Stable Diffusion web UI 的「文生圖」(txt2img)有個可勾選的「高解析度修復」(Highres. fix)功能,這個是做什麼用的呢?它真的能讓生成的圖更好嗎?您可能需要了解一下它的運作原理才會知道這個問題的答案,不過我的答案會是「不一定」,但它應該能幫助您減少輸出高解析度影像的失敗率。個人摸索後是這樣的結論 ... 我們都知道 Stable Diffusion 第一版是基於 512 x 512 px 解析度的訓練集,後續衍生出來的模型基本上也是以這個解析度為基礎進行訓練的,所以只要設定寬或高其中一項之輸出超過這個解析度的兩倍(含)以上我會視為是輸出高解析度影像,這時候 AI 運算過程就會出現比較得不合理現象,如:身體扭曲、景物重複、買一送一(一個人變成兩個人)、兩個上半身、兩顆頭等。
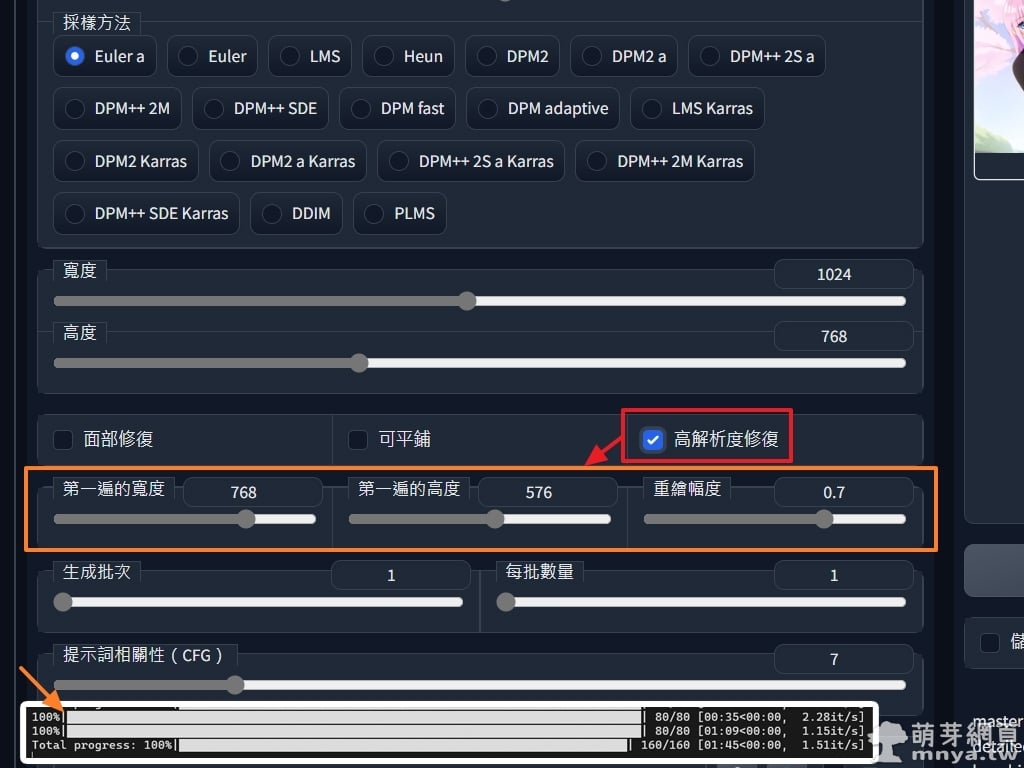
▲ 運用「高解析度修復」這個功能,AI 會先用同樣的參數輸出一個較小尺寸的圖,這是自行設定的,項目名稱是「第一遍的寬度」和「第一遍的高度」,比例建議不要跟輸出的不一樣,不然最終結果會被裁切!再來是選擇其重繪幅度,預設為 0.7,一樣可自行修改,接著會再用這張小圖作為基礎,以同樣參數運算大圖以指定重繪幅度加強上去(跟圖生圖的概念差不多),能減少 AI 爆走的機率,減少高解析度影像輸出失敗率。但由於要跑兩次,生成一張圖等於要花原來約 150% 左右的時間,因為中間多生一張小圖了!(終端機會顯示總步數等資訊,看了就知道了,然後那張小圖不會被輸出喔!)

▲ 來試試前陣子熱門動畫的角色「式守」同學,模型、參數等通通一樣,連種子碼都固定,我直接輸出一張 768 x 576(4:3)的影像。

▲ 接著我再將「高解析度修復」打勾,設定如上上張圖那樣,先讓它生成 768 x 576 小圖為基礎,來生成 1024 x 768(4:3)的高解析度影像,由於重繪幅度為 0.7,所以可以看出兩張圖構圖很接近。



 《上一篇》ChatGPT:AI 預測式聊天機器人、透過自然語言生成技術來回答用戶的問題
《上一篇》ChatGPT:AI 預測式聊天機器人、透過自然語言生成技術來回答用戶的問題 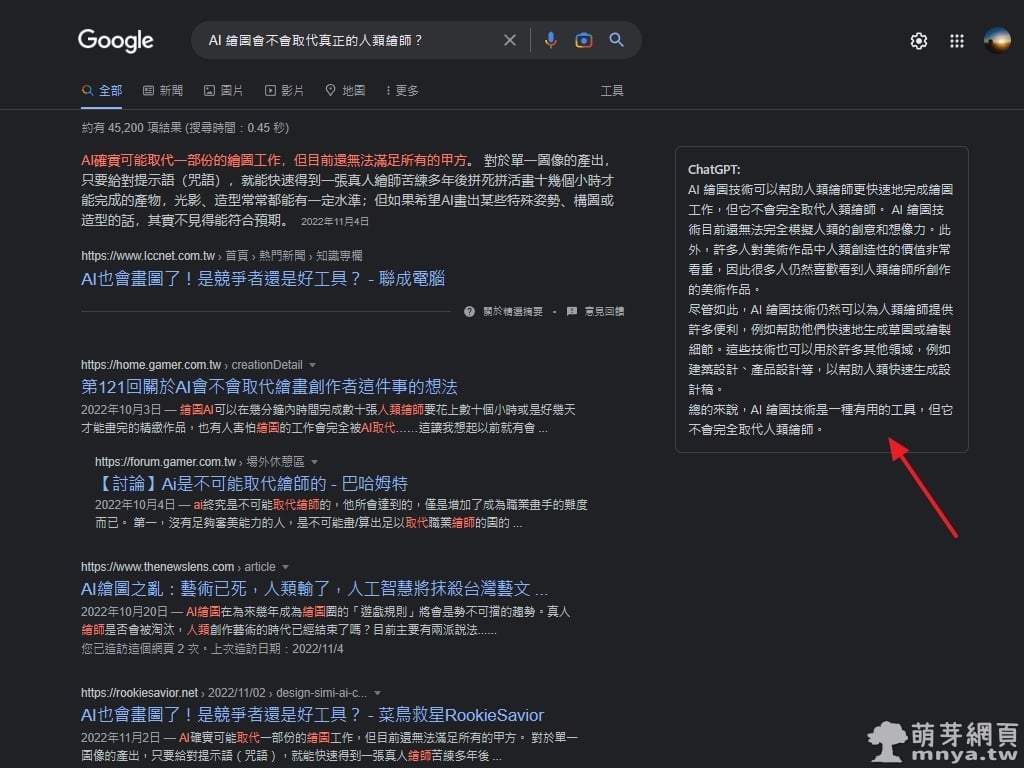 《下一篇》ChatGPT for Google:在搜尋引擎結果旁邊顯示 ChatGPT 的回應
《下一篇》ChatGPT for Google:在搜尋引擎結果旁邊顯示 ChatGPT 的回應 








留言區 / Comments
萌芽論壇