Kohya's GUI 這款軟體是專門給 AI 繪圖領域進行模型訓練的工具,可以用來訓練 Stable Diffusion 1.5、2、SDXL 的各種模型,這邊我要示範將 VRAM 控制在 12GB 內的使用量,讓 3060 12GB 這樣等級的顯示卡就能完成訓練 SDXL 專用 LoRA 模型的任務。這邊我參考了網路上數個教學文章與影片,最終得到了最佳的參數,讓我得以在大概一小時左右的時間就訓練出 1500 步的 LoRA 模型,且最終交由 Stable Diffusion web UI 生成時也能有相當好的效果,比起 SD 1.5,SDXL 生成效果更佳,爛手的機率也降低不少,人物表情也更加豐富生動。本文參數是以生成二次元人物調整的,如果您想要訓練的是真人,那麼可能需要更多的步數,更高的 Network Dimension 和 Network Alpha(這兩個參數會決定 LoRA 模型的大小,預設為 8 和 1,通常 Network Alpha 會小於 Network Dimension 的一半,真人或風格訓練需要比較高的 Network Dimension 和 Network Alpha),另外為了使 VRAM 控制在最小的使用量,優化器(Optimizer)我採用 Adafactor,這款優化器可以最低化 VRAM 的使用,實際訓練一系列 768 x 768 的訓練集圖片,搭配將 Gradient checkpointing 啟用,能大大減少 VRAM 使用,最終使用約 11.7GB 的 VRAM,另外您若使用 RTX 系列顯卡,我也非常推薦將精度(Precision)設定為 bf16,能大大加速訓練時間!當然若遇上錯誤,就請切回使用 fp16,其他的參數會在文內簡單說明及展示。
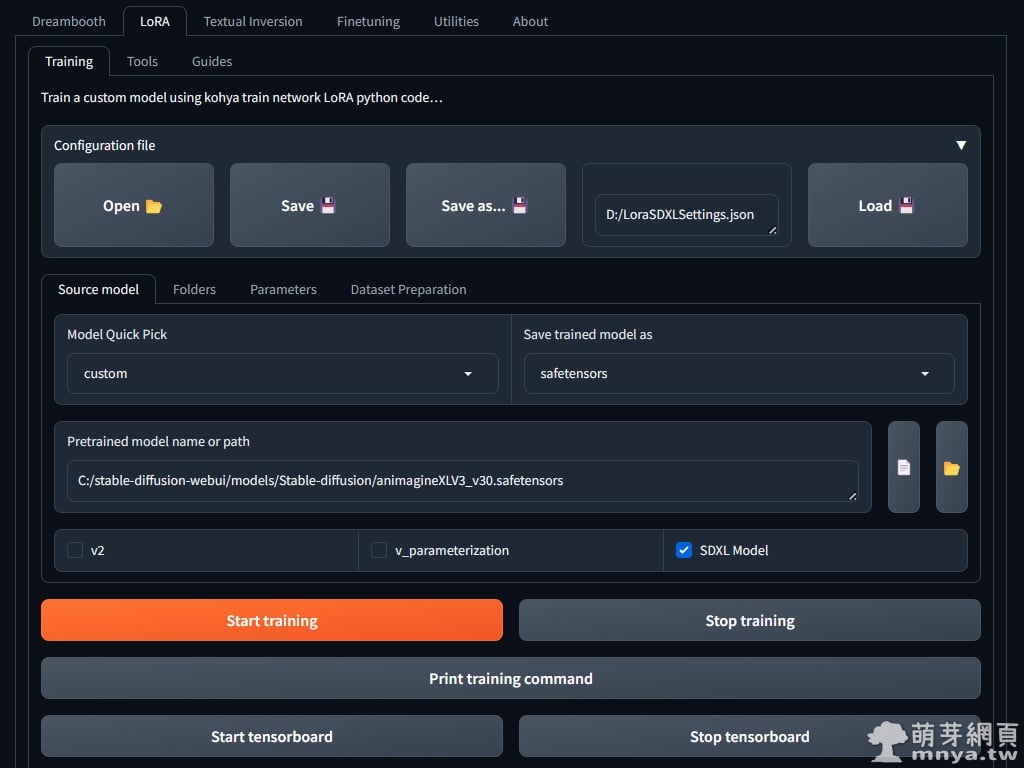
▲ 這邊我選擇以 Animagine XL V3 這款二次元的 SDXL 大模型為基底訓練 LoRA 模型,記得要將 SDXL Model 的勾選打勾。
如果好奇 Animagine XL V3 這款大模型的生成效果,可以去萌芽二次元看站長的生成作品:點我
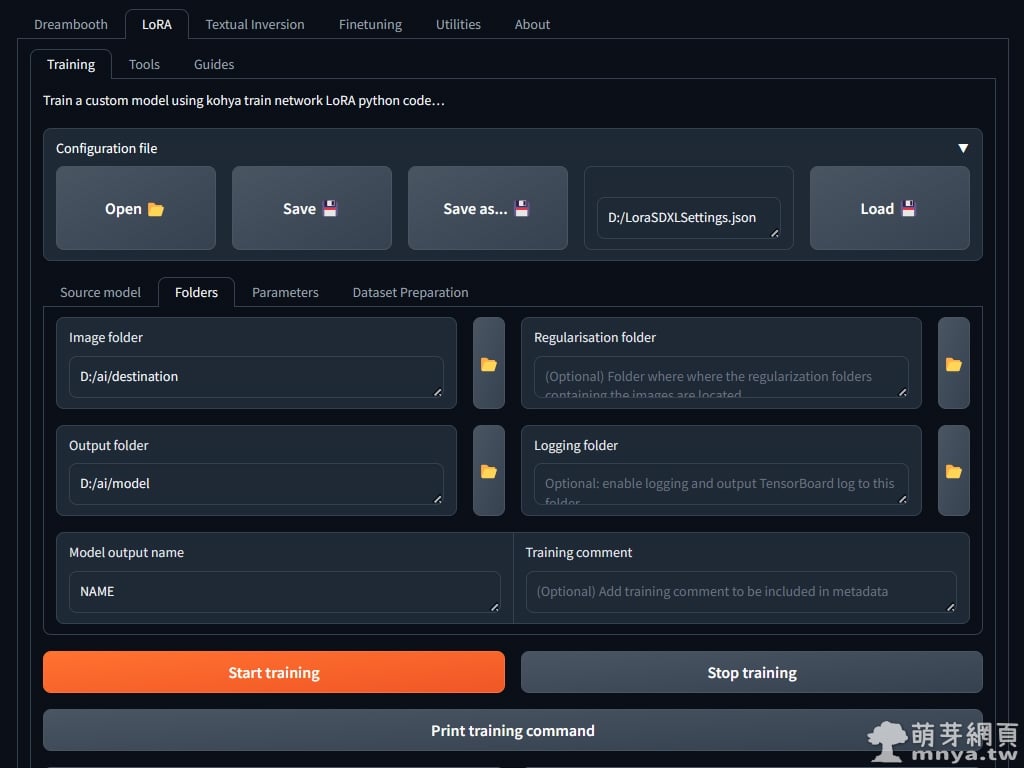
▲ 資料夾安排的部分我是依照個人喜好這樣設定:
資料夾安排
📂 D:\ai\source -> 訓練圖片放的資料夾(已經去雜訊跟裁切為 1:1 比例)
📂 D:\ai\model -> LoRA 模型輸出位置
📂 D:\ai\destination -> 整理過後訓練圖片放的位置,子目錄會設為「25_NAME」,名稱依照您要訓練的主題命名,訓練時會讀取該資料夾內的圖片與 txt 提詞註記
這次我共準備了 12 張訓練圖片,每張 25 次訓練,事後加上 Epoch 設定為 5,這樣總步數會來到 12*25*5=1500 步,且每 12*25=300 步會生成一個 LoRA 模型,總共會生成五個 LoRA 模型,分別代表 300、600、900、1200、1500 步的訓練,這樣有助於事後一個個測試訓練成果。
關於圖片集的處理,您可以參考我早期撰寫的 SD 1.5 LoRA 模型訓練教學:點我
接著我會一個個部分截圖,並在圖下做些重點說明:
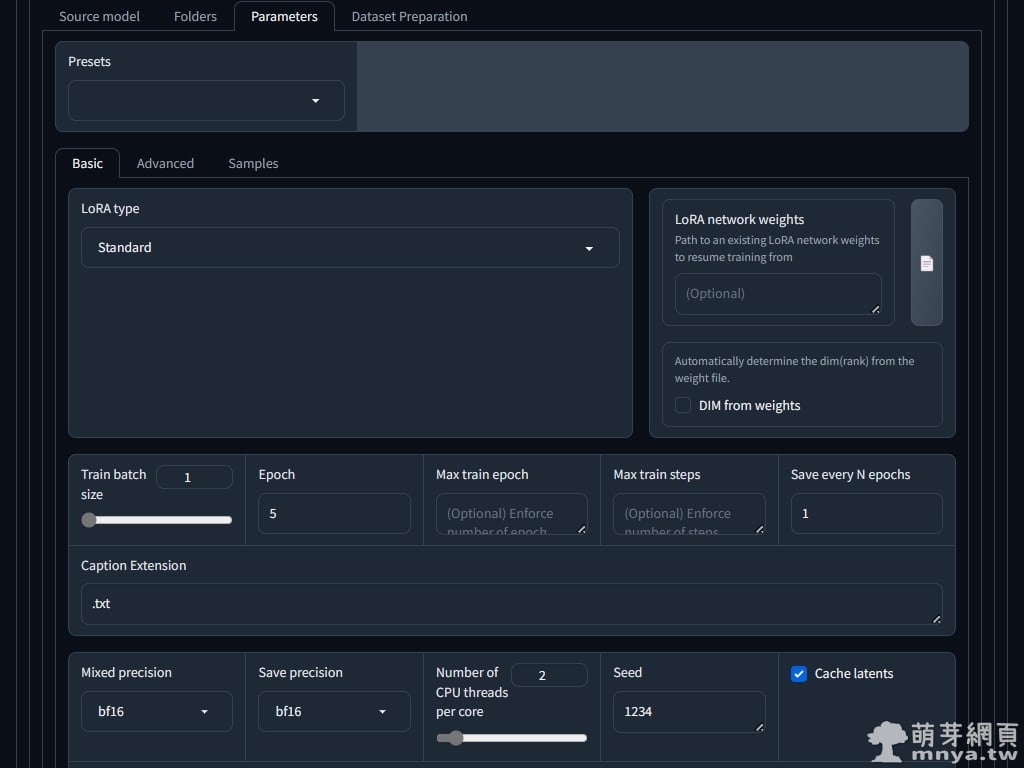
▲ LoRA 種類百百種,我這邊訓練標準的就好。訓練批次(Train batch size)通常建議預設 1 就好,增加數字會大大增加 VRAM 的使用,如果您擁有超大的 VRAM 再考慮增加數字,可以加速訓練。紀元數(Epoch)看需求,可以配合每張訓練步數,達到每 X 步生成一個模型的效果。有關精度(Precision)的建議都設定為 bf16,Cache latents 跟 Cache latents to disk 我都建議打開,可加速整個訓練過程。
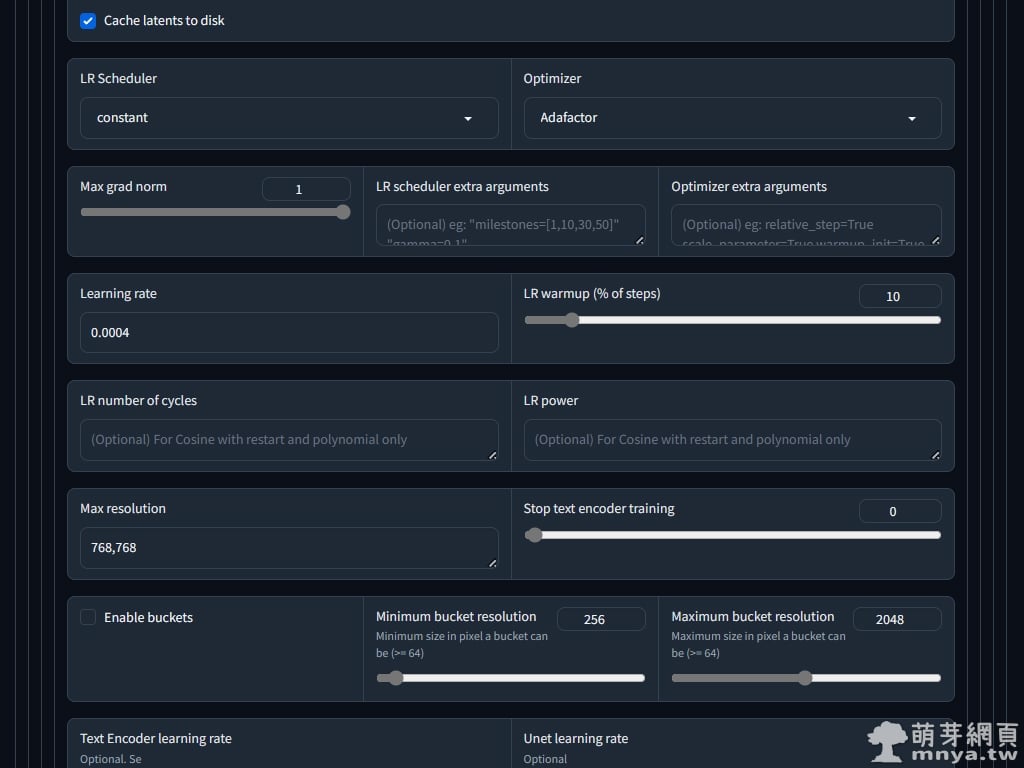
▲ 優化器(Optimizer)我採用 Adafactor,這款優化器可以最低化 VRAM 的使用。學習率(Learning rate)預設為 0.0001,學習率指定了神經網路中權重(也就是連結的厚度)的改變速度,以便製作與給定圖片完全相同的圖片,但每次給定圖片時,權重都會改變。如果對給定圖片調整得太多,就無法繪製其他圖片了。為了避免這種情況,訓練時每次都稍微調整一點權重,以更好地納入給定的圖片。學習率決定了這種"稍微"的量。我這邊給予 0.0004。最大解析度(Max resolution)我設定為 768,768,這樣超過這個解析度的圖片都會以最大 768 px 的邊做訓練,雖然訓練圖片我都事先調整裁切過了!請不要啟用 Enable buckets,因為我事先都已經將圖片預處理好,大小都一樣。
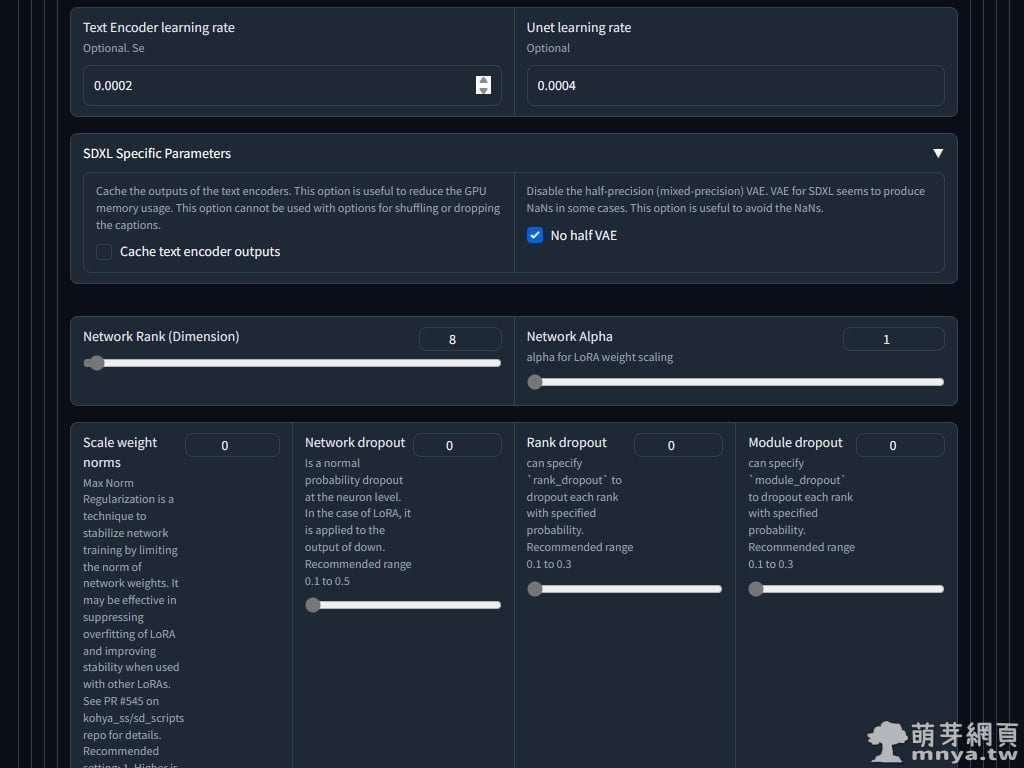
▲ 文字編碼器學習率(Text Encoder learning rate)預設 0.00005,通常會為 U-Net 學習率(Unet learning rate)的一半,U-Net 學習率預設為 0.0001,我設為 0.0004,因此文字編碼器學習率我就設定 0.0002,就是預設的四倍。請將 No half VAE 打勾,這可以避免 NaNs 發生的情況。Network Dimension 和 Network Alpha 這兩個參數會決定 LoRA 模型的大小,預設為 8 和 1,數字越大 LoRA 能記憶的細節就越多,因此二次元的訓練大概預設就足夠,真人或風格訓練則要調更高,讓模型能訓練到更多細節。Network Alpha 是用來削弱權重的,建議不設定超過 Network Dimension 的一半。
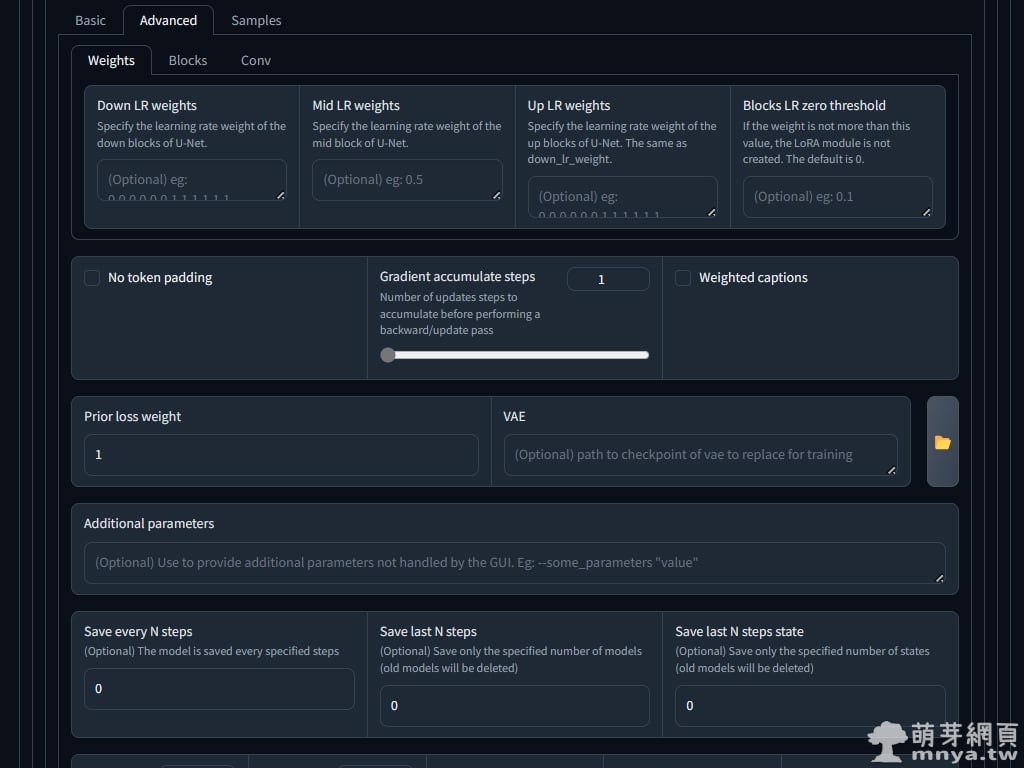
▲ 來到進階設置的部分,這塊就依照我的設定,大多都是預設值。
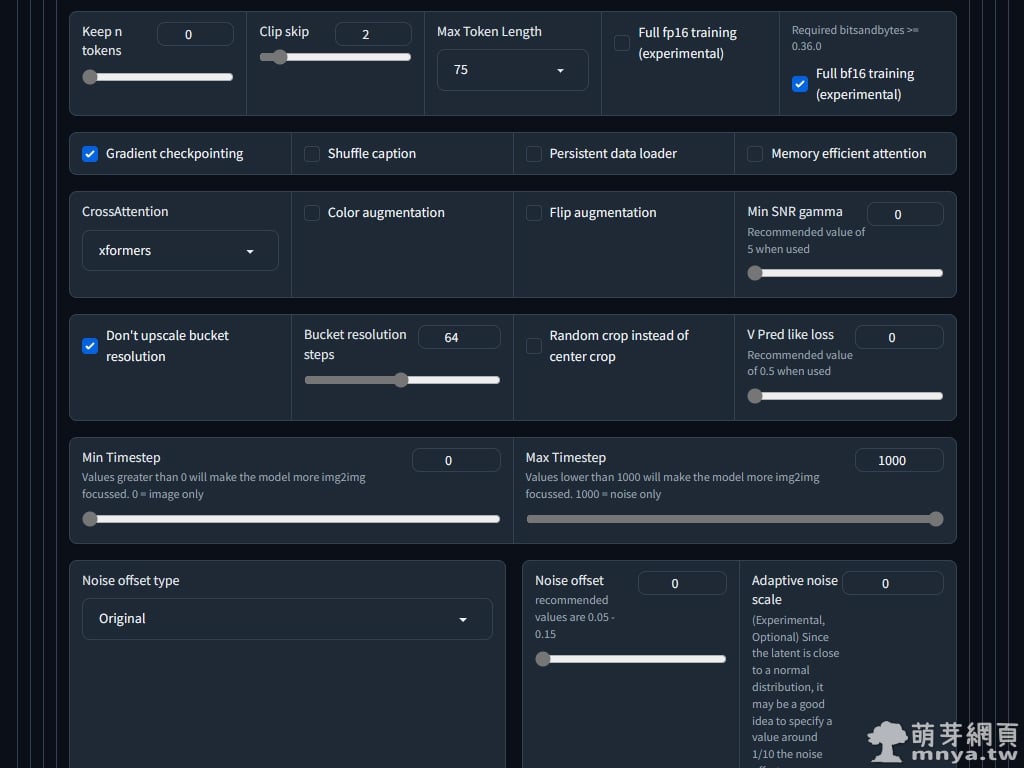
▲ Full bf16 training (experimental) 打勾。Gradient checkpointing 請啟用,能大大減少 VRAM 使用。CrossAttention 建議選 xformers。其他請照我的設定。
▲ 這一部分也都是依照預設值就好。
最後就是按 Start training 開始訓練,我用 RTX 3060 12G 顯示卡跑大概每 15 分鐘可以訓練 300 步,75 分鐘大概能訓練完 1500 步,二次元的訓練步數大概都要抓到 1500 步,再從中挑選適合的,有些人物細節比較少,就能以較少的步數生成相似的人物圖片,AI 繪圖的世界就是這麼奇妙!希望這篇文章能幫助大家訓練 SDXL 專用的 LoRA 模型,站長也要開始改用 SDXL 了!但個人認為 SD 1.5 還是有使用的價值,因為它能在極低的硬體條件下訓練跟生成圖片,但是以成品品質來說,是該將硬體升級使用 SDXL 了!


 《上一篇》【KINYO】Type-C U鋅條紋 極速充電傳輸線-1.2M (USB-C07)
《上一篇》【KINYO】Type-C U鋅條紋 極速充電傳輸線-1.2M (USB-C07)  《下一篇》Xiaomi 小米 筋膜按摩槍
《下一篇》Xiaomi 小米 筋膜按摩槍 








留言區 / Comments
萌芽論壇