Layer-Divider 是一個 Stable Diffusion web UI 的擴充功能,搭配 SAM(Segment-Anything Model)實現圖像分層並可保存為 PSD 檔案,以利後續用 Photoshop 細修,過程中也能將人物順便做去背,另外可針對配件去調整顏色等,對於需要對 AI 繪圖影像做後製處理的人來說能節省不少時間。
🔗 Layer-Divider:https://github.com/jhj0517/stable-diffusion-webui-Layer-Divider
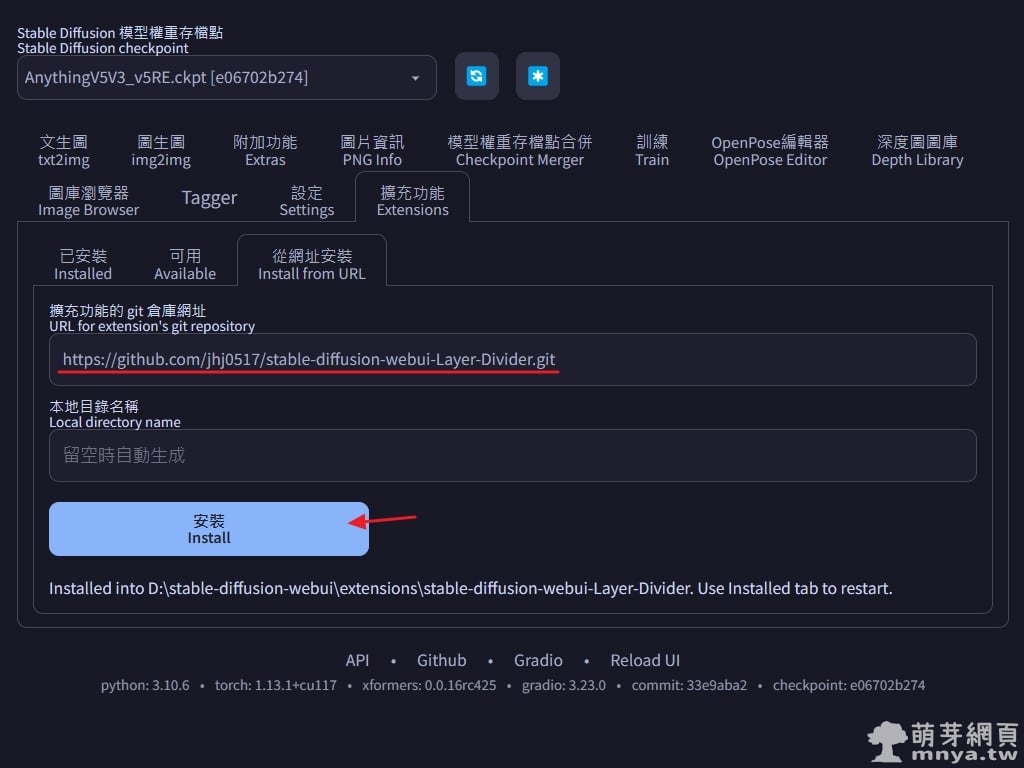
▲ 打開 Stable Diffusion web UI 切到「擴充功能」頁面,選「從網址安裝」,將擴充功能完整的 git 網址(即 https://github.com/jhj0517/stable-diffusion-webui-Layer-Divider.git )輸入進去再點「安裝」按鈕,安裝完畢可以在 stable-diffusion-webui\extensions\ 路徑下看到名為 stable-diffusion-webui-Layer-Divider 的資料夾。
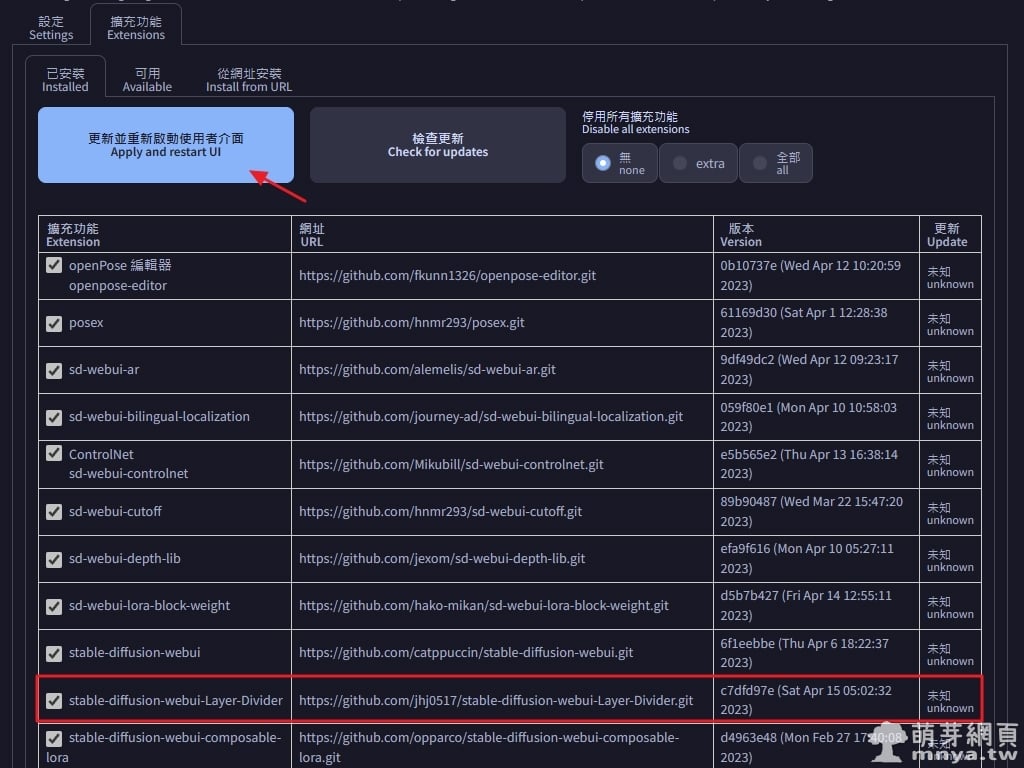
▲ 切到「已安裝」,可以看到「stable-diffusion-webui-Layer-Divider」已經安裝,未來可以在此檢查更新。點「更新並重新啟動使用者介面」,這樣就成功啟用該擴充功能囉!
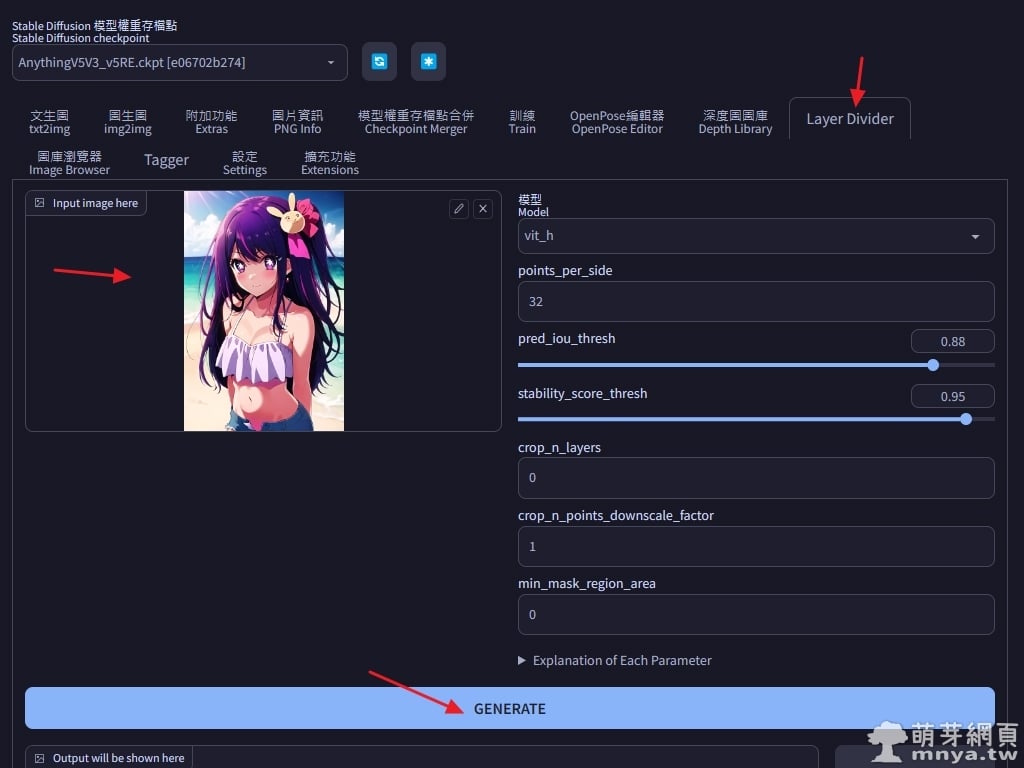
▲ 擴充啟用後會新增主頁籤「Layer Divider」,將圖像上傳上來後點「GENERATE」就可以開始進行分層了!首次處理都要等待下載相關 SAM 模型,右側可以選擇處理模型等參數,就先用預設值試一次!開發者提供的參數解釋如下:
points_per_side:沿圖像一側要採樣的點數。總點數為 points_per_side2。如果為 None,'point_grids' 必須提供明確的點採樣。 pred_iou_thresh:[0,1] 中的過濾閾值,使用模型預測的遮罩品質。
stability_score_thresh:[0,1] 中的過濾閾值,使用在二元化模型遮罩預測的截止值變化下遮罩的穩定性。
crops_n_layers:如果 > 0,將對圖像的裁剪再次進行遮罩預測。設置要運行的層數,其中每個層具有 2**i_layer 個圖像裁剪。
crop_n_points_downscale_factor:圖層 n 中採樣的邊界點數縮小了 crop_n_points_downscale_factor**n 倍。
min_mask_region_area:如果 > 0,將應用後處理以消除面積小於 min_mask_region_area 遮罩中的斷開區域和孔洞。需要 opencv。
※ 注意:我在首次處理遇上錯誤訊息,找尋 GitHub 上的問答時找到解決方式,需要進入 Web UI 的 Python 虛擬環境(參考教學)並重新安裝 pytoshop 依賴套件,完整操作指令如下:
cd 軟體根目錄(EX: D:\stable-diffusion-webui)
python -m venv venv
pip install pytoshop==1.1.0 -I --no-cache-dir
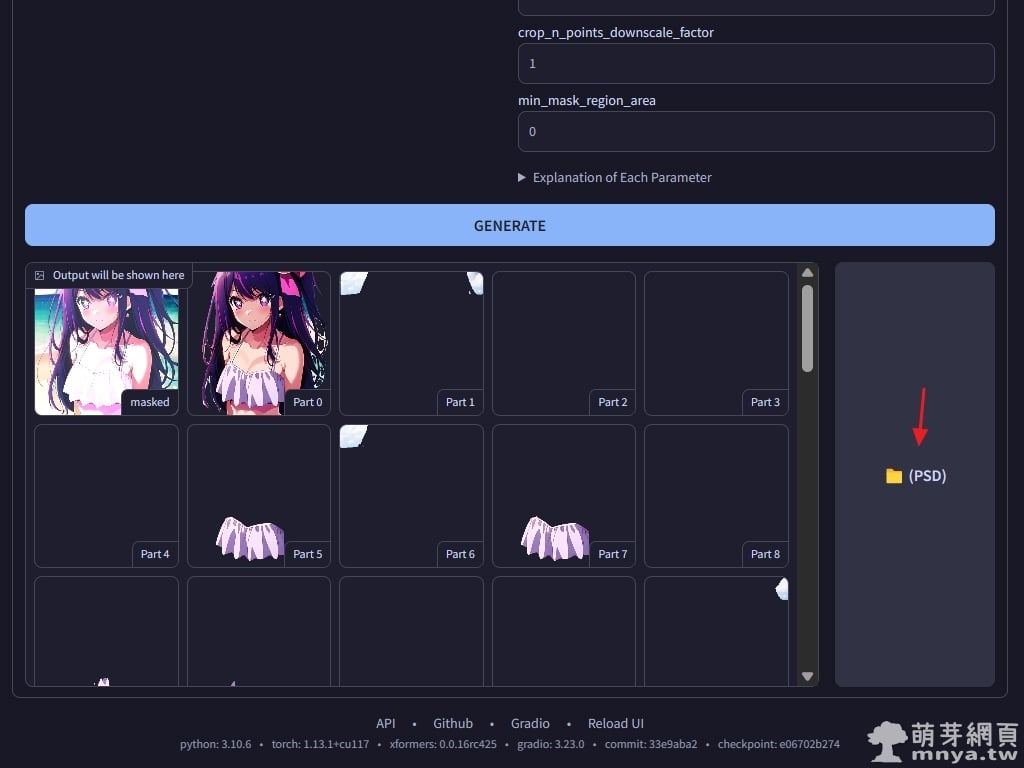
▲ 完成處理後各個分層預覽都會在下方顯示,可以點擊右方按鈕打開 PSD 檔案的存放位置(預設路徑為:stable-diffusion-webui\extensions\stable-diffusion-webui-Layer-Divider\layer_divider_outputs\psd)。
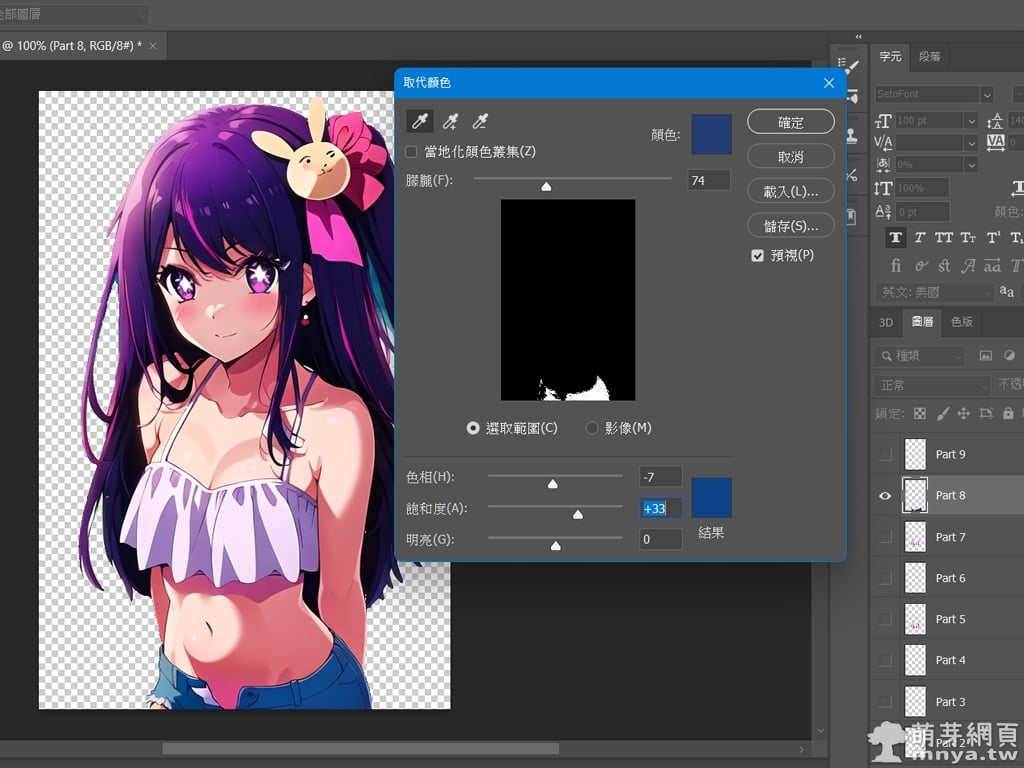
▲ 可以用 Photoshop 打開 PSD 檔案並做後製處理細修,很方便的工具。



 《上一篇》Stable Diffusion web UI x AnythingV5:AI 繪圖從零開始教學,無中生有的二次元女孩!
《上一篇》Stable Diffusion web UI x AnythingV5:AI 繪圖從零開始教學,無中生有的二次元女孩!  《下一篇》Stable Diffusion web UI x a1111-sd-webui-lycoris:使用 LyCORIS 模型 AI 生成影像!
《下一篇》Stable Diffusion web UI x a1111-sd-webui-lycoris:使用 LyCORIS 模型 AI 生成影像! 








留言區 / Comments
萌芽論壇