SD web UI 全稱 Stable Diffusion web UI,是本次要搭配使用 ControlNet 的 AI 繪圖工具。Reference-Only 是不需要任何控制模型的預處理器,ControlNet 1.1.153 後的版本才能使用,它能直接使用影像作為參考來引導擴散。根據開發者的說明,這個方法與基於修補的參考方法類似,但不會使影像變得雜亂無章,這個 ControlNet 可以直接連接您的 SD 的注意力層到任何獨立影像,這樣您的 SD 就可以讀取任何影像作為參考。實際用起來,對於光線、顏色的參考效果非常明顯,幾乎可以說不用 LoRA 訓練就能極為接近輸入 ControlNet 影像的樣子,只要提點一些重點提詞(不要有顏色相關的提詞),就能生出相當接近原始角色不同動作、表情的影像,當然如果能搭配 LoRA 肯定更加完美。這次的參數及示範供大家參考,相信能有更多意想不到的運用,歡迎大家到萌芽論壇分享您的成果。
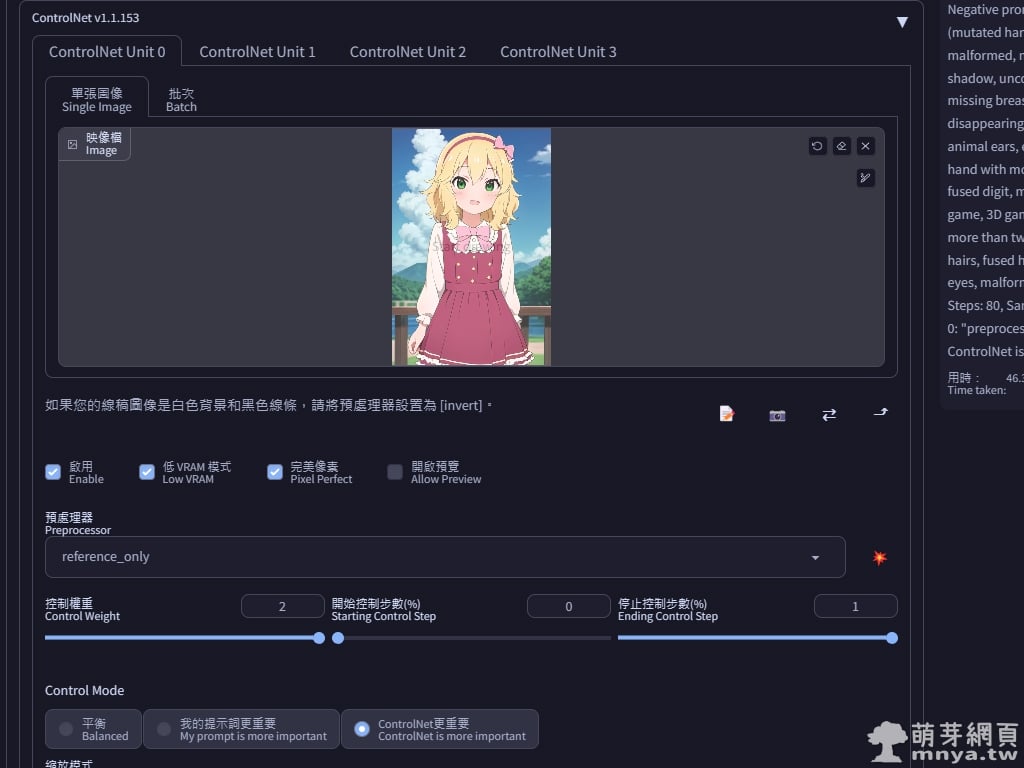
▲ 更新完 ControlNet 後,預處理器可以選擇最新的 reference-only,無須選擇模型,只需要輸入一張影像,接著我把控制權重調到 2,並以 ControlNet 更重要來作為控制模式。
實際生成結果
統一使用以下參數進行生成 ▼
提詞:1girl, solo, closed eyes, smile, (chibi:1.2), __posture__
__posture__:standing\nstanding\n(contrapposto:1.1)\n(contrapposto:1.2)\n(sitting:1.1)\n(sitting:1.2)
參數:Steps: 80, Sampler: UniPC, CFG scale: 7, Size: 512x768
我提詞故意用的非常少,就想看看它能參考輸入影像到什麼程度。基本上就是希望不載入 LoRA 的情況下,直接讓其閉眼跟更加 Q 版,姿勢讓它隨機,來看看結果如何吧!
一、喜多郁代
左圖參數及 LoRA 來自萌芽二次元,右圖是以 Reference-Only 搭配新的參數生成的。

二、櫻井桃華
左圖參數及 LoRA 來自萌芽二次元,右圖是以 Reference-Only 搭配新的參數生成的。

本文到此結束,希望有幫助到大家。



 《上一篇》SD web UI x siitake-eye LoRA:為 AI 繪製的二次元角色添加閃閃發光的香菇眼(しいたけ目)
《上一篇》SD web UI x siitake-eye LoRA:為 AI 繪製的二次元角色添加閃閃發光的香菇眼(しいたけ目)  《下一篇》SD web UI x glowing-glasses LoRA:為 AI 繪製的二次元角色添加發光的眼鏡
《下一篇》SD web UI x glowing-glasses LoRA:為 AI 繪製的二次元角色添加發光的眼鏡 








留言區 / Comments
萌芽論壇