SD web UI 全稱 Stable Diffusion web UI,是本次要搭配 Stable-Diffusion-WebUI-TensorRT 擴充功能的 AI 繪圖工具。這款是 NVIDIA 官方推出的 SD web UI 擴充功能,可翻倍利用 NVIDIA RTX GPU 中的 Tensor Cores 並大量提升 Stable Diffusion 的效能。此 TensorRT 擴充套件支援文本轉圖像和圖像轉圖像、Stable Diffusion 1.5 和 2.1 及 LoRA,SDXL 的支援將在未來的更新中加入,最低系統需求如下:
GPU:搭載 8GB VRAM 的 NVIDIA RTX GPU
RAM:16GB RAM
網路連線:安裝期間需要網路連線
NVIDIA 驅動程式:NVIDIA Studio Driver 537.58、Game Ready Driver 537.58、NVIDIA RTX Enterprise Driver 537.58 及以上版本
一開始請先安裝好 SD web UI,之後連 TensorRT 擴充功能都安裝好後,只要為所需解析度生成 TensorRT 引擎,之後就能在相對應的參數下應用該引擎,以最高效率進行 AI 生成圖像。您可以生成多個引擎,以供需要時使用。擴充套件將自動使用可用的最佳引擎,因此您可以生成多個引擎,要注意每個引擎大小約為 2 GB。引擎有分靜態和動態。靜態引擎提供更好的性能,但只適用於其優化的精確參數設定。動態引擎會消耗更多 VRAM。生成引擎時,可以透過選擇「最小每批數量」、「最佳每批數量」、「最大每批數量」、「最小高度」、「最佳高度」、「最大高度」、「最小寬度」、「最佳寬度」、「最大寬度」、「最小提詞數量」、「最佳提詞數量」、「最大提詞數量」的設定選項來建立最符合需求的新引擎。詳細資訊及效能數據可以參考官方釋出的文件。
🔗 Stable-Diffusion-WebUI-TensorRT:https://github.com/NVIDIA/Stable-Diffusion-WebUI-TensorRT
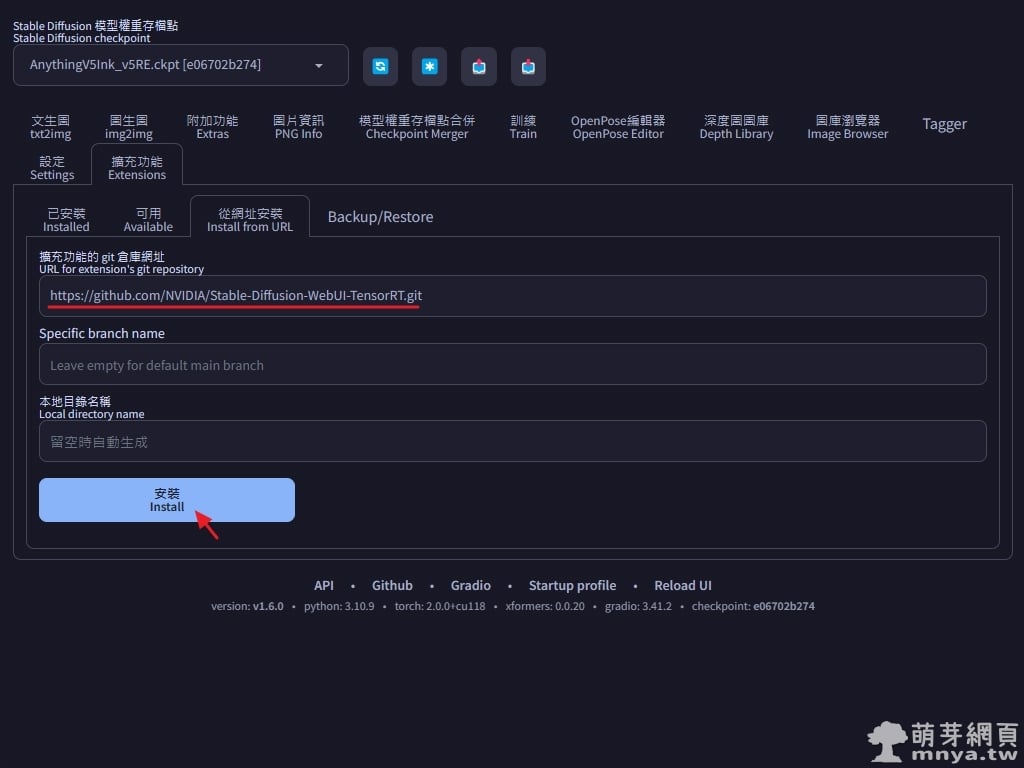
▲ 打開 Stable Diffusion web UI 切到「擴充功能」頁面,選「從網址安裝」,將擴充功能完整的 git 網址(即 https://github.com/NVIDIA/Stable-Diffusion-WebUI-TensorRT.git )輸入進去再點「安裝」按鈕,安裝完畢可以在 stable-diffusion-webui\extensions\ 路徑下看到名為 Stable-Diffusion-WebUI-TensorRT 的資料夾。
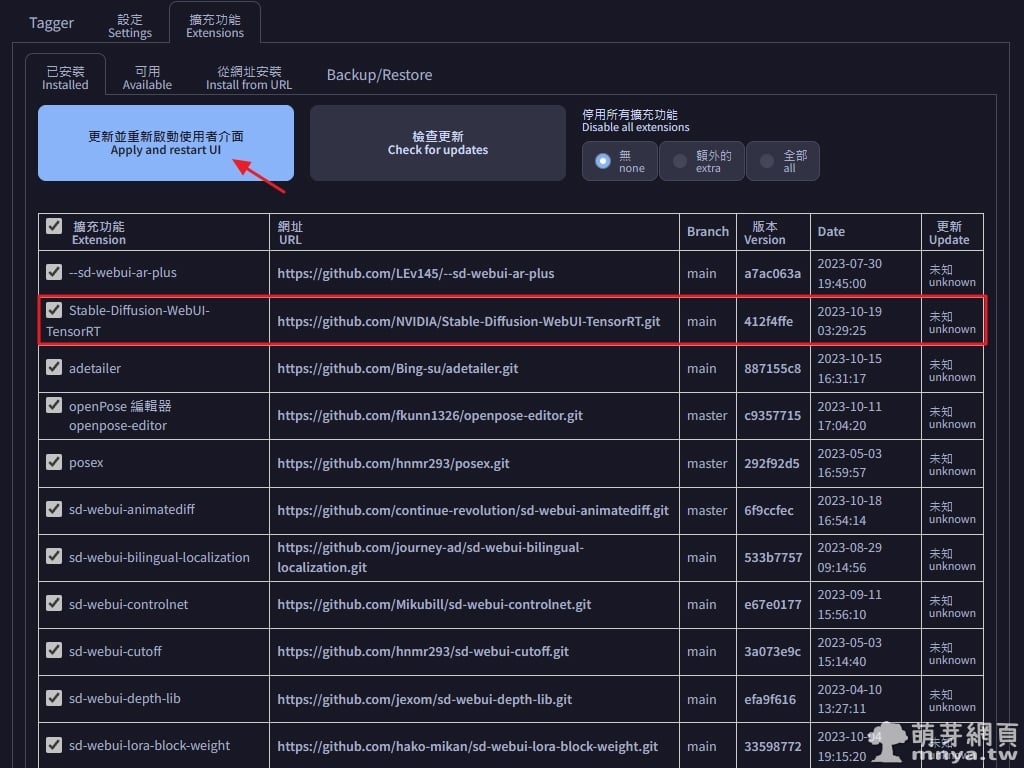
▲ 切到「已安裝」,可以看到「Stable-Diffusion-WebUI-TensorRT」已經安裝,未來可以在此檢查更新。點「更新並重新啟動使用者介面」,這樣就成功啟用該擴充功能囉!(若有遇上任何其他問題,請直接重新啟動 SD web UI 軟體終端視窗)
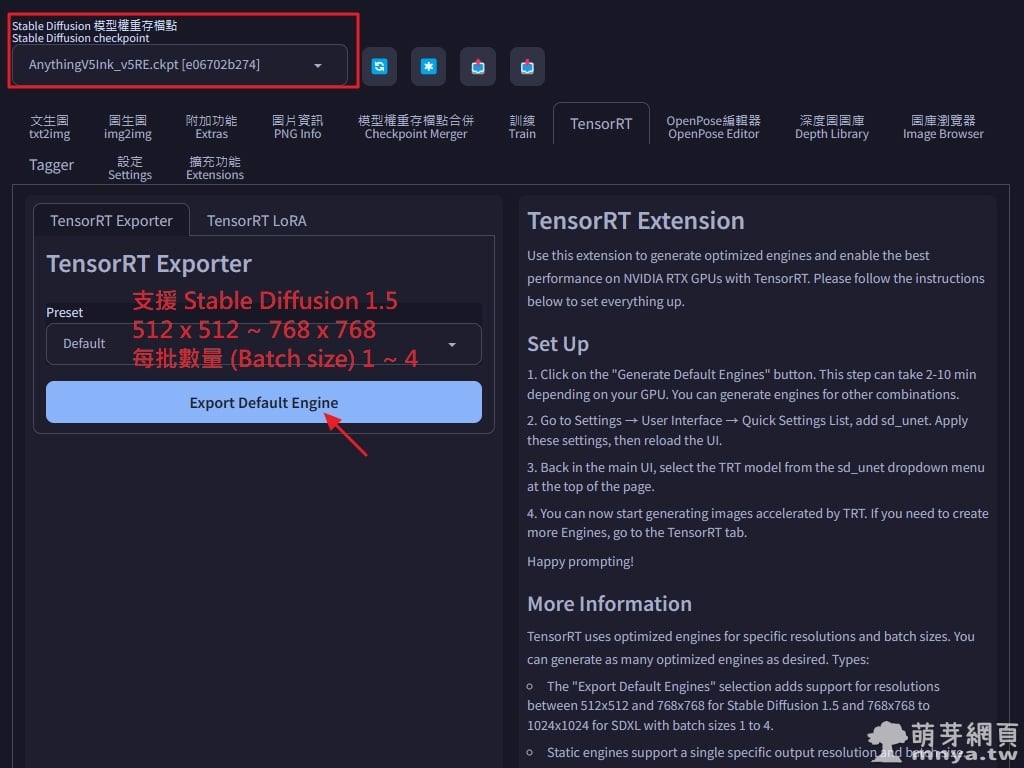
▲ 安裝成功後會出現「TensorRT」的選項卡,切過來後可以直接在「TensorRT Exporter」處用「Default」(預設)配置生成新引擎,預設的引擎為動態引擎,其範圍包括高度和寬度從 512 到 768,每批數量從 1 到 4。生成一個引擎大概要五分鐘或更久,這取決於您的硬體設備。注意!生成引擎前要先選好平常在使用的 Stable Diffusion 模型權重存檔點(Checkpoint)喔!擴充會針對該模型進行引擎生成。
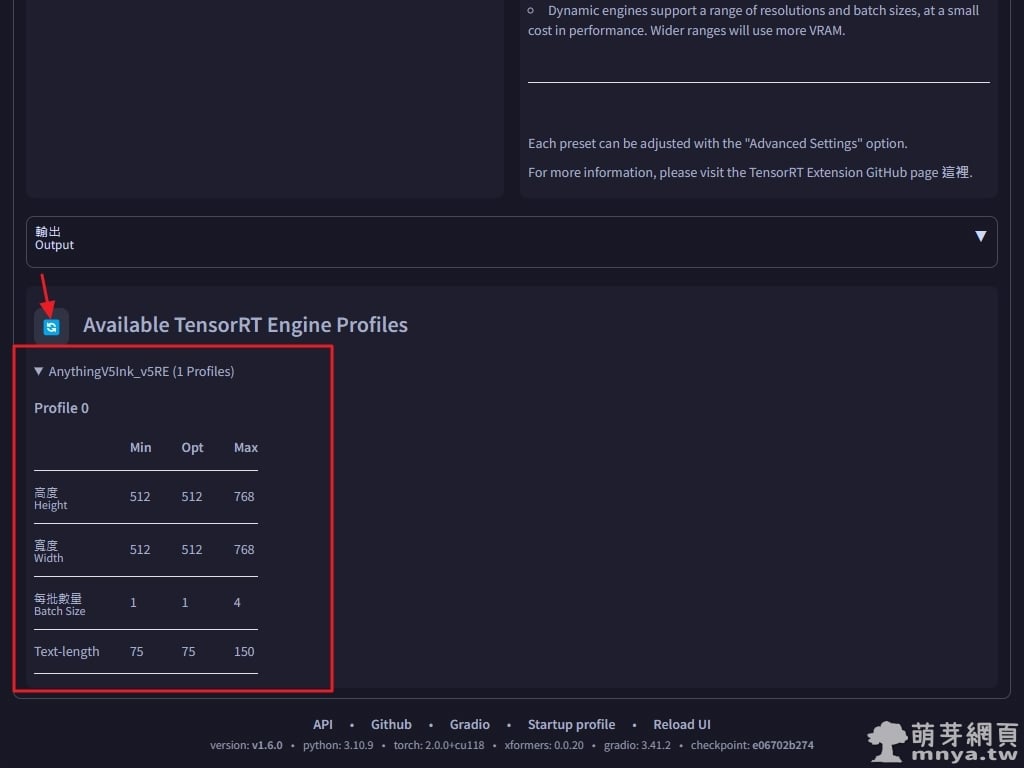
▲ 引擎成功生成後下方「Available TensorRT Engine Profiles」可以查看各引擎的細節,這個就是預設引擎的細節資訊。
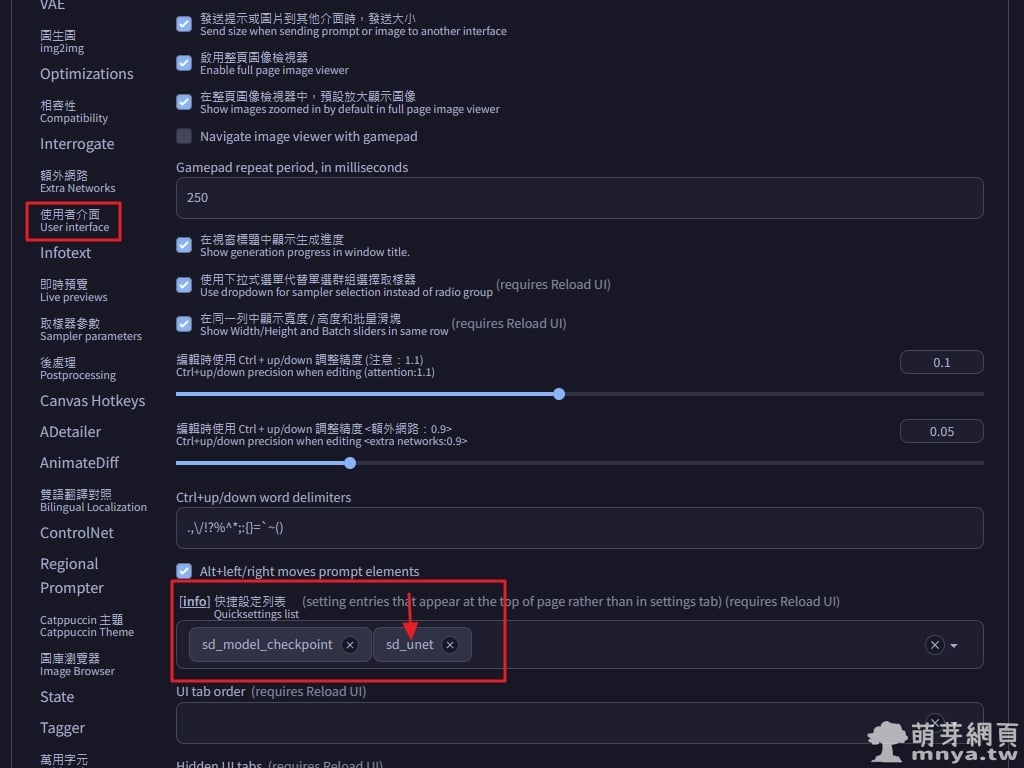
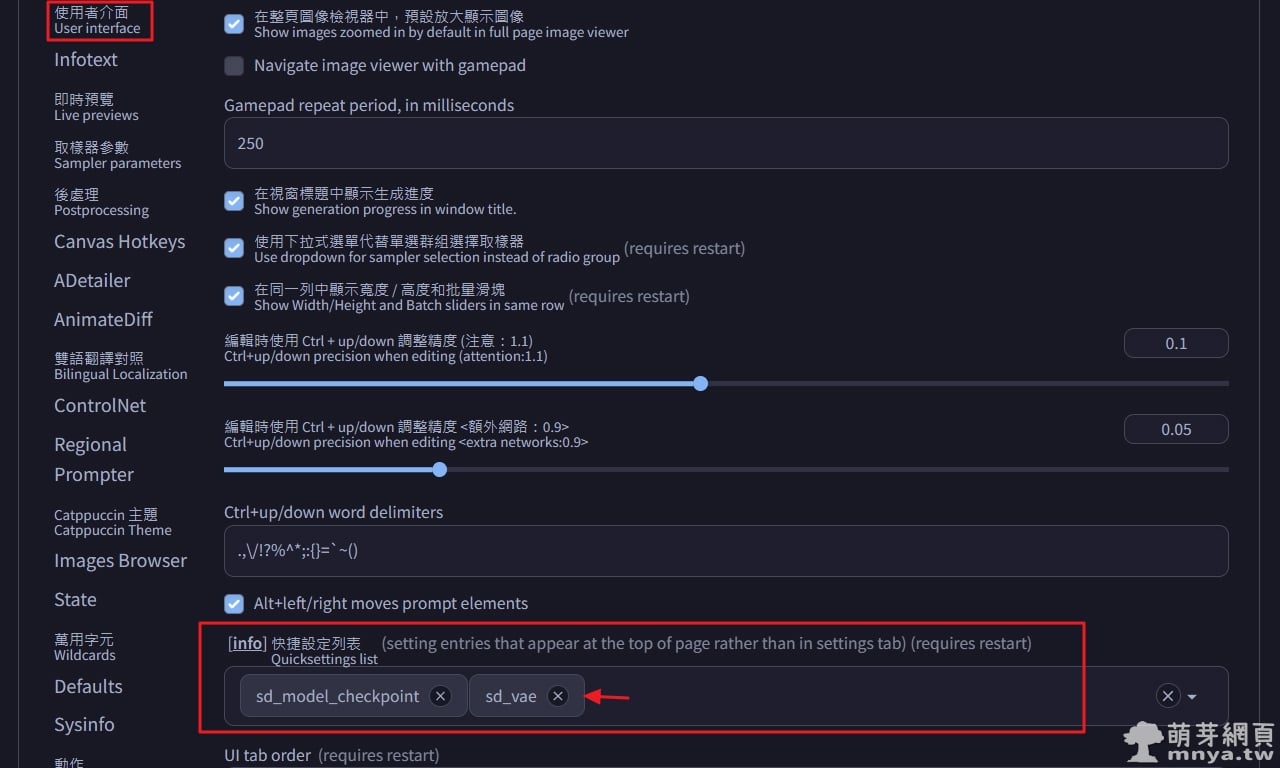
▲ 接著到「設定」→「使用者介面」→「快捷設定列表」,將「sd_unet」加入,到最上方點「套用設定」後點「重新載入 UI」。
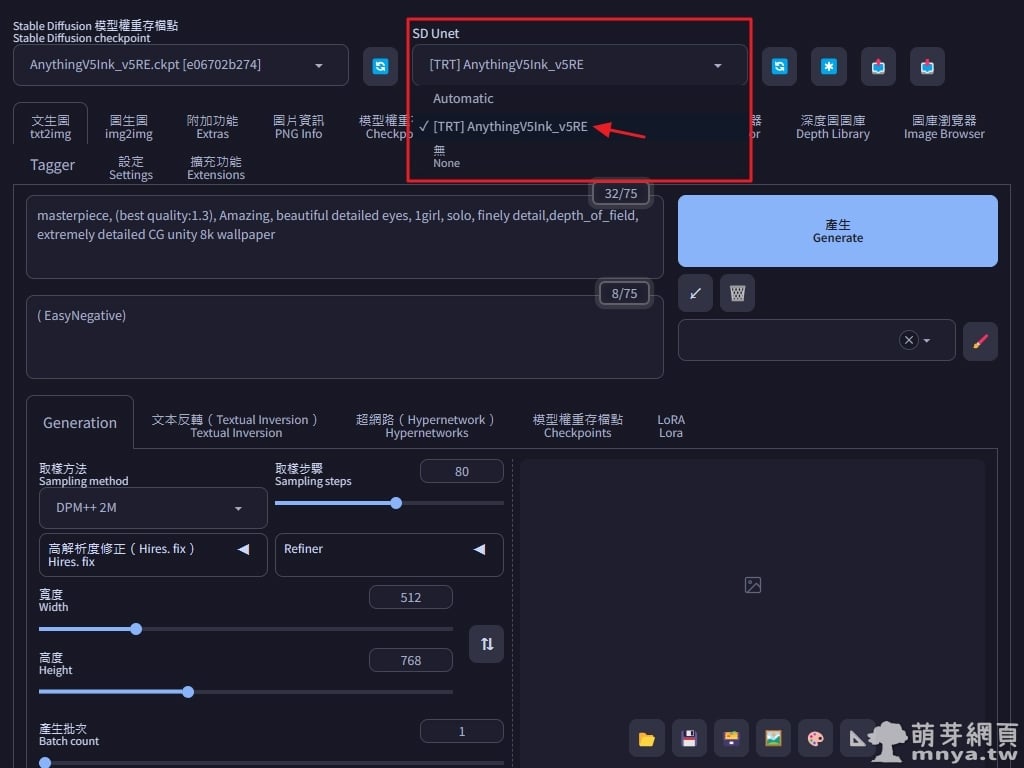
▲ 之後就能在最上方「SD Unet」選擇對應模型權重存檔點(Checkpoint)的 TRT 引擎,接著擴充就會再找最適合目前參數的引擎來進行生成。若找不到合適的,則會顯示以下錯誤訊息:
ValueError: No valid profile found. Please go to the TensorRT tab and generate an engine with the necessary profile. If using hires.fix, you need an engine for both the base and upscaled resolutions. Otherwise, use the default (torch) U-Net.
意思就是找不到有效的引擎。需要前往 TensorRT 選項卡並生成需要的引擎。如果使用 hires.fix 功能,您需要一個用於基本解析度和升級解析度的引擎。否則,請使用預設 (torch) U-Net!
如果需要刪除引擎,無法從 UI 上進行,需要手動至 stable-diffusion-webui\models\Unet-trt 處刪除指定的 .trt 檔案,另外也需要修改 model.json 內相對應的資料。
以下提供一個使用 RTX 3070 Laptops GPU 的生成輸出對照,讓大家看看效能的不同!這邊統一使用 Anything V5 模型(直接文生圖,無使用 LoRA 模型),取樣方式為 DPM++ 2M,大小 512 x 768 px,有用到 ADetailer,應用預設動態引擎來優化效能。
預設 (torch) U-Net 引擎
100%|██████████████████████████████████████████████████████████████████████████████████| 80/80 [00:15<00:00, 5.29it/s]
Total progress: 100%|██████████████████████████████████████████████████████████████████| 80/80 [00:14<00:00, 5.31it/s]
0: 640x448 1 face, 13.2ms
Speed: 4.9ms preprocess, 13.2ms inference, 4.0ms postprocess per image at shape (1, 3, 640, 448)
100%|██████████████████████████████████████████████████████████████████████████████████| 33/33 [00:06<00:00, 5.32it/s]
Total progress: 100%|██████████████████████████████████████████████████████████████████| 80/80 [00:24<00:00, 3.27it/s]
Total progress: 100%|██████████████████████████████████████████████████████████████████| 80/80 [00:24<00:00, 5.31it/s]
TensorRT 預設動態引擎
Activating unet: [TRT] AnythingV5Ink_v5RE
Loading TensorRT engine: C:\stable-diffusion-webui\models\Unet-trt\AnythingV5Ink_v5RE_2986849f_cc86_sample=1x4x64x64+2x4x64x64+8x4x96x96-timesteps=1+2+8-encoder_hidden_states=1x77x768+2x77x768+8x154x768.trt
[I] Loading bytes from C:\stable-diffusion-webui\models\Unet-trt\AnythingV5Ink_v5RE_2986849f_cc86_sample=1x4x64x64+2x4x64x64+8x4x96x96-timesteps=1+2+8-encoder_hidden_states=1x77x768+2x77x768+8x154x768.trt
Profile 0:
sample = [(1, 4, 64, 64), (2, 4, 64, 64), (8, 4, 96, 96)]
timesteps = [(1,), (2,), (8,)]
encoder_hidden_states = [(1, 77, 768), (2, 77, 768), (8, 154, 768)]
latent = [(-1945979547), (-1945980577), (-1945989120)]
100%|██████████████████████████████████████████████████████████████████████████████████| 80/80 [00:09<00:00, 8.80it/s]
Total progress: 100%|██████████████████████████████████████████████████████████████████| 80/80 [00:08<00:00, 9.01it/s]
0: 640x448 1 face, 11.5ms
Speed: 1.5ms preprocess, 11.5ms inference, 2.0ms postprocess per image at shape (1, 3, 640, 448)
100%|██████████████████████████████████████████████████████████████████████████████████| 33/33 [00:03<00:00, 8.95it/s]
Total progress: 100%|██████████████████████████████████████████████████████████████████| 80/80 [00:15<00:00, 5.14it/s]
Total progress: 100%|██████████████████████████████████████████████████████████████████| 80/80 [00:15<00:00, 9.01it/s]

 《上一篇》Windows 11:永久停用 Windows Update 自動更新
《上一篇》Windows 11:永久停用 Windows Update 自動更新  《下一篇》HitPaw 影片修復軟體:AI 驅動,進行影片畫質修復、影片解析度調整!
《下一篇》HitPaw 影片修復軟體:AI 驅動,進行影片畫質修復、影片解析度調整! 








留言區 / Comments
萌芽論壇