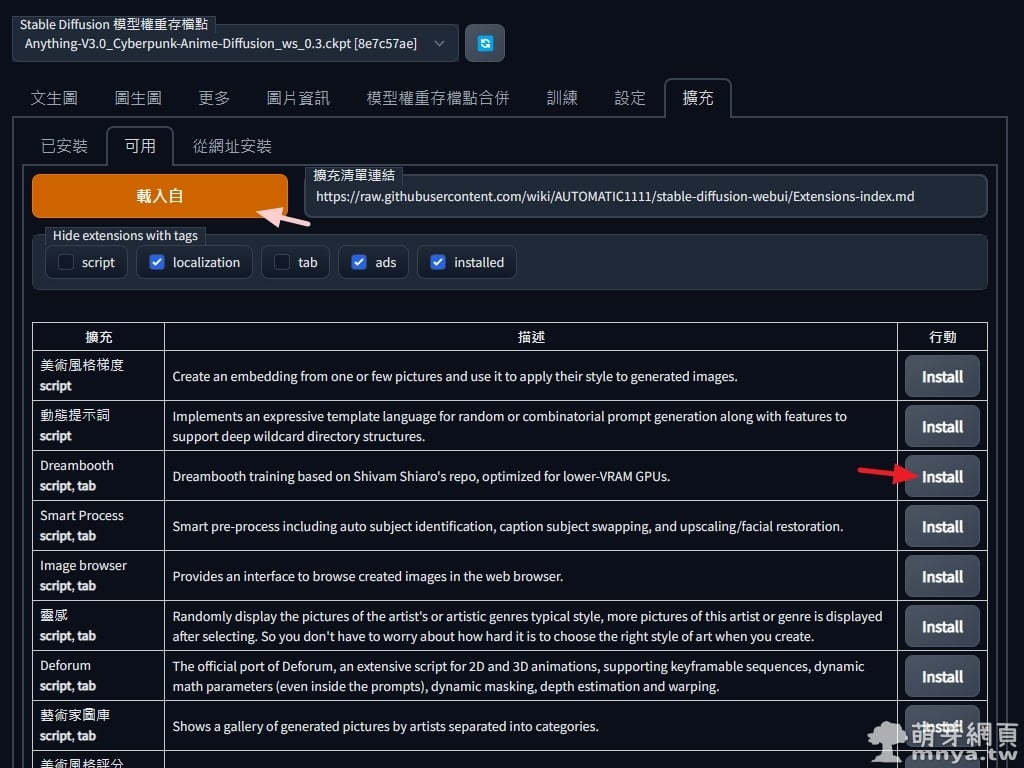
▲ 啟動 Stable Diffusion web UI,切至「擴充」頁籤,由「可用」按「載入自」先載入清單,找到「Dreambooth」擴充並安裝。
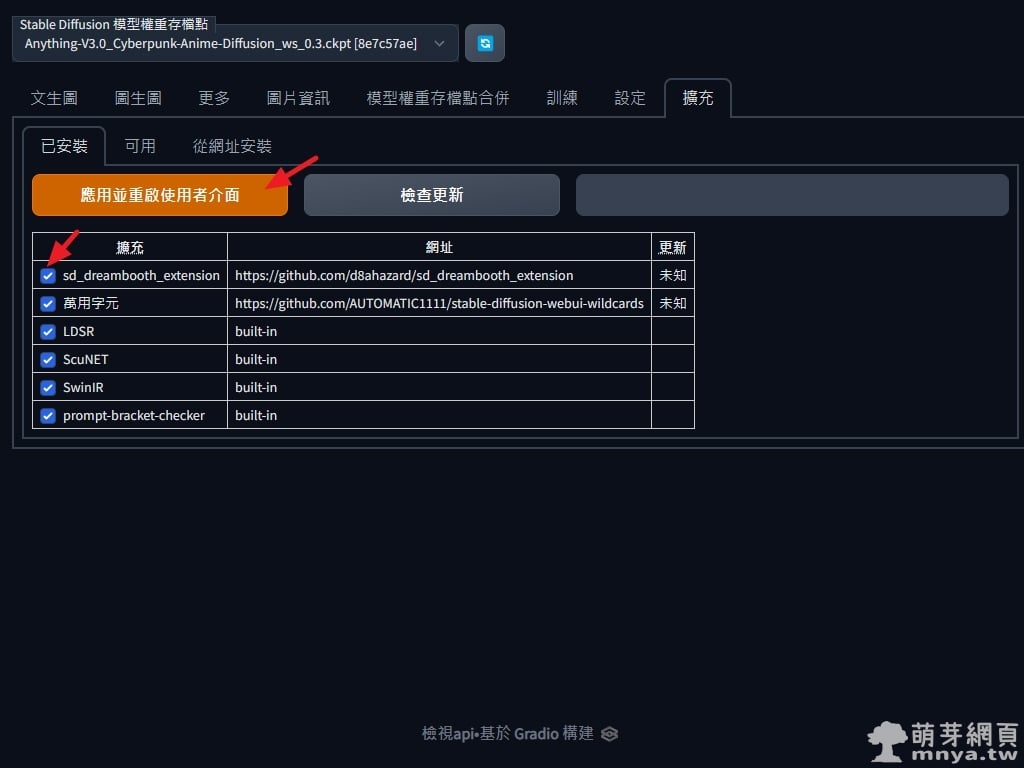
▲ 來到「已安裝」頁籤確認已勾選剛剛安裝的擴充,並點擊「應用並重啟使用者介面」,不過看來沒效果,所以接著請直接將 Stable Diffusion web UI 重新啟動再打開網頁,這樣才能確保出現「Dreambooth」頁籤!
重啟過程會開始安裝「Dreambooth」的依賴項,過程都可以在黑黑的終端機上看到,首次跑出現以下輸出:
#######################################################################################################
Initializing Dreambooth
If submitting an issue on github, please provide the below text for debugging purposes:Python revision: 3.9.13 (tags/v3.9.13:6de2ca5, May 17 2022, 16:36:42) [MSC v.1929 64 bit (AMD64)]
Dreambooth revision: c5cb58328c555ac27679422b1da940a9b19de6f2
SD-WebUI revision: 4af3ca5393151d61363c30eef4965e694eeac15eChecking Dreambooth requirements...
[+] bitsandbytes version 0.35.0 installed.
[+] diffusers version 0.10.2 installed.
[+] transformers version 4.25.1 installed.
[ ] xformers version N/A installed.
[+] torch version 1.12.1+cu113 installed.
[+] torchvision version 0.13.1+cu113 installed.
#######################################################################################################
看來有個依賴項「xformers」沒能順利安裝,後來我是將 Python 升級至 3.10.6 版本才解決問題的,升級後再啟動程式前先刪除 stable-diffusion-webui 根目錄下的 venv 目錄,在開啟程式後會自動重新安裝 Python 虛擬環境,也因此任何已安裝的模組都不會影響 Python 的現有系統安裝。
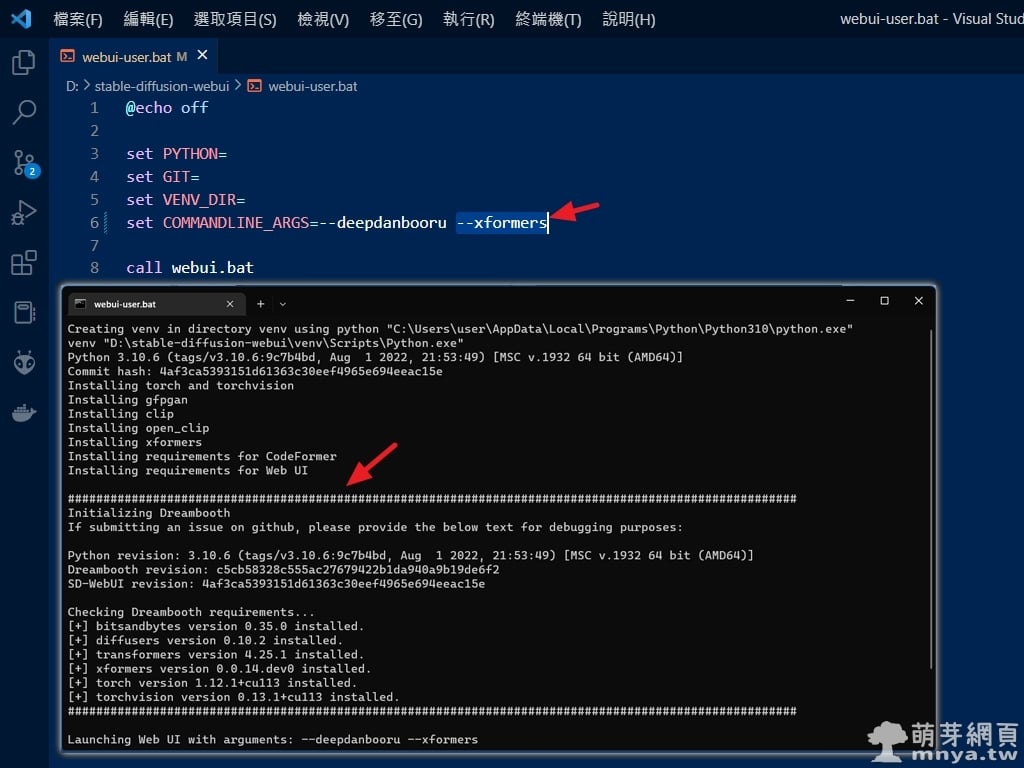
▲ 依賴項「xformers」可以修改根目錄 webui-user.bat 的 COMMANDLINE_ARGS,將 --xformers 加入以強制安裝該依賴項,如圖這樣輸出:
Creating venv in directory venv using python "C:\Users\user\AppData\Local\Programs\Python\Python310\python.exe"
venv "D:\stable-diffusion-webui\venv\Scripts\Python.exe"
Python 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)]
Commit hash: 4af3ca5393151d61363c30eef4965e694eeac15e
Installing torch and torchvision
Installing gfpgan
Installing clip
Installing open_clip
Installing xformers
Installing requirements for CodeFormer
Installing requirements for Web UI#######################################################################################################
Initializing Dreambooth
If submitting an issue on github, please provide the below text for debugging purposes:Python revision: 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)]
Dreambooth revision: c5cb58328c555ac27679422b1da940a9b19de6f2
SD-WebUI revision: 4af3ca5393151d61363c30eef4965e694eeac15eChecking Dreambooth requirements...
[+] bitsandbytes version 0.35.0 installed.
[+] diffusers version 0.10.2 installed.
[+] transformers version 4.25.1 installed.
[+] xformers version 0.0.14.dev0 installed.
[+] torch version 1.12.1+cu113 installed.
[+] torchvision version 0.13.1+cu113 installed.
#######################################################################################################Launching Web UI with arguments: --deepdanbooru --xformers
Dreambooth API layer loaded
[...]
這樣所有需要的依賴項都安裝完畢,能順利在本機上運作啦!接下來能不能正常訓練就看 GPU 是否給力了!
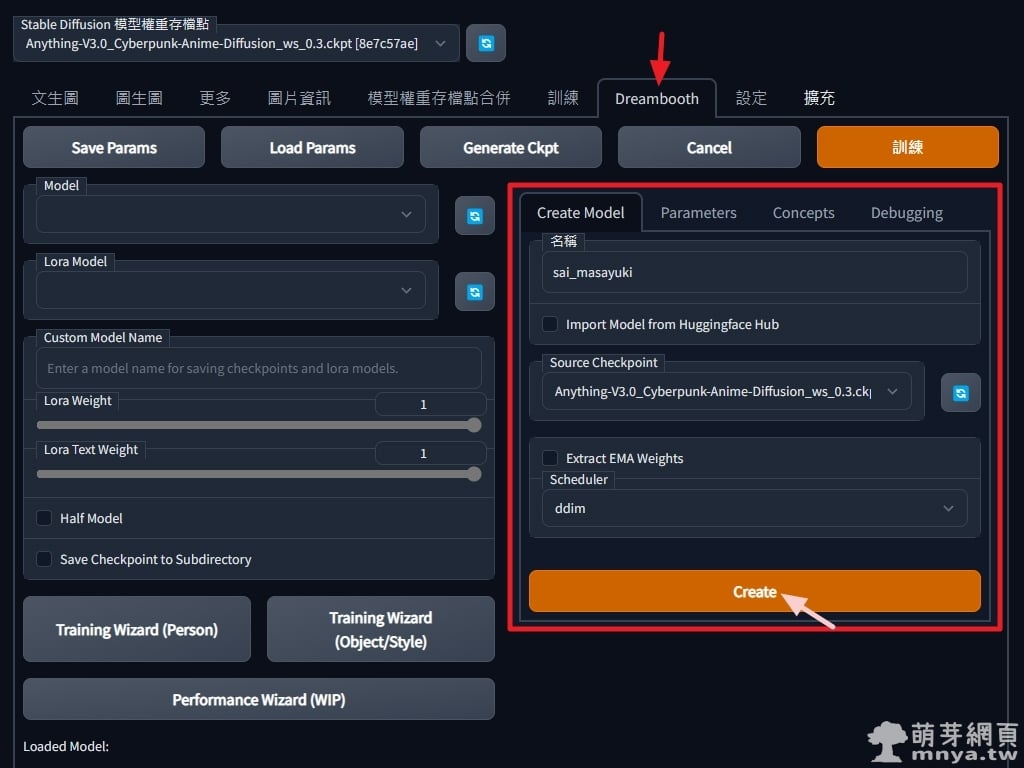
▲ 我這次借用「彩 雅介」的免費素材來訓練大模型,因此模型名稱就用他的拼音,來看看到時候能不能融合各種元素了!記得要選擇一個來源大模型以進行再訓練,其他參數照我的填法即可,點「Create」建立模型。
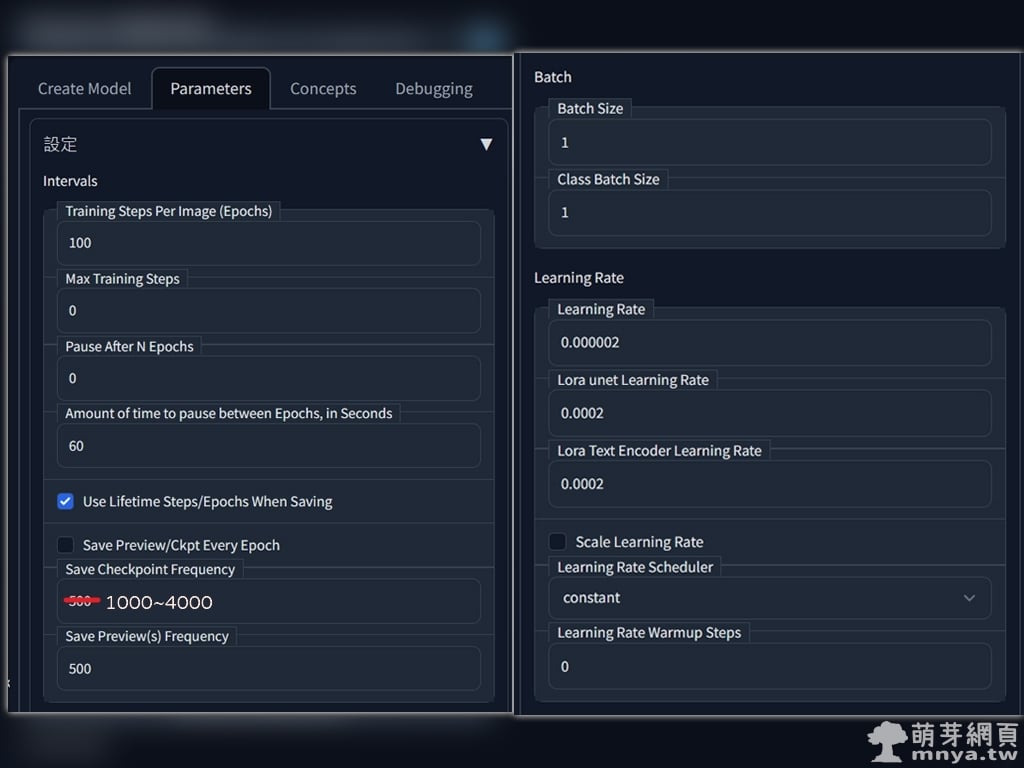
▲ 這些選項的介紹可以在 GitHub 上看到,這邊的參數僅供參考,大多都不用更動用預設的就好。特別挑幾個重要的:
「Training Steps Per Image (Epochs)」代表一張訓練用圖訓練 n 步,預設每張訓練 100 步,所以我有 120 張圖就是要訓練 12,000 步。
「Save Checkpoint Frequency」代表每 n 步儲存一個大模型(會存到 stable-diffusion-webui\models\Stable-diffusion)。
「Save Preview(s) Frequency」代表每 n 步生成一張預覽圖(會存到 stable-diffusion-webui\models\dreambooth\[模型名稱]\samples)
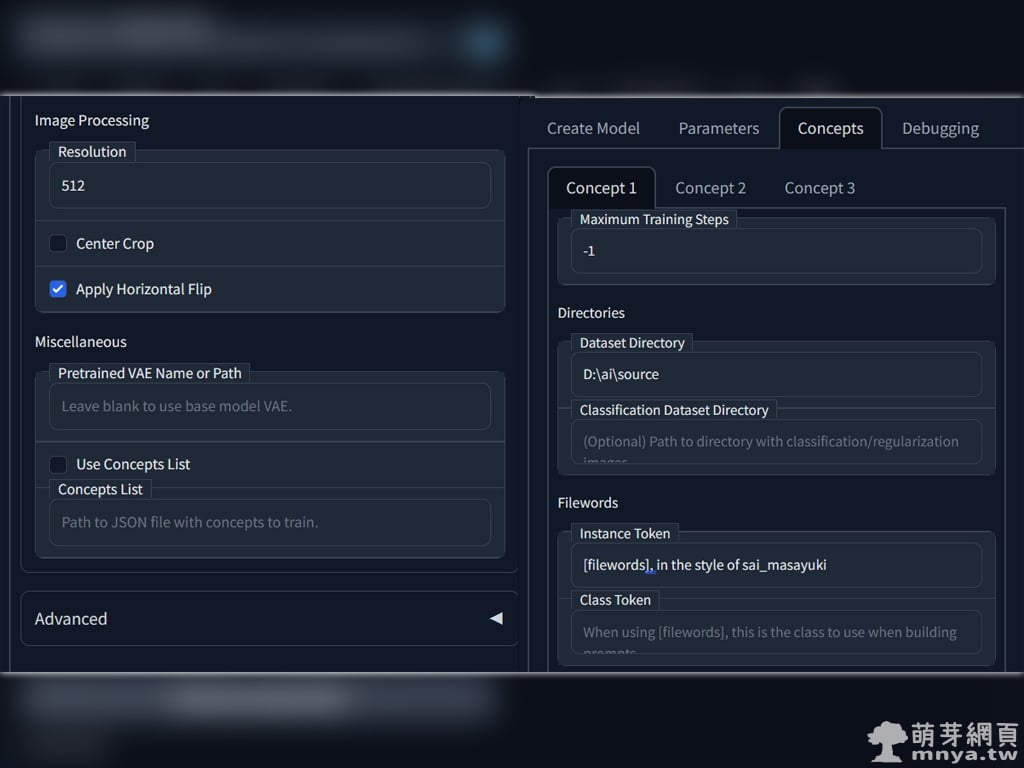
▲「Parameters」弄完,切到「Concepts」,選 Concept 1 做設定就好。一樣挑一些重要的說明:
「Dataset Directory」為訓練集路徑,裡面應該都是 512 x 512 px 的圖片。
「Instance Token」實例提詞輸入,可以透過一些提詞或 [filewords] 的方式輸入,未來生圖就輸入這些關鍵字來引導 AI。
▲ 這邊設定我都沒動,預設就好。
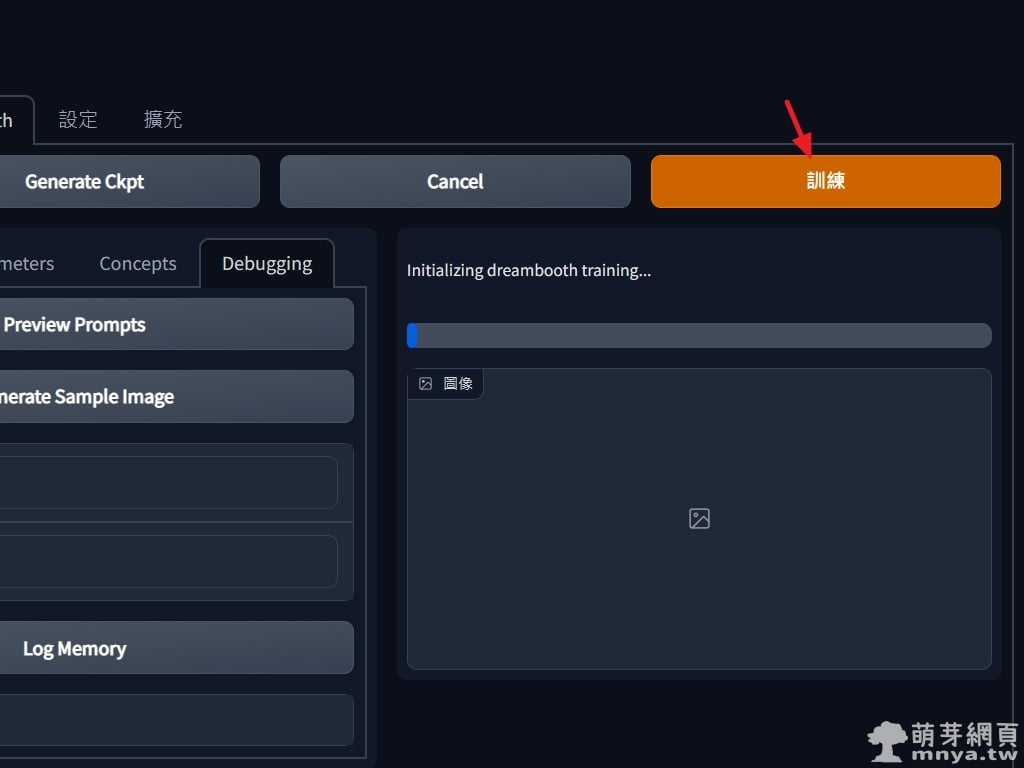
▲ 接著到右上點「訓練」就可以開始跑啦!不過你大概會遇到問題,並看到以下資訊在終端機:
RuntimeError: CUDA out of memory. Tried to allocate 50.00 MiB (GPU 0; 12.00 GiB total capacity; 11.15 GiB already allocated; 0 bytes free; 11.27 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
對!GPU 的 VRAM 不夠用!所以你要回到「Parameters」的「Advanced」來做一些降低 VRAM 使用的設定。
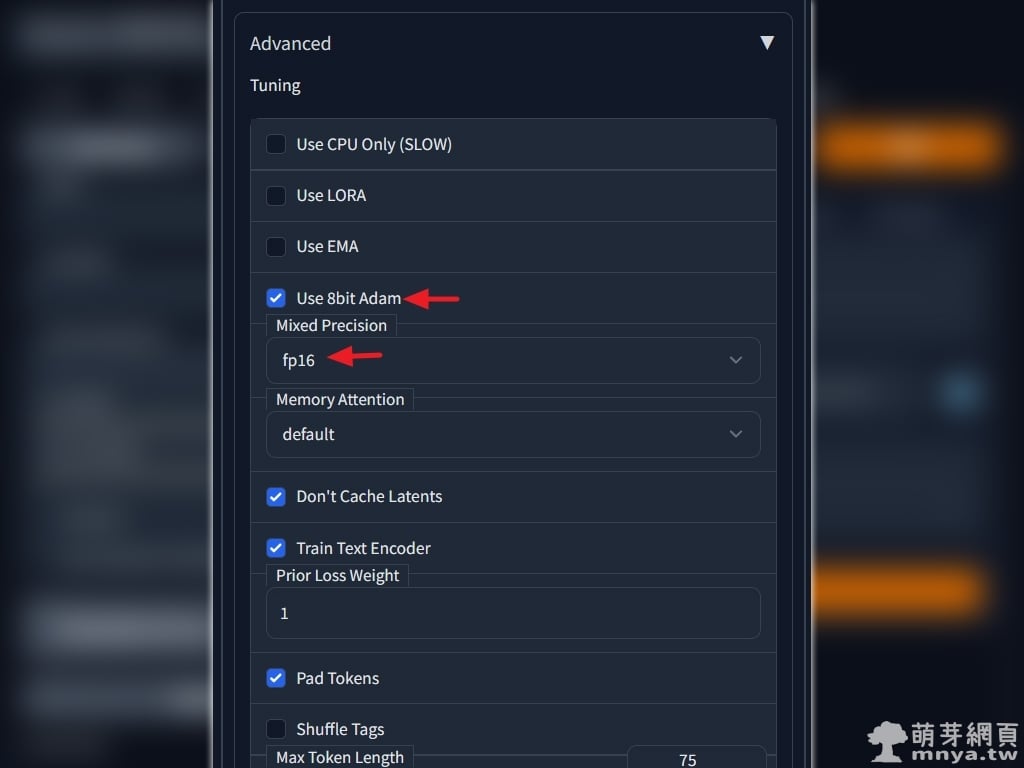
▲ 紅色箭頭處設定好,可以用犧牲速度換取 VRAM 的用量喔!左上「Save Params」按鈕可以儲存設定參數,然後這邊要重新啟動程式,不然一樣會出錯的!
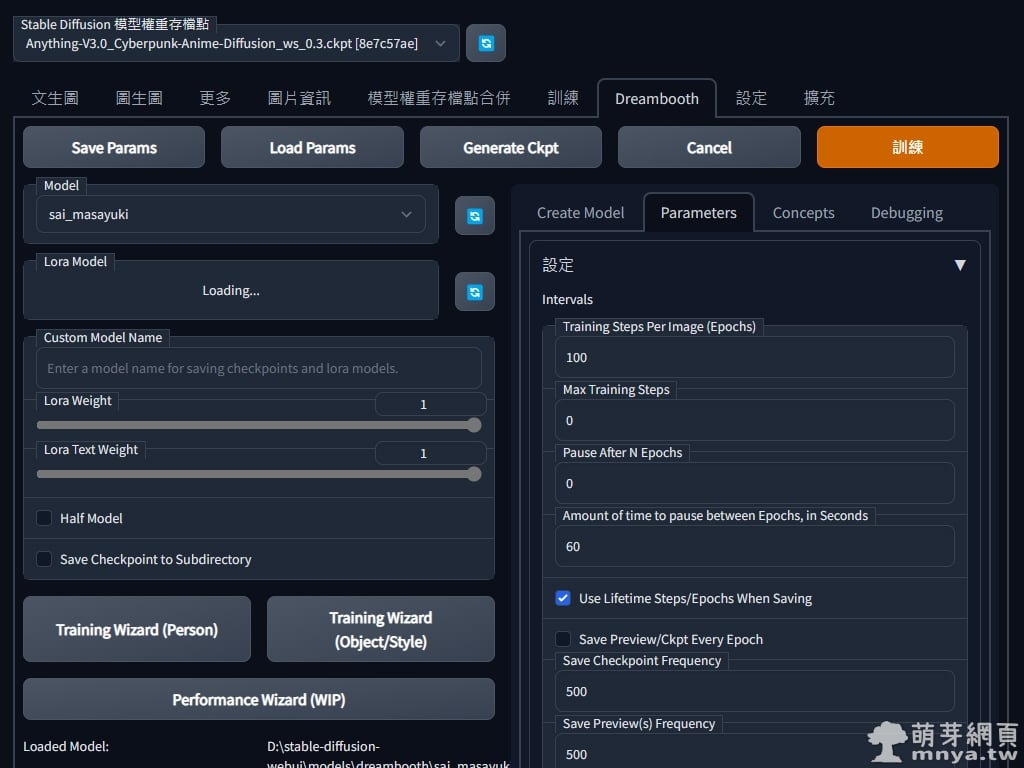
▲ 重新啟動後參數跑掉,先選好模型,再點「Load Params」就能找回參數。總算可以正常訓練啦!就耐心等待吧!我約等兩小時,使用的顯示卡為 GeForce RTX 3060 12G,訓練過程也吃了不少 RAM,我的電腦有 32GB 就還好沒太大問題。
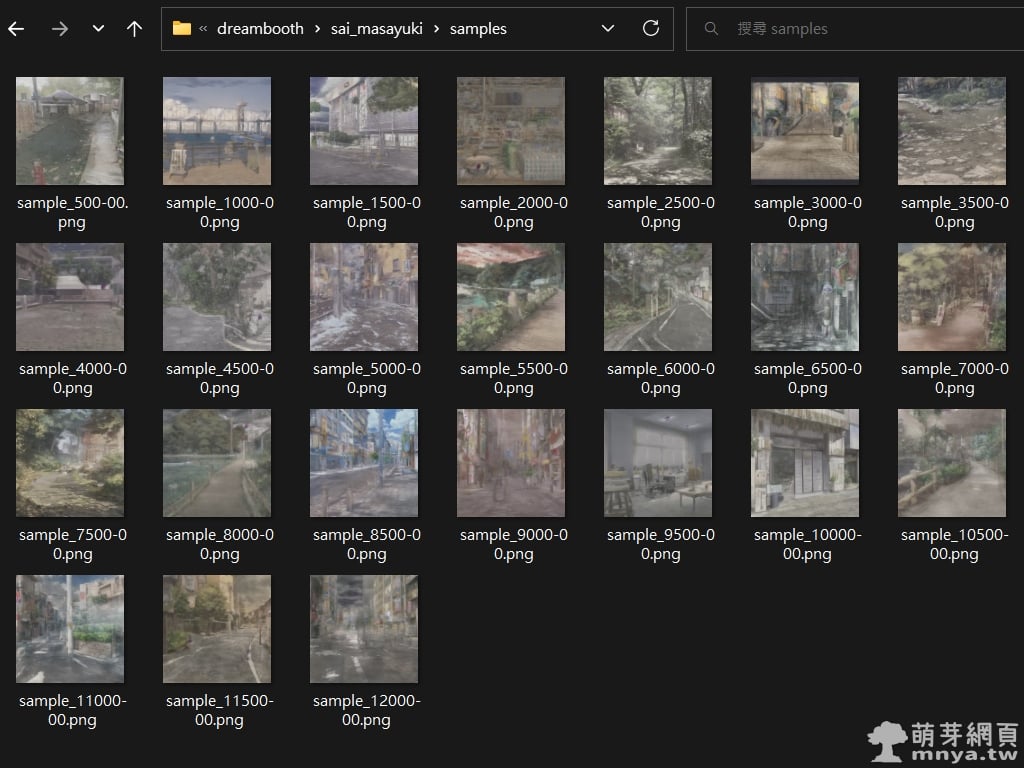
▲ 訓練完畢,可以到 stable-diffusion-webui\models\dreambooth\[模型名稱]\samples 路徑下查看預覽圖。
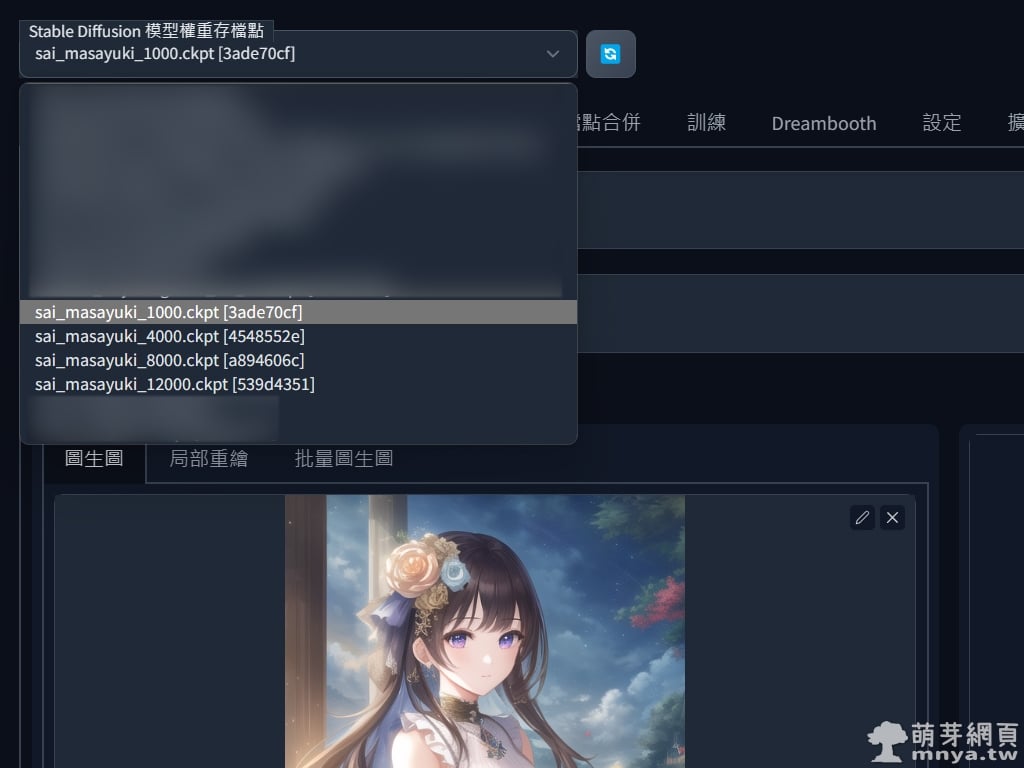
▲ 剛剛設定是每 4000 步存一個大模型,1000 步的是我原來設定錯出來的,因為生太多模型硬碟會爆,一個模型大 4 GB!接著就是切過去訓練好的模型就能開始 AI 繪圖了!
我先用一樣的參數,選用不同訓練步數下的模型來算圖,輸出結果如下:


果然用背景素材訓練拿來畫背景就是很OK!物件、構圖、畫風都算有學到。少步數下會誘導出原來模型的潛力!這個也很有意思。再來是把少女放入超美的背景中,由於訓練集完全無人,所以大步數下的模型人物很難正常生成出來,因此就拿 1000 步的模型來用:

蠻有意思的,真的把原來單調的背景變好看很多餒!但看樣子大模型訓練步數真的不能太多,不然很難跟原有的東西混合用,步數越多失去越多原有的特徵,很多提詞會失效。好了!接著就拿 4000 步訓練的模型直接畫各種風景作品!




其實能看出來真的出現不少訓練集中的元素,不過很明顯是一張全新的作品,透過提詞與相關參數的調整,能得到完全不同的輸出成果,AI 繪圖有趣的地方就在這裡,永遠不會輸出一模一樣的作品!除非參數全部固定、種子碼也固定、模型還要一模一樣。
有興趣的人可以再更深入研究!巧妙運用可以讓 AI 什麼都畫得出來,很強大的工具。



 《上一篇》Docker Desktop:安裝官方提供的三個擴充,方便查詢 Log、硬碟空間及系統資源用量!
《上一篇》Docker Desktop:安裝官方提供的三個擴充,方便查詢 Log、硬碟空間及系統資源用量!  《下一篇》Telegram 9.2 for Android & Telegram Desktop 4.4 更新:無 SIM 卡註冊、自動刪除所有聊天記錄、群組主題 2.0 等
《下一篇》Telegram 9.2 for Android & Telegram Desktop 4.4 更新:無 SIM 卡註冊、自動刪除所有聊天記錄、群組主題 2.0 等 








留言區 / Comments
萌芽論壇