過去我使用 Stable Diffusion web UI 做標籤(提詞、咒語)反推都是靠 DeepDanbooru 去做,不過這個工具相對簡陋,因此有人開發出更進階的工具 Tagger(中文為「標記器」),除了可以做單張影像的分析反推外,還能直接以目錄(資料夾)為目標批次處理多張影像喔!非常方便,特別是針對需要做模型訓練的人來說更是實用。另外這個擴充預設以一個圖像到文本模型為基礎反推提詞的,該模型是由 MrSmilingWolf 建立,主要是為了訓練 Waifu Diffusion,因此反推出來的基本上都是 booru 樣式的提詞,多用於二次元動漫風格人物等的 AI 繪圖。那現在就教大家如何安裝及使用吧!
🔗 Tagger:https://github.com/toriato/stable-diffusion-webui-wd14-tagger
現在開始圖文教學:
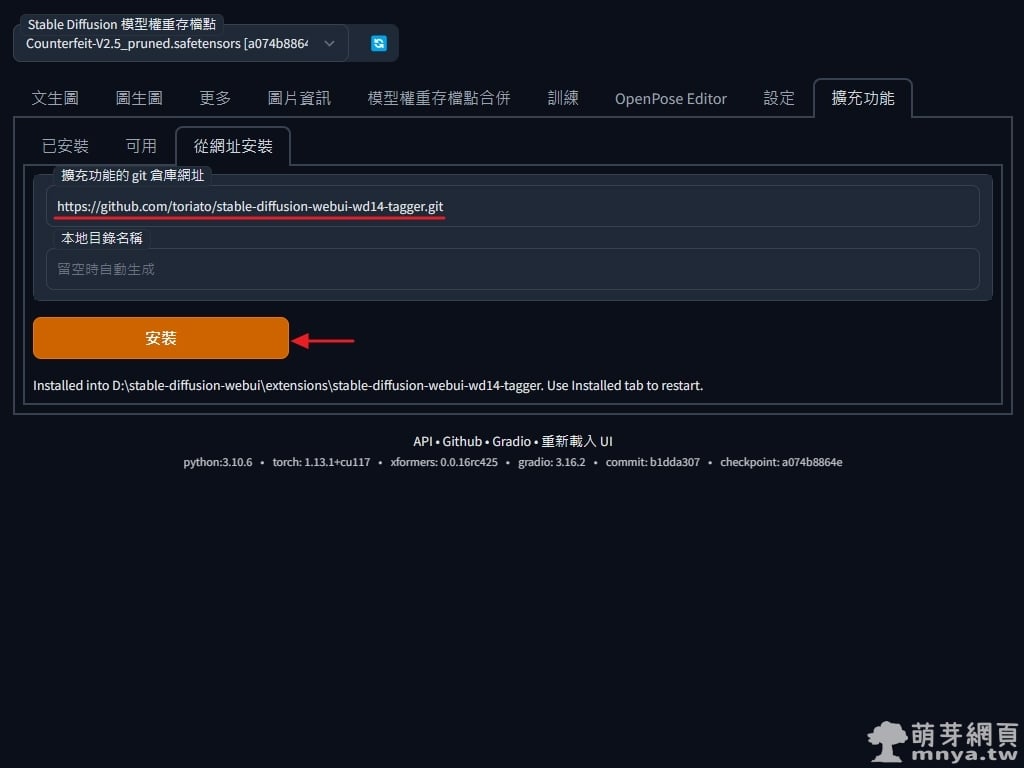
▲ 打開 Stable Diffusion web UI 切到「擴充功能」頁面,選「從網址安裝」,將擴充功能完整的 git 網址(即 https://github.com/toriato/stable-diffusion-webui-wd14-tagger.git)輸入進去再點「安裝」按鈕,安裝完畢可以在 stable-diffusion-webui\extensions\ 路徑下看到名為 stable-diffusion-webui-wd14-tagger 的資料夾。
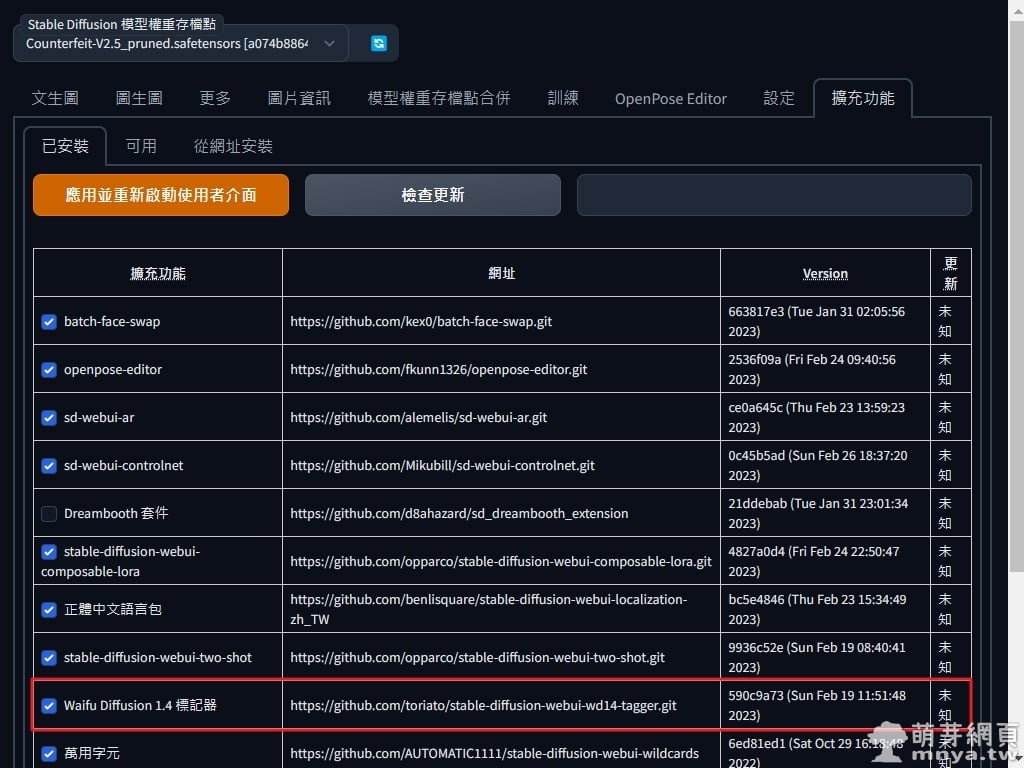
▲ 切到「已安裝」,可以看到「stable-diffusion-webui-wd14-tagger」(翻譯為「Waifu Diffusion 1.4 標記器」)已經安裝,未來可以在此檢查更新。這邊建議直接完全重新啟動 Stable Diffusion web UI,這樣就成功啟用該擴充功能囉!
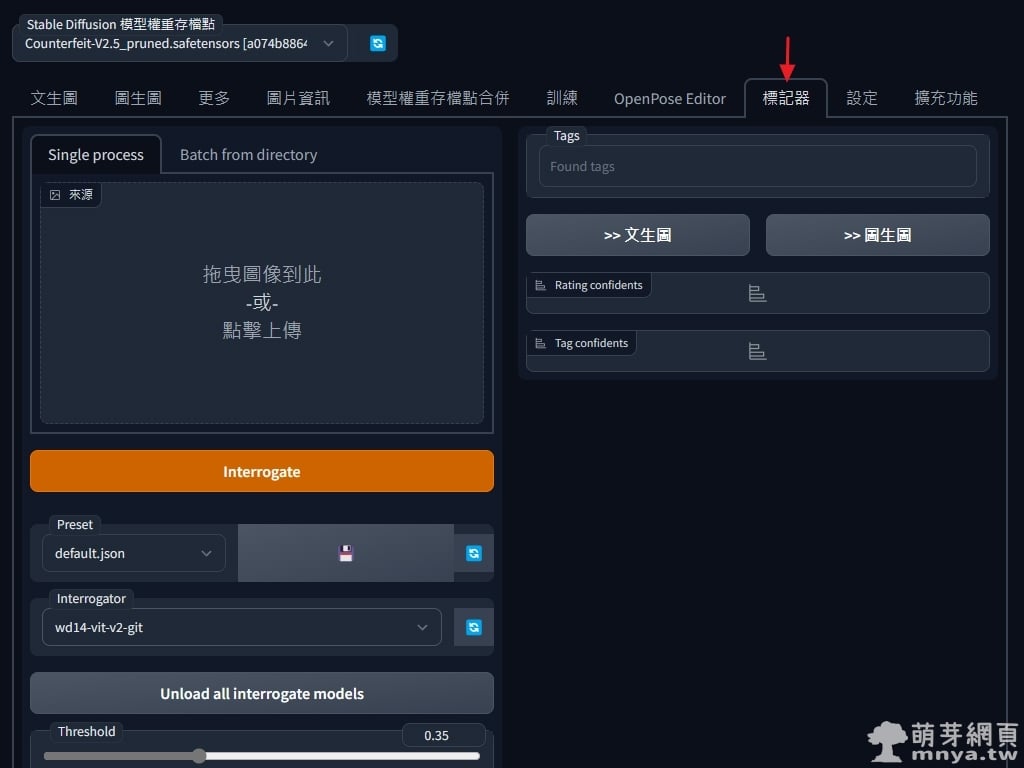
▲「stable-diffusion-webui-wd14-tagger」介面截圖一。
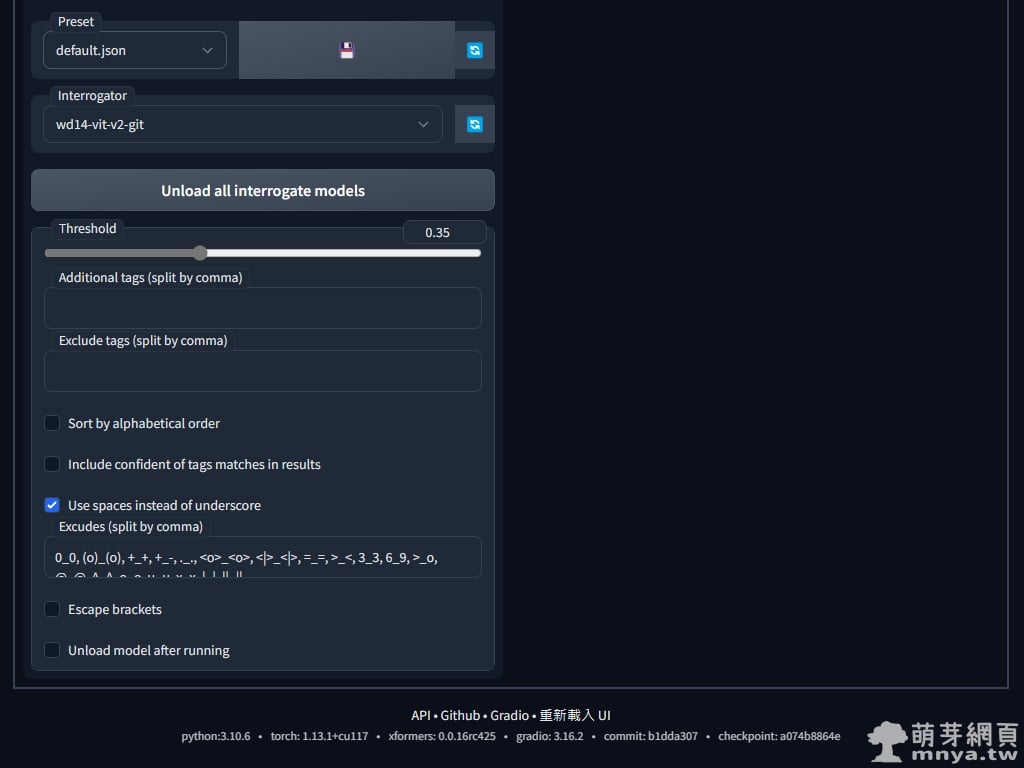
▲「stable-diffusion-webui-wd14-tagger」介面截圖二。
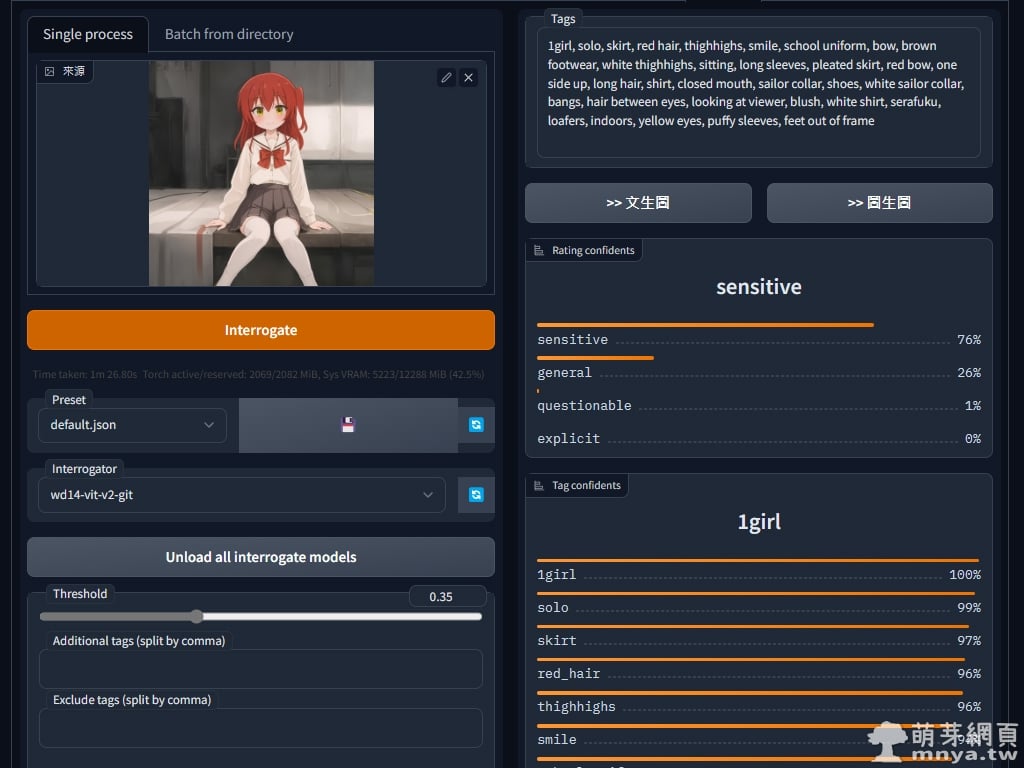
▲ 先來用看看單張影像反推,導入影像後,先用預設的 ViT 模型(Interrogator 那邊做設定)跑一次,Threshold 是設定可信度低於多少 % 剔除,預設為 35%,以前 DeepDanbooru 預設是低於 50% 的可信度就直接剔除,現在大家可以依照需求設定了!反推結果會在右側顯示。
輸出:1girl, solo, skirt, red hair, thighhighs, smile, school uniform, bow, brown footwear, white thighhighs, sitting, long sleeves, pleated skirt, red bow, one side up, long hair, shirt, closed mouth, sailor collar, shoes, white sailor collar, bangs, hair between eyes, looking at viewer, blush, white shirt, serafuku, loafers, indoors, yellow eyes, puffy sleeves, feet out of frame
※ 補充:首次執行會做以下動作,也就是將反推模型下載到本機。
Loading wd14-vit-v2-git model file from SmilingWolf/wd-v1-4-vit-tagger-v2
Downloading: 100%|██████████████████████████████████████████████████████████████████| 373M/373M [00:31<00:00, 11.7MB/s]
Downloading: 100%|███████████████████████████████████████████████████████████████████| 254k/254k [00:00<00:00, 287kB/s]
Installing onnxruntime
Loaded wd14-vit-v2-git model from C:\Users\user\.cache\huggingface\hub\models--SmilingWolf--wd-v1-4-vit-tagger-v2\snapshots\fab4cf71b7d2988e18ed3f40c17c1559e361c8f6\model.onnx
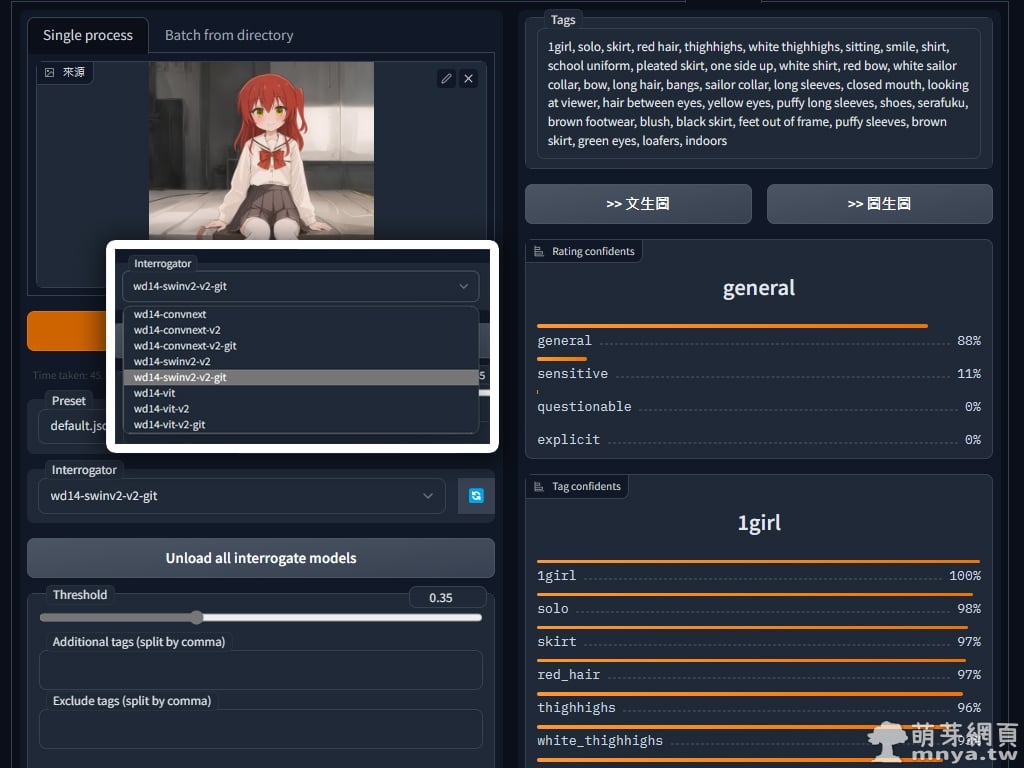
▲ 擴充提供了許多反推模型可供選擇,剛剛用的 ViT 速度較快,不過精準度較差,網上更推薦用 SwinV2,會比較吃 GPU 效能及記憶體,但精準度較高。
輸出:1girl, solo, skirt, red hair, thighhighs, white thighhighs, sitting, smile, shirt, school uniform, pleated skirt, one side up, white shirt, red bow, white sailor collar, bow, long hair, bangs, sailor collar, long sleeves, closed mouth, looking at viewer, hair between eyes, yellow eyes, puffy long sleeves, shoes, serafuku, brown footwear, blush, black skirt, feet out of frame, puffy sleeves, brown skirt, green eyes, loafers, indoors
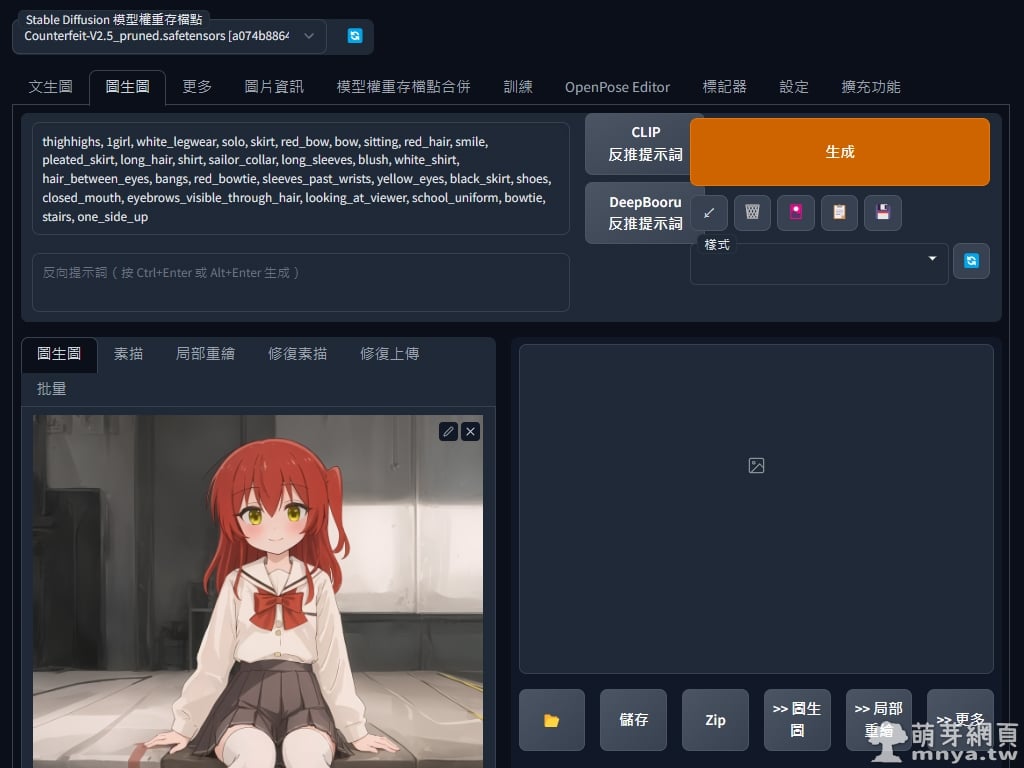
▲ 同張圖用以前常用的 DeepDanbooru 跑一次反推看看!
輸出:thighhighs, 1girl, white_legwear, solo, skirt, red_bow, bow, sitting, red_hair, smile, pleated_skirt, long_hair, shirt, sailor_collar, long_sleeves, blush, white_shirt, hair_between_eyes, bangs, red_bowtie, sleeves_past_wrists, yellow_eyes, black_skirt, shoes, closed_mouth, eyebrows_visible_through_hair, looking_at_viewer, school_uniform, bowtie, stairs, one_side_up
大家可以自行比較看看它們間的差異,選擇最適合自己的方式反推!
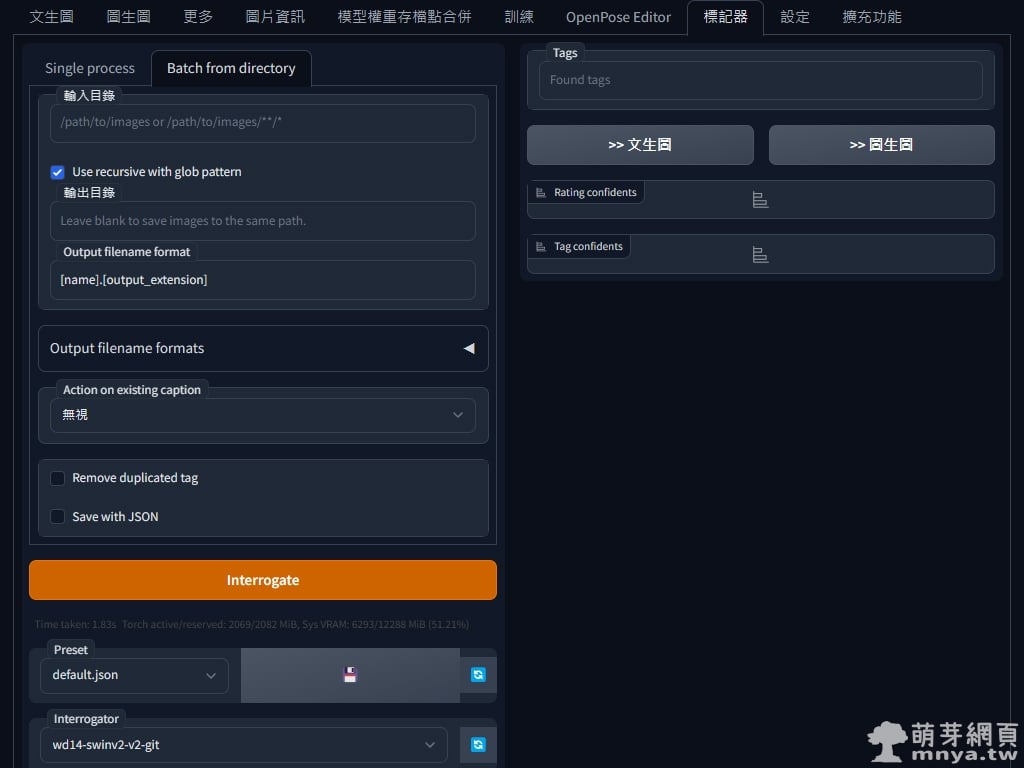
▲ 這個是批次反推的介面,設定好輸入輸出目錄等,就能批次反推影像了!輸入目錄要有影像檔喔!反推提詞會在輸出目錄建立的 TXT 內,每張影像一個 TXT 做對應。



 《上一篇》Metal-Slim ASUS Zenfone 8 ZS590KS 強化軍規防摔抗震手機殼
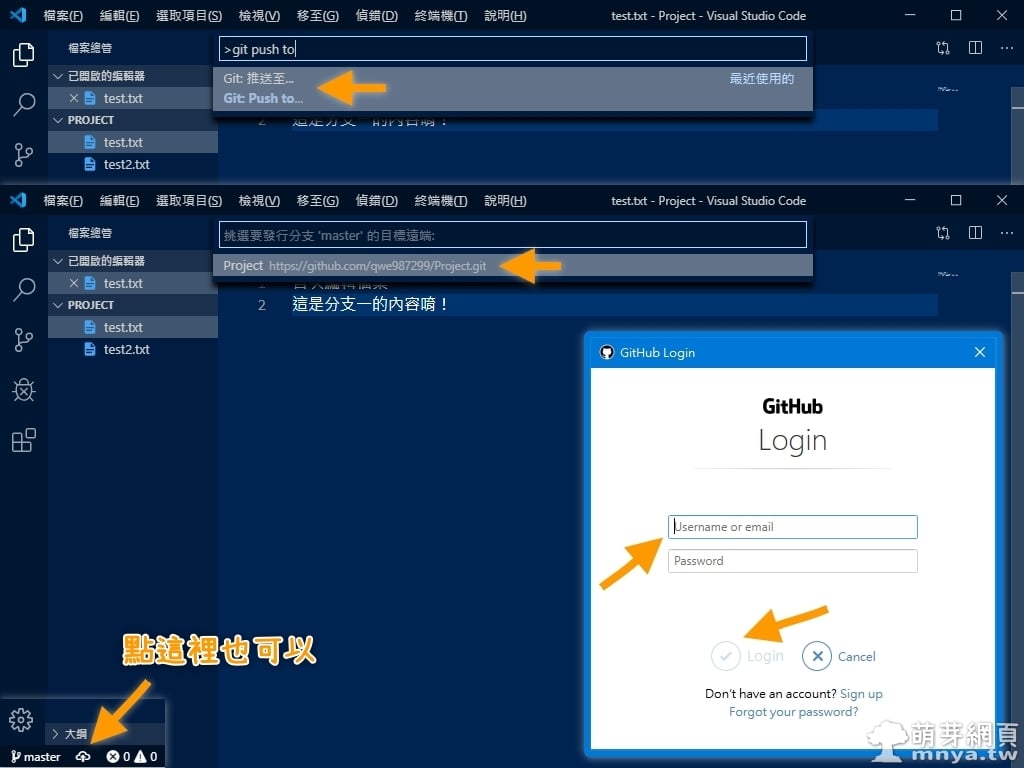
《上一篇》Metal-Slim ASUS Zenfone 8 ZS590KS 強化軍規防摔抗震手機殼 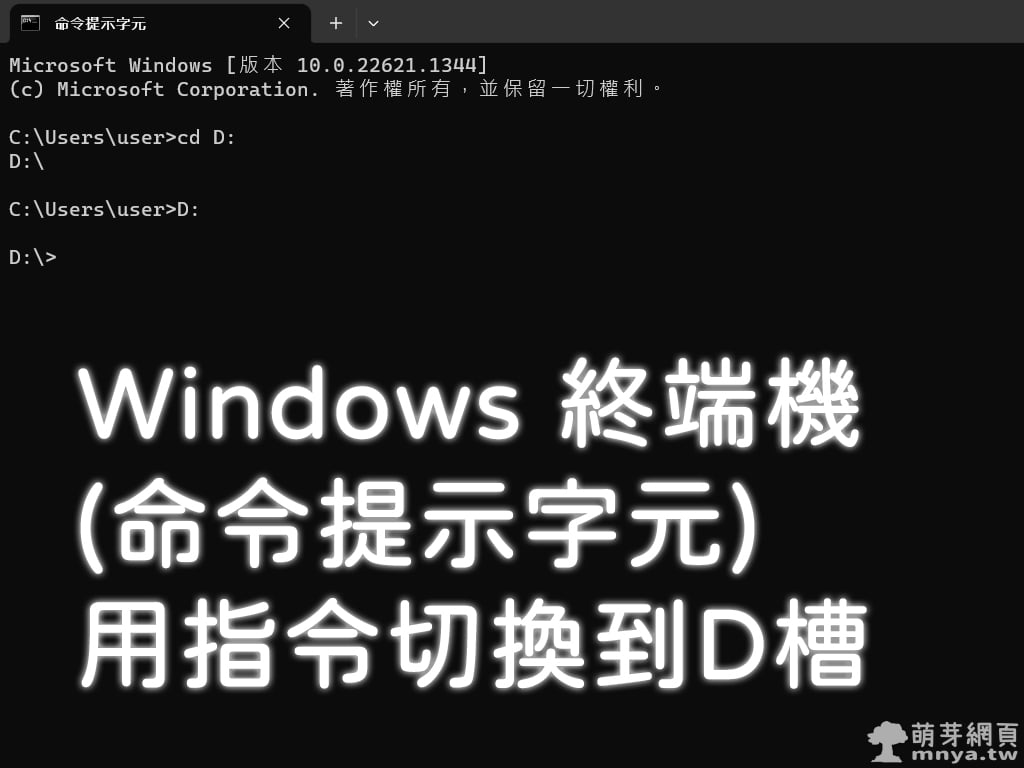 《下一篇》Windows:終端機(命令提示字元)用指令切換到D槽
《下一篇》Windows:終端機(命令提示字元)用指令切換到D槽 








留言區 / Comments
萌芽論壇